
开场段子 :
记得当年我查到高考分数后, 第一件事不是告诉父母,而是飞快地跑到学校。
找到班主任,指着她说: “哼哼,你不是说以我的智商不可能考上一本的吗?”
班主任一脸尴尬地向我道歉。
我气愤地说: “还真被你这个乌鸦嘴说中了!”
全国名校众多,最常听说的是“985工程”高校、“211工程”高校。除此之外还有“双一流”高校的说法,这是在2017年提出来的。在这里我们介绍“211”高校。
何为211高校
“211”工程,即面向21世纪、重点建设100所左右的高等学校和一批重点学科的建设工程,新中国成立以来由国家立项在高等教育领域进行的规模最大、层次最高的重点建设工作,是中国政府实施“科教兴国”战略的重大举措,211大学在社会上认可度也极高。
由于当时各大高校之间竞争激烈,虽说只是100所,但是到了今天已经发展成了116所,目前已经不接受申报了。
这些211高校包括39所985高校,以及另外77所高校。可以分成6个梯队。
第一梯度为前五的清华大学、北京大学、复旦大学、浙江大学、上海交通大学。
第二梯度为前二十的“985”高校,分别是中国科学技术大学、中国人民大学、南京大学、同济大学、南开大学、北京航空航天大学、北京师范大学、武汉大学、西安交通大学、天津大学、华中科技大学、北京理工大学、东南大学、中山大学、华东师范大学、哈尔滨工业大学、厦门大学、中南大学、华南理工大学、电子科技大学。
第三梯度为其他十三所高校以及国防科技大学。它们分别是西北工业大学、大连理工大学、四川大学、吉林大学、湖南大学、重庆大学、山东大学、中国农业大学、中国海洋大学、中央民族大学、东北大学、兰州大学、西北农林科技大学。
以上为39所985高校,同时它们也是211高校。
第四梯度的有上海财经大学、中央财经大学、对外经济贸易大学、北京外国语大学、中国政法大学、北京邮电大学、上海外国语大学、西南财经大学、中国传媒大学、中南财经政法大学、南京航空航天大学、北京科技大学、北京交通大学、华东理工大学、西安电子科技大学、天津医科大学、南京理工大学、华中师范大学、哈尔滨工程大学、华北电力大学、北京中医药大学、暨南大学、苏州大学、武汉理工大学。
第五梯度的有中国药科大学、东华大学、河海大学、北京林业大学、河北工业大学、北京工业大学、江南大学、北京化工大学、西南交通大学、上海大学、南京师范大学、中国地质大学(武汉)、中国地质大学(北京)、西北大学、东北师范大学、长安大学、中国矿业大学(北京)、华中农业大学、合肥工业大学、广西大学、中国石油大学(华东)、陕西师范大学、南京农业大学。
第六梯度的有湖南师范大学、福州大学、大连海事大学、西南大学、中国矿业大学、云南大学、太原理工大学、华南师范大学、北京体育大学、中国石油大学(北京)、安徽大学、东北林业大学、东北农业大学、辽宁大学、南昌大学、延边大学、内蒙古大学、四川农业大学、海南大学、贵州大学、郑州大学、新疆大学、宁夏大学、石河子大学、青海大学、中央音乐学院、西藏大学、第二军医大学、第四军医大学。
那么这116所211大学都在哪里呢?我们用Python动态图来盘点一下吧!
先上图片
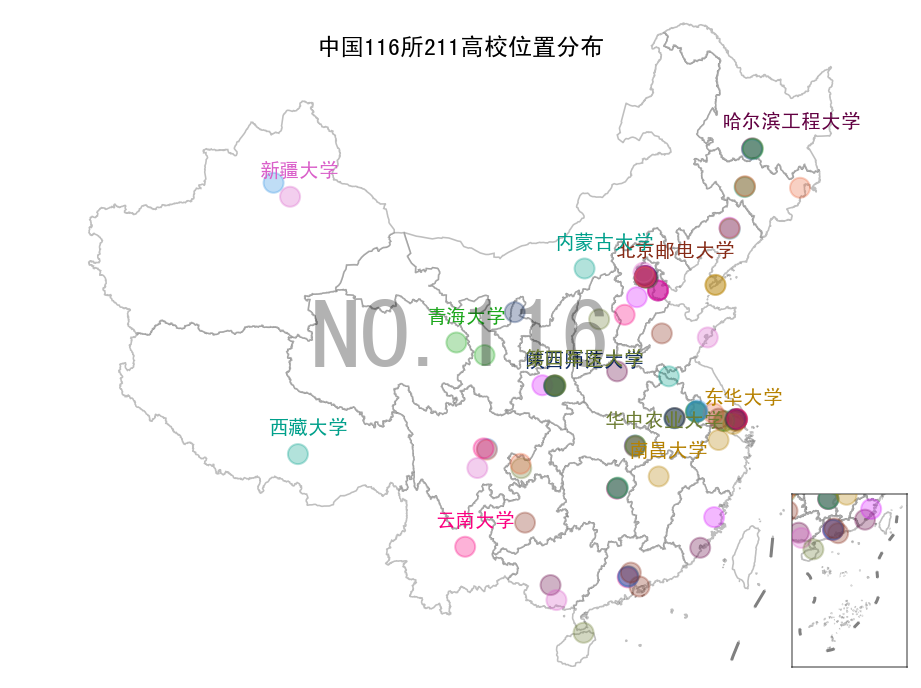
再上视频
最后上代码
import numpy as np
import pandas as pd
import geopandas as gpd
import shapely
from shapely import geometry as geo
from shapely import wkt
import geopandas as gpd
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import contextily as ctx
import imageio
import os
from PIL import Image
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['animation.writer'] = 'html'
plt.rcParams['animation.embed_limit'] = 100
def rgba_to_rgb(img_rgba):
img_rgb = Image.new("RGB", img_rgba.size, (255, 255, 255))
img_rgb.paste(img_rgba, mask=img_rgba.split()[3])
return img_rgb
def html_to_gif(html_file, gif_file, duration=0.5):
path = html_file.replace(".html","_frames")
images = [os.path.join(path,x) for x in sorted(os.listdir(path))]
frames = [imageio.imread(x) for x in images]
if frames[0].shape[-1]==4:
frames = [np.array(rgba_to_rgb(Image.fromarray(x))) for x in frames]
imageio.mimsave(gif_file, frames, 'gif', duration=duration)
return gif_file
cmap = [
'#2E91E5',
'#1CA71C',
'#DA16FF',
'#B68100',
'#EB663B',
'#00A08B',
'#FC0080',
'#6C7C32',
'#862A16',
'#620042',
'#DA60CA',
'#0D2A63']*100
def getCoords(geom):
if isinstance(geom,geo.MultiPolygon):
return [np.array(g.exterior) for g in geom.geoms]
elif isinstance(geom,geo.Polygon):
return [np.array(geom.exterior)]
elif isinstance(geom,geo.LineString):
return [np.array(geom)]
elif isinstance(geom,geo.MultiLineString):
return [np.array(x) for x in list(geom.geoms)]
else:
raise Exception("geom must be one of [polygon,MultiPolygon,LineString,MultiLineString]!")
#底图数据
dfprovince = gpd.read_file("./data/dfprovince.geojson").set_crs("epsg:4326").to_crs("epsg:2343")
dfnanhai = gpd.read_file("./data/dfnanhai.geojson").set_crs("epsg:4326").to_crs("epsg:2343")
dfline9 = dfnanhai[(dfnanhai["LENGTH"]>1.0)&(dfnanhai["LENGTH"]<2.0)]
#散点数据
df985 = gpd.read_file("./data/中国985大学.geojson").set_crs("epsg:4326").to_crs("epsg:2343")
df211 = gpd.read_file("./data/中国211大学.geojson").set_crs("epsg:4326").to_crs("epsg:2343")
dfpoints = pd.concat([df985,df211],axis = 0)
df = pd.DataFrame({"x":[pt.x for pt in dfpoints["geometry"]],
"y": [pt.y for pt in dfpoints["geometry"]]})
df["z"] = 1.0
df.index = dfpoints["name"].values
def bubble_map_dance(df,title = "中国116所211高校位置分布",
filename = None,
figsize = (8,6),dpi = 144,
duration = 0.5,
anotate_points = ["北京邮电大学","南昌大学","华中农业大学","东华大学","云南大学",
"陕西师范大学","内蒙古大学","西藏大学","新疆大学","青海大学","哈尔滨工程大学"]):
fig, ax_base =plt.subplots(figsize=figsize,dpi=dpi)
ax_child=fig.add_axes([0.800,0.125,0.10,0.20])
def plot_frame(i):
ax_base.clear()
ax_child.clear()
#============================================================
#绘制底图
#============================================================
#绘制省边界
polygons = [getCoords(x) for x in dfprovince["geometry"]]
for j,coords in enumerate(polygons):
for x in coords:
poly = plt.Polygon(x, fill=True, ec = "gray", fc = "white",alpha=0.5,linewidth=.8)
poly_child = plt.Polygon(x, fill=True, ec = "gray", fc = "white",alpha=0.5,linewidth=.8)
ax_base.add_patch(poly)
ax_child.add_patch(poly_child )
#绘制九段线
coords = [getCoords(x) for x in dfline9["geometry"]]
lines = [y for x in coords for y in x ]
for ln in lines:
x, y = np.transpose(ln)
line = plt.Line2D(x,y,color="gray",linestyle="-.",linewidth=1.5)
line_child = plt.Line2D(x,y,color="gray",linestyle="-.",linewidth=1.5)
ax_base.add_artist(line)
ax_child.add_artist(line_child)
#设置spine格式
for spine in['top','left',"bottom","right"]:
ax_base.spines[spine].set_color("none")
ax_child.spines[spine].set_alpha(0.5)
ax_base.axis("off")
#设置绘图范围
bounds = dfprovince.total_bounds
ax_base.set_xlim(bounds[0]-(bounds[2]-bounds[0])/10, bounds[2]+(bounds[2]-bounds[0])/10)
ax_base.set_ylim(bounds[1]+(bounds[3]-bounds[1])/3.5, bounds[3]+(bounds[3]-bounds[1])/100)
ax_child.set_xlim(bounds[2]-(bounds[2]-bounds[0])/2.5, bounds[2]-(bounds[2]-bounds[0])/20)
ax_child.set_ylim(bounds[1]-(bounds[3]-bounds[1])/20, bounds[1]+(bounds[3]-bounds[1])/2)
#移除坐标轴刻度
ax_child.set_xticks([]);
ax_child.set_yticks([]);
#============================================================
#绘制散点
#============================================================
k = i//3+1
m = i%3
text = "NO."+str(k)
dfdata = df.iloc[:k,:].copy()
dftmp = df.iloc[:k-1,:].copy()
# 绘制散点图像
if len(dftmp)>0:
ax_base.scatter(dftmp["x"],dftmp["y"],s = 100*dftmp["z"]/df["z"].mean(),
c = (cmap*100)[0:len(dftmp)],alpha = 0.3,zorder = 3)
ax_child.scatter(dftmp["x"],dftmp["y"],s = 100*dftmp["z"]/df["z"].mean(),
c = (cmap*100)[0:len(dftmp)],alpha = 0.3,zorder = 3)
# 添加注释文字
for i,p in enumerate(dftmp.index):
px,py,pz = dftmp.loc[p,["x","y","z"]].tolist()
if p in anotate_points:
ax_base.annotate(p,xy = (px,py), xycoords = "data",xytext = (-15,10),
fontsize = 10,fontweight = "bold",color = cmap[i], textcoords = "offset points")
# 添加标题和排名序号
#ax_base.set_title(title,color = "black",fontsize = 12)
ax_base.text(0.5, 0.95, title, va="center", ha="center",
size = 12,transform = ax_base.transAxes)
ax_base.text(0.5, 0.5, text, va="center", ha="center",
alpha=0.3, size = 50,transform = ax_base.transAxes)
# 添加注意力动画
if m==0:
px,py,pz = dfdata["x"][[-1]],dfdata["y"][[-1]],dfdata["z"][-1]
p = dfdata.index[-1]
ax_base.scatter(px,py,s = 800*pz/df["z"].mean(),
c = cmap[len(dfdata)-1:len(dfdata)],alpha = 0.5,zorder = 4)
ax_base.annotate(p,xy = (px,py), xycoords = "data",
xytext = (-15,10),fontsize = 20,fontweight = "bold",
color = cmap[k-1], textcoords = "offset points",zorder = 5)
if m==1:
px,py,pz = dfdata["x"][[-1]],dfdata["y"][[-1]],dfdata["z"][-1]
p = dfdata.index[-1]
ax_base.scatter(px,py,s = 400*pz/df["z"].mean(),
c = cmap[len(dfdata)-1:len(dfdata)],alpha = 0.5,zorder = 4)
ax_base.annotate(p,xy = (px,py), xycoords = "data",
xytext = (-15,10),fontsize = 15,fontweight = "bold",
color = cmap[k-1], textcoords = "offset points",zorder = 5)
if m==2:
px,py,pz = dfdata["x"][[-1]],dfdata["y"][[-1]],dfdata["z"][-1]
p = dfdata.index[-1]
ax_base.scatter(px,py,s = 100*pz/df["z"].mean(),
c = cmap[len(dfdata)-1:len(dfdata)],alpha = 0.5,zorder = 4)
ax_base.annotate(p,xy = (px,py), xycoords = "data",
xytext = (-15,10),fontsize = 10,fontweight = "bold",
color = cmap[k-1], textcoords = "offset points",zorder = 5)
my_animation = animation.FuncAnimation(fig,plot_frame,frames = range(0,3*len(df)),interval = int(duration*1000))
if filename is None:
try:
from IPython.display import HTML
HTML(my_animation.to_jshtml())
return HTML(my_animation.to_jshtml())
except ImportError:
pass
else:
my_animation.save(filename)
return filename
html_file = "中国116所211高校位置分布.html"
bubble_map_dance(df,filename = html_file)
gif_file = html_file.replace(".html",".gif")
html_to_gif(html_file,gif_file,duration=0.5)
收工。
**-----**------**-----**---**** End **-----**--------**-----**-****
往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/hEaMbA5dCmafxkV19_eA5g,如有侵权,请联系删除。













