专栏作者:霖hero,在职爬虫工程师,熟悉JS逆向与分布式爬虫。喜欢钻研,热爱学习,乐于分享。公众号后台回复入群,拉你进技术群与大佬们近距离交流。
01
前言

大家好,我是J哥🚀
在以前的文章中我们学了Ajax数据爬取,这篇文章我们以今日头条为例,通过分析Ajax请求来抓取今日头条的街拍美图,并将图片下载到本地保存下来。准备好没,我们现在开始!
02
网页分析

在抓取之前,首先分析抓取的逻辑。打开今日头条的街拍美图https://so.toutiao.com/search?dvpf=pc&source=input&keyword=%E8%A1%97%E6%8B%8D,如下图:
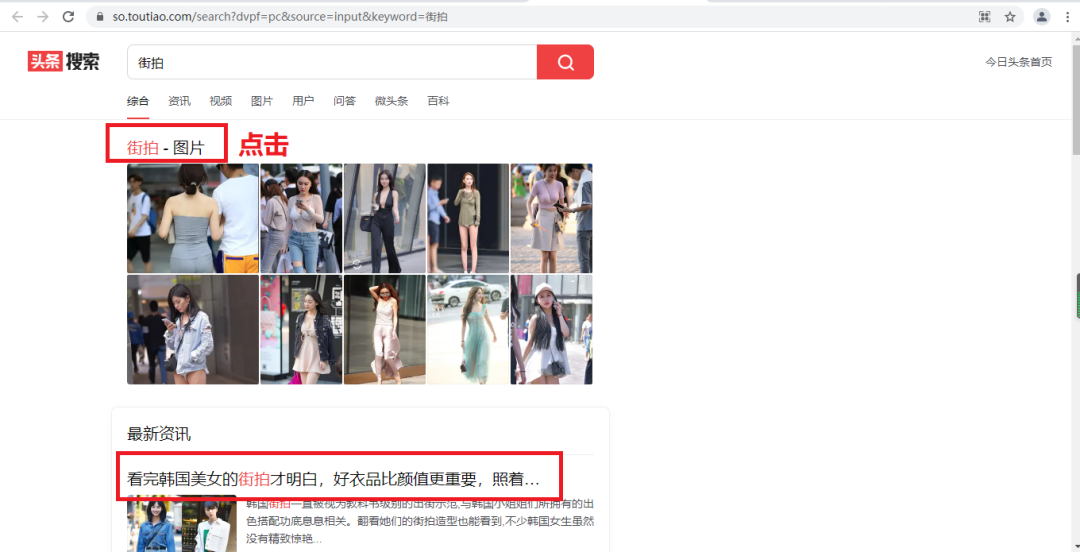
我们点击第一个,这个请求的URL是:

随后我们打开开发者工具,切换到Network选项卡,重新刷新页面并下滑,可以发现这里出现了很多的条目,点击‘search?keyword=%’开头的条目,可以发现里面有很多图片信息的数据,其中img_small_url、img_url是图片链接,如下图:
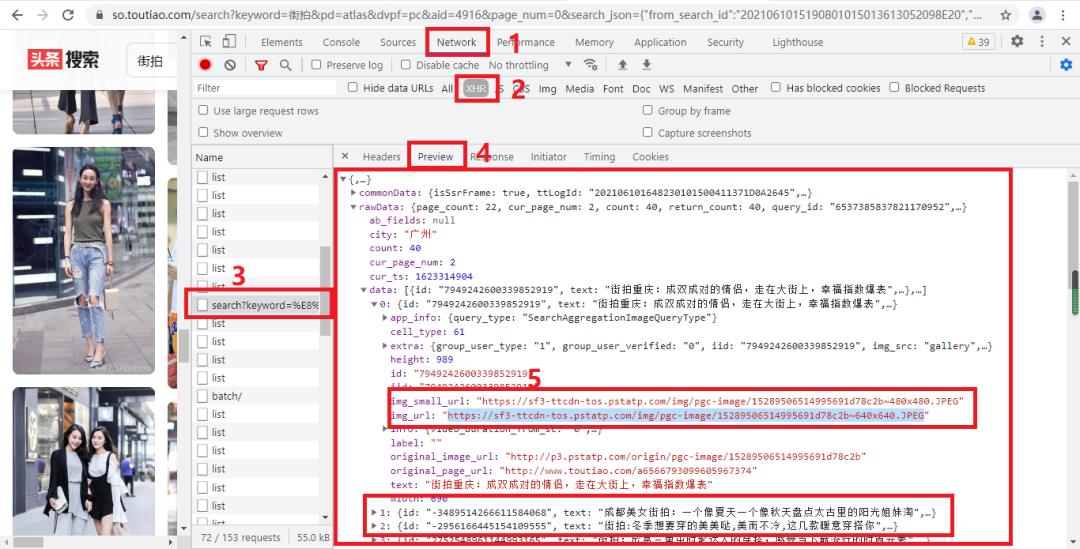
我们只需要用Python来模拟这个Ajax请求,然后提取相关美图链接并下载下来就可以了,但是在这之前,我们还需要分析一下URL的规律。
切换回Headers选项卡,观察一下它的请求URL和Headers信息,如下图:
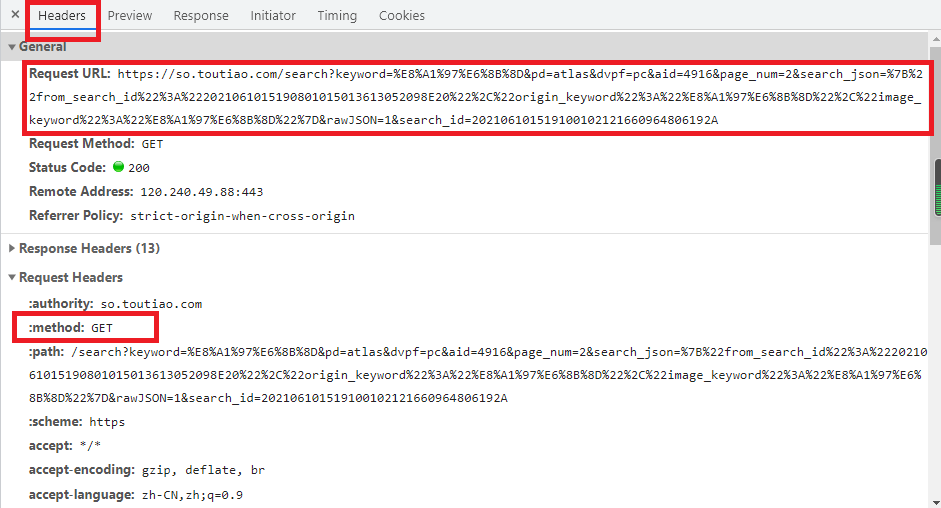
可以看到,这是一个GET请求,请求URL的参数有keyword、pd、dvpf、aid、page_num、search_json、rawJSON、search_id。我们需要找到这些参数的规律,这样才可以方便地用程序构造出来。
接下来,滑动页面,多加载一些新结果。在加载的同时可以发现,Network中又出现了许多Ajax请求。如下图:
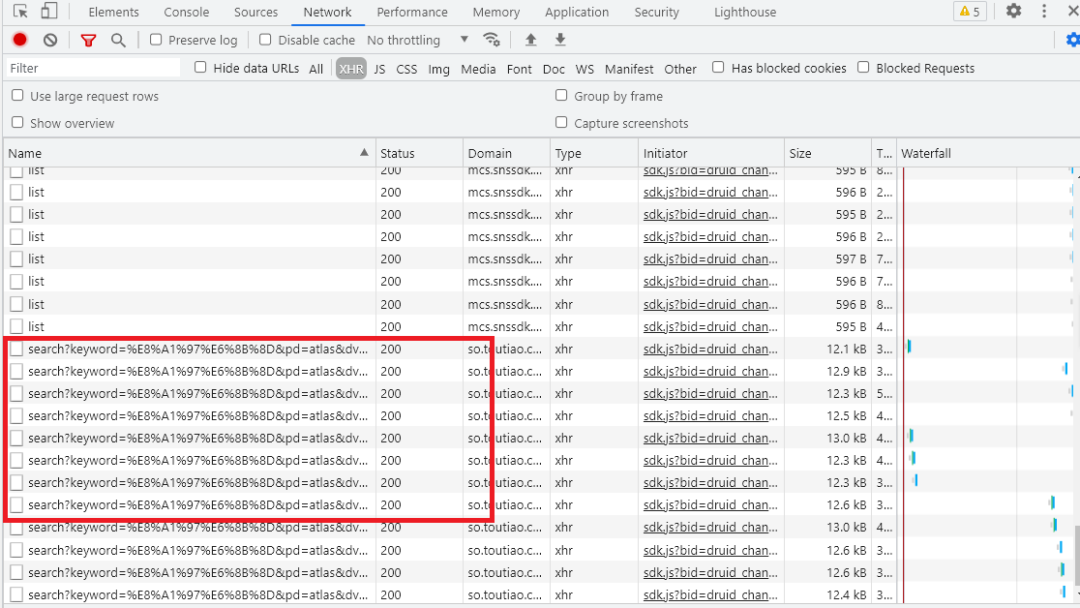
观察后续链接的参数,可以发现发生变化的参数只有page_num,其他参数都没有变化,而且page_num的偏移量为1,因此我们可以用page_num参数来控制数据分页,这样一来,我们就可以通过接口批量获取数据了,然后将数据解析,将图片下载下来即可。
03
爬虫实战

定义一个get_page()方法,实现加载单个Ajax请求的结果。其中唯一变化的参数就是page_num,所以我们将它当作参数传递,实现代码如下:
def get_page(page_num):
global headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
}
params = {
'keyword':urllib.parse.unquote('%E8%A1%97%E6%8B%8D'),
'pd':'atlas',
'dvpf':'pc',
'aid':4916,
'page_num':page_num,
'search_json':'%7B%22from_search_id%22%3A%22202106100003510102121720341003A4ED%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id':'202106100004290101500200495C05B763'
}
url='https://so.toutiao.com/search?'+urlencode(params)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code==200:
return response.json()
except requests.ConnectionError:
return None这里我们用urlencode()方法构造请求的GET参数,然后用requests请求这个链接,如果返回状态码为200,则调用response的json()方法将结果转为JSON格式,然后返回。
接下来,再实现一个解析方法:提取每条数据的img_url字段的图片链接,将图片链接返回,此时我们通过构造器来实现,实现代码如下:
def get_images(json):
images=json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link接下来,实现一个保存图片的方法saving_images(),其中link是前面get_images()方法返回的图片链接,实现代码如下:
def saving_img(link):
global name
print(f'-------正在打印第{name}张图片')
data=requests.get(link,headers=headers).content
with open(f'image1/{name}.jpg','wb')as f:
f.write(data)
name+=1最后,只需要构造一个page_num数组,遍历page_num,提取图片链接,并将其下载即可,具体代码如下:
def main(paga_num):
json=get_page(paga_num)
for link in get_images(json):
saving_img(link)
if __name__ == '__main__':
for i in range(0,2):
main(i)这样整个程序就完成了,运行之后可以发现街拍美图保存下载下来了,这里我们只遍历了两个page_num,爬取了80张图片,如下图:
04
小结

好了,Python爬虫——今日头条街拍美图的爬取就讲解到这里,感谢观看!当然,该程序仍有很多可以完善的地方,例如:使用多进程的进程池来实现多进程下载。
**-----**------**-----**---**** End **-----**--------**-----**-****
往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/hFd-2_0OzaWFuxLlVok4mg,如有侵权,请联系删除。