
关键词:NVIDIA、MIG、安培
一 什么是 MIG
2020年5月,NVIDIA 发布了最新的 GPU 架构: 安培,以及基于安培架构的最新的 GPU : A100。安培提供了许多新的特性,MIG 是其中一项非常重要的新特性。MIG的全名是 Multi-Instance GPU。 NVIDIA安培架构中的MIG模式可以在A100 GPU上并行运行七个作业。多实例 GPU (MIG) 可提升每个 NVIDIA A100 Tensor 核心 GPU 的性能和价值。MIG 可将 A100 GPU 划分为多达七个实例,每个实例均与各自的高带宽显存、缓存和计算核心完全隔离。现在,管理员可以支持从大到小的各项工作负载,为每项工作提供规模适当的 GPU,而且服务质量 (QoS) 稳定可靠,从而优化利用率,让每位用户都能享用加速计算资源。

二 MIG技术分析 在 MIG 推出之前,我们也能够透过 CUDA MPS (Multi-Process Service) 来提高 GPU 使用率。但 MPS 的缺点在于,多个使用者会使用共同的内存,因此使用者的程序会互相影响,除了无法保证推理的速度和吞吐量之外,也有可能因为其中一位使用者的程序出错而导致其他使用者受到干扰。而 MIG 克服了 MPS 面临的问题。MIG 藉由硬件上的分离,保证了使用者的程序不会互相干扰,进而能够让程序的时延和吞吐量能符合预期。
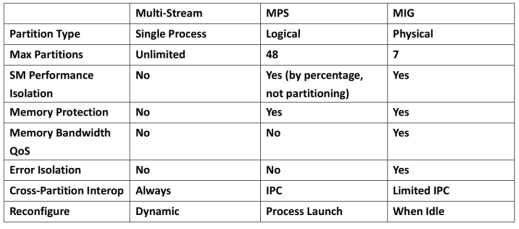
在表格 1当中,我们比较了多流 (multi-stream)、MPS 以及 MIG 的优缺点。其中,多流的使用限制较少,同时也很灵活,但对代码更动的需求大,并且无法避免使用者之间的互相干扰,使用者必须小心的使用以避免产生错误。MPS 则不需要更动代码即可使用,可以同时执行的程序也较 MIG 多 (48 与 7),内存的使用与分配也是自动处理的,不需要人工的介入。缺点在于,无法避免多个用户对于 GPU 资源的竞争;最后,MIG 虽然可以同时执行的程序数量最少,但和 MPS 一样不需要使用者另外更动代码,同时在安全性与可靠性上面也是三者中最佳的。这三样技术并不互相冲突,使用者可以根据使用的情境与场景选择与搭配使用。
表一
借助 MIG,工作可同时在不同的实例上运行,每个实例都有专用的计算、显存和显存带宽资源,从而实现可预测的性能,同时符合服务质量并尽可能提升 GPU 利用率。
在MIG模式下的A100可以运行多达7个不同大小的AI或HPC工作负载的任意组合。这种能力对于通常不需要现代GPU所提供的所有性能的AI推理工作特别有用。
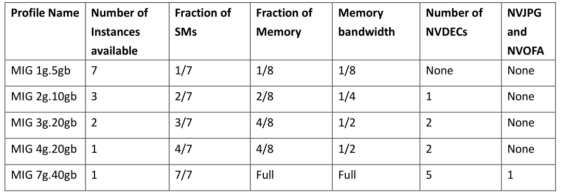
例如,用户可以创建两个MIG实例,每个实例的内存为20gb,三个实例的内存为10gb,七个实例的内存为5gb。用户创建适合其工作负载的组合。
如何计算最大可建实例的数量呢?以A100 40GB显存为例,A100一张卡的SM单元(streaming multiprocessor)数量(类似CPU的核心数)为108,每14个SM单元称作一个Slice,每张A100卡有7个Slice。一个GPU运算实例的最小粒度是14个SM单元,也就是说在分配GPU的SM单元数量时必须是14的整数倍。如果申请规模为28 SM单元数,10GB显存的运算实例,设在单张A100上这样的实例个数最多为X个,那么必须满足28 * X <= 108(SM单元总数限制) 且 10 *X <= 40(GPU显存限制),所以X最大为3。
表二
MIG隔离了GPU实例,所以它提供了故障隔离,一个实例中的问题不会影响在同一物理GPU上运行的其他实例。每个实例都提供有保证的QoS,确保用户的工作负载获得他们期望的延迟和吞吐量。
表三比较了上一代旗舰产品V100与A100使用7个MIG GPU实例在FasterTransformer模型中不同batch size下的吞吐量与时延。我们可以看到在batch size为8的时候,A100的吞吐量已经很接近峰值,距离峰值不到百分之十;另一方面,V100在batch size 为8的时候,吞吐量距离峰值还有百分之三十左右,在batch size 为32时,吞吐量距离峰值也还有百分之十左右。这代表和上一代的GPU相比,MIG在提升GPU的使用率上有很大的进步。
表三

当在A100上配置MIG mode的时候,需要考虑如下限制: 1)MIG只支持Linux操作系统, CUDA11/ R450 or更高版本。(推荐至少要使用过450.80.02或更高版本) 2)支持bare-metal (包括容器); 支持Linux guest通过hypervisor进行GPU pass-through 可视化;支持vGPU模式; 3)在A100上设置MIG,需要GPU reset和超级用户权限(super-user privileges)。一旦A100设置了MIG后,instance的管理就可以是动态的了(无需再进行GPU reset).需要注意这一点是针对单个GPU而言,不是对单个机器而言; 4)类似于ECC mode,MIG 设置是persistent的,即使reboot也不会影响。直到用户显式地切换。 5)在起用MIG之前,所有hold driver modules handles的进程必须被停掉。 6)切换 MIG 模式需要 CAP_SYS_ADMIN 功能。其他 MIG 管理(例如创建和销毁实例)默认需要超级用户,但可以通过在 /proc/ 中调整对 MIG 功能的权限来委托给非特权用户。 三 优势 更多用户享受到 GPU 加速能力 借助 MIG技术,用户可以在单个 A100 GPU 上获得多达原来 7 倍的 GPU 资源。MIG 为研发人员提供了更多的资源和更高的灵活性。 优化 GPU 利用率 MIG 允许用户灵活选择许多不同的实例大小,从而为每项工作负载提供适当规模的 GPU 实例,最终优化利用率并使数据中心投资充分发挥成效。 同时运行混合工作负载 凭借 MIG,能以确定性延迟和吞吐量,在单个 GPU 上同时运行推理、训练和高性能计算 (HPC) 工作负载。 编程模型没有变化 NVIDIA通过它为其A100提供的软件启用MIG。其中包括GPU驱动程序、NVIDIA的CUDA11软件,使得每个 MIG 实例对于应用程序都像独立 GPU 一样运行,使其编程模型没有改变,对开发者友好。 提供出色的服务质量 每个 MIG 实例都有一套专用于计算、内存和缓存的硬件资源,从而能为工作负载提供稳定可靠的服务质量 (QoS) 和有效的故障隔离。这样一来,如果某个实例上运行的应用程序发生故障,并不会影响其他实例上运行的应用程序。而且,不同的实例可以运行不同类型的工作负载,包括交互式模型开发、深度学习训练、AI 推理或高性能计算应用程序等。由于这些实例并行运行,因此工作负载也在同一个物理 A100 GPU 上同时运行,但它们彼此相互独立、隔离。






