
本文介绍Nvidia GPU设备如何在Kubernetes中管理调度。 整个工作流程分为以下两个方面:
- 如何在容器中使用GPU
- Kubernetes 如何调度GPU
如何在容器中使用GPU
想要在容器中的应用可以操作GPU, 需要实两个目标
- 容器中可以查看GPU设备
- 容器中运行的应用,可以通过Nvidia驱动操作GPU显卡
详细介绍可见: https://devblogs.nvidia.com/gpu-containers-runtime/
Nvidia-docker
GitHub: https://github.com/NVIDIA/nvidia-docker
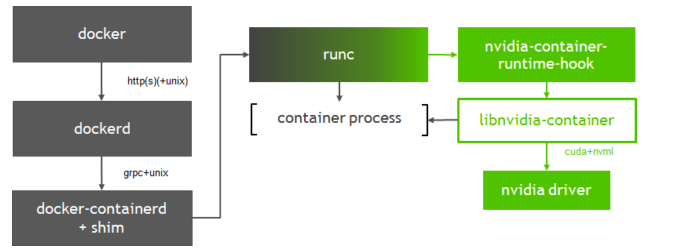
Nvidia提供Nvidia-docker项目,它是通过修改Docker的Runtime为nvidia runtime工作,当我们执行 nvidia-docker create 或者 nvidia-docker run 时,它会默认加上 --runtime=nvidia 参数。将runtime指定为nvidia。
当然,为了方便使用,可以直接修改Docker daemon 的启动参数,修改默认的 Runtime为 nvidia-container-runtime
cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
gpu-containers-runtime
GitHub: https://github.com/NVIDIA/nvidia-container-runtimegpu-containers-runtime 是一个NVIDIA维护的容器 Runtime,它在runc的基础上,维护了一份 Patch, 我们可以看到这个patch的内容非常简单, 唯一做的一件事情就是在容器启动前,注入一个 prestart 的hook 到容器的Spec中(hook的定义可以查看 OCI规范 )。这个hook 的执行时机是在容器启动后(Namespace已创建完成),容器自定义命令(Entrypoint)启动前。nvidia-containers-runtime 定义的 prestart 的命令很简单,只有一句 nvidia-container-runtime-hook prestart
gpu-containers-runtime-hook
GitHub: https://github.com/NVIDIA/nvidia-container-runtime/tree/master/hook/nvidia-container-runtime-hook gpu-containers-runtime-hook 是一个简单的二进制包,定义在Nvidia container runtime的hook中执行。 目的是将当前容器中的信息收集并处理,转换为参数调用 nvidia-container-cli 。
主要处理以下参数:
- 根据环境变量
NVIDIA_VISIBLE_DEVICES判断是否会分配GPU设备,以及挂载的设备ID。如果是未指定或者是void,则认为是非GPU容器,不做任何处理。 否则调用nvidia-container-cli, GPU设备作为--devices参数传入 - 环境环境变量
NVIDIA_DRIVER_CAPABILITIES判断容器需要被映射的 Nvidia 驱动库。 - 环境变量
NVIDIA_REQUIRE_*判断GPU的约束条件。 例如cuda>=9.0等。 作为--require=参数传入 - 传入容器进程的Pid
gpu-containers-runtime-hook 做的事情,就是将必要的信息整理为参数,传给 nvidia-container-cli configure 并执行。
nvidia-container-cli
nvidia-container-cli 是一个命令行工具,用于配置Linux容器对GPU 硬件的使用。支持
- list: 打印 nvidia 驱动库及路径
- info: 打印所有Nvidia GPU设备
- configure: 进入给定进程的命名空间,执行必要操作保证容器内可以使用被指定的GPU以及对应能力(指定 Nvidia 驱动库)。 configure是我们使用到的主要命令,它将Nvidia 驱动库的so文件 和 GPU设备信息, 通过文件挂载的方式映射到容器中。
代码如下: https://github.com/NVIDIA/libnvidia-container/blob/master/src/cli/configure.c#L272
/* Mount the driver and visible devices. */
if (perm_set_capabilities(&err, CAP_EFFECTIVE, ecaps[NVC_MOUNT], ecaps_size(NVC_MOUNT)) < 0) {
warnx("permission error: %s", err.msg);
goto fail;
}
if (nvc_driver_mount(nvc, cnt, drv) < 0) {
warnx("mount error: %s", nvc_error(nvc));
goto fail;
}
for (size_t i = 0; i < dev->ngpus; ++i) {
if (gpus[i] != NULL && nvc_device_mount(nvc, cnt, gpus[i]) < 0) {
warnx("mount error: %s", nvc_error(nvc));
goto fail;
}
}
如果对其他模块感兴趣,可以在 https://github.com/NVIDIA/libnvidia-container 阅读代码。
以上就是一个nvidia-docker的容器启动的所有步骤。
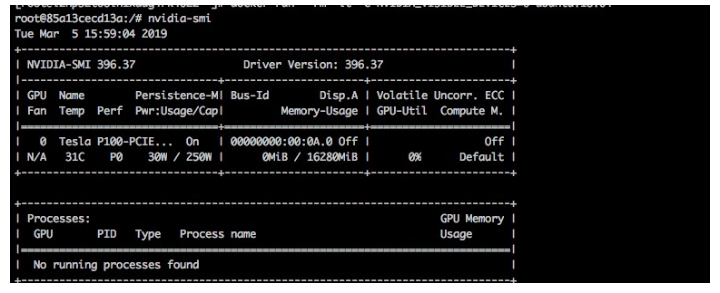
当我们安装了nvidia-docker, 我们可以通过以下方式启动容器
docker run --rm -it -e NVIDIA_VISIBLE_DEVICES=all ubuntu:18.04
在容器中执行 mount 命令,可以看到名为 libnvidia-xxx.so 和 /proc/driver/nvidia/gpus/xxx 映射到容器中。 以及 nvidia-smi 和 nvidia-debugdump 等nvidia工具。
# mount
## ....
/dev/vda1 on /usr/bin/nvidia-smi type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-debugdump type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-persistenced type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-cuda-mps-control type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-cuda-mps-server type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-cfg.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libcuda.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-opencl.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-fatbinaryloader.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-compiler.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
devtmpfs on /dev/nvidiactl type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
devtmpfs on /dev/nvidia-uvm type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
devtmpfs on /dev/nvidia-uvm-tools type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
devtmpfs on /dev/nvidia4 type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
proc on /proc/driver/nvidia/gpus/0000:00:0e.0 type proc (ro,nosuid,nodev,noexec,relatime)
我们可以执行nvidia-smi查看容器中被映射的GPU卡
Kubernetes 如何调度GPU
之前我们介绍了如何在容器中使用Nvidia GPU卡。 那么当一个集群中有成百上千个节点以及GPU卡,我们的问题变成了如何管理和调度这些GPU。
Device plugin
Kubernetes 提供了Device Plugin 的机制,用于异构设备的管理场景。原理是会为每个特殊节点上启动一个针对某个设备的DevicePlugin pod, 这个pod需要启动grpc服务, 给kubelet提供一系列接口。
type DevicePluginClient interface {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
GetDevicePluginOptions(ctx context.Context, in *Empty, opts ...grpc.CallOption) (*DevicePluginOptions, error)
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disapears, ListAndWatch
// returns the new list
ListAndWatch(ctx context.Context, in *Empty, opts ...grpc.CallOption) (DevicePlugin_ListAndWatchClient, error)
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
Allocate(ctx context.Context, in *AllocateRequest, opts ...grpc.CallOption) (*AllocateResponse, error)
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as reseting the device before making devices available to the container
PreStartContainer(ctx context.Context, in *PreStartContainerRequest, opts ...grpc.CallOption) (*PreStartContainerResponse, error)
}
DevicePlugin 注册一个 socket 文件到 /var/lib/kubelet/device-plugins/ 目录下,kubelet 通过这个目录下的socket文件向对应的 Device plugin 发送grpc请求。
本文不过多介绍Device Plugin 的设计, 感兴趣可以阅读这篇文章: https://yq.aliyun.com/articles/498185a
Nvidia plugin
Github: https://github.com/NVIDIA/k8s-device-plugin
为了能够在Kubernetes中管理和调度GPU, Nvidia提供了Nvidia GPU的Device Plugin。 主要功能如下
- 支持ListAndWatch 接口,上报节点上的GPU数量
- 支持Allocate接口, 支持分配GPU的行为。
Allocate 接口只做了一件事情,就是给容器加上 NVIDIA_VISIBLE_DEVICES 环境变量。 https://github.com/NVIDIA/k8s-device-plugin/blob/v1.11/server.go#L153
// Allocate which return list of devices.
func (m *NvidiaDevicePlugin) Allocate(ctx context.Context, reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
devs := m.devs
responses := pluginapi.AllocateResponse{}
for _, req := range reqs.ContainerRequests {
response := pluginapi.ContainerAllocateResponse{
Envs: map[string]string{
"NVIDIA_VISIBLE_DEVICES": strings.Join(req.DevicesIDs, ","),
},
}
for _, id := range req.DevicesIDs {
if !deviceExists(devs, id) {
return nil, fmt.Errorf("invalid allocation request: unknown device: %s", id)
}
}
responses.ContainerResponses = append(responses.ContainerResponses, &response)
}
return &responses, nil
}
前面我们提到, Nvidia的 gpu-container-runtime 根据容器的 NVIDIA_VISIBLE_DEVICES 环境变量,会决定这个容器是否为GPU容器,并且可以使用哪些GPU设备。 而Nvidia GPU device plugin做的事情,就是根据kubelet 请求中的GPU DeviceId, 转换为 NVIDIA_VISIBLE_DEVICES 环境变量返回给kubelet, kubelet收到返回内容后,会自动将返回的环境变量注入到容器中。当容器中包含环境变量,启动时 gpu-container-runtime 会根据 NVIDIA_VISIBLE_DEVICES 里声明的设备信息,将设备映射到容器中,并将对应的Nvidia Driver Lib 也映射到容器中。
总体流程
整个Kubernetes调度GPU的过程如下:
- GPU Device plugin 部署到GPU节点上,通过
ListAndWatch接口,上报注册节点的GPU信息和对应的DeviceID。 - 当有声明
nvidia.com/gpu的GPU Pod创建出现,调度器会综合考虑GPU设备的空闲情况,将Pod调度到有充足GPU设备的节点上。 - 节点上的kubelet 启动Pod时,根据request中的声明调用各个Device plugin 的 allocate接口, 由于容器声明了GPU。 kubelet 根据之前
ListAndWatch接口收到的Device信息,选取合适的设备,DeviceID 作为参数,调用GPU DevicePlugin的Allocate接口 - GPU DevicePlugin ,接收到调用,将DeviceID 转换为
NVIDIA_VISIBLE_DEVICES环境变量,返回kubelet - kubelet将环境变量注入到Pod, 启动容器
- 容器启动时,
gpu-container-runtime调用gpu-containers-runtime-hook gpu-containers-runtime-hook根据容器的NVIDIA_VISIBLE_DEVICES环境变量,转换为--devices参数,调用nvidia-container-cli prestartnvidia-container-cli根据--devices,将GPU设备映射到容器中。 并且将宿主机的Nvidia Driver Lib 的so文件也映射到容器中。 此时容器可以通过这些so文件,调用宿主机的Nvidia Driver。












