
逻辑分层
下面是MySQL的逻辑分层图:
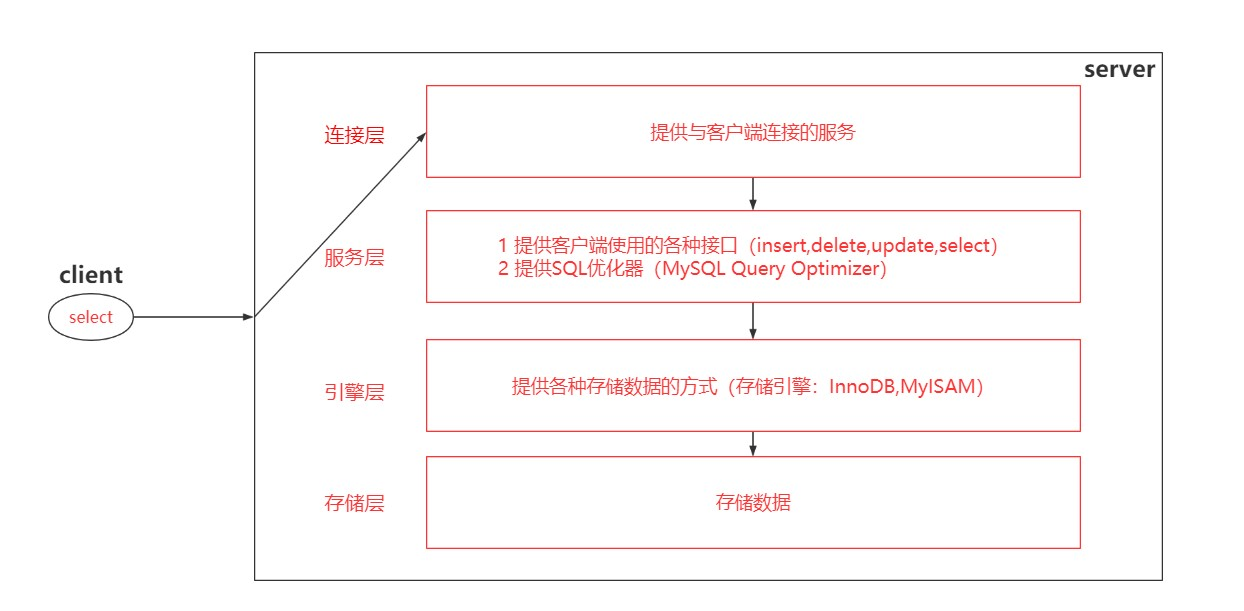
连接层:连接与线程处理,这一层并不是MySQL独有,一般的基于C/S架构的都有类似组件,比如连接处理、授权认证、安全等。
服务层:包括缓存查询、解析器、优化器,这一部分是MySQL核心功能,包括解析、优化SQL语句,查询缓存目录,内置函数(日期、时间、加密等函数)的实现。
引擎层:负责数据存储,存储引擎的不同,存储方式、数据格式、提取方式等都不相同,这一部分也是很大影响数据存储与提取的性能的;对存储层的抽象。
存储层:存储数据,文件系统。
存储引擎
查看数据库支持的存储引擎:show engines;
如果要想查看数据库默认使用哪个引擎,可以通过使用命令: show variables like '%storage_engine%';
InnoDB,MyISAM的主要区别:
InnoDB:在MySQL5.5开始作为默认的存储引擎,支持事务,行级锁,适合高并发场景,XA协议支持分布式事务,事务优先。
MyISAM:不支持事务,性能优先,表级锁,不适合高并发场景。
sql执行顺序:https://www.cnblogs.com/annsshadow/p/5037667.html
explain-执行计划
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
使用方法,在select语句前加上explain就可以了:
如:explain select surname,first_name form a,b where a.id=b.id
EXPLAIN列的解释:
id:情况有三种,分别是:id相同表示加载表的顺序是从上到下。id不同id值越大,优先级越高,越先被执行。id有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。
possible_keys:显示可能应用在这张表中的索引。但是并不表示此索引会真正地被 MySQL 使用到,如果为空,没有可能的索引。
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows:MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数.这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好.
Extra:关于MYSQL如何解析查询的额外信息
select_type
select_type 表示了查询的类型, 它的常用取值有:
SIMPLE, 表示此查询不包含 UNION 查询或子查询
PRIMARY, 表示此查询是最外层的查询
UNION, 表示此查询是 UNION 的第二或随后的查询
DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询
UNION RESULT, UNION 的结果
SUBQUERY, 子查询中的第一个 SELECT
DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
最常见的查询类别应该是 SIMPLE 了, 比如当我们的查询没有子查询, 也没有 UNION 查询时, 那么通常就是 SIMPLE 类型
type
type 字段比较重要, 它提供了判断查询是否高效的重要依据依据. 通过 type 字段, 我们判断此次查询是 全表扫描 还是 索引扫描 等,(常见的)从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
system: 表中只有一条数据. 这个类型是特殊的const类型.const: 针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可eq_ref: 此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是=, 查询效率较高.ref: 此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了最左前缀(索引使用顺序和定义顺序一致)规则索引的查询.range: 表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录. 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中.
当type是range时, 那么 EXPLAIN 输出的ref字段为 NULL, 并且key_len字段是此次查询中使用到的索引的最长的那个.(in查询时有时候会失效,从而变成无索引All)index: 表示全索引扫描(full index scan), 和 ALL 类型类似, 只不过 ALL 类型是全表扫描, 而 index 类型则仅仅扫描所有的索引, 而不扫描数据.index类型通常出现在: 所要查询的数据直接在索引树中就可以获取到, 而不需要扫描数据. 当是这种情况时, Extra 字段 会显示Using index.ALL: 表示全表扫描, 这个类型的查询是性能最差的查询之一. 通常来说, 我们的查询不应该出现 ALL 类型的查询, 因为这样的查询在数据量大的情况下, 对数据库的性能是巨大的灾难. 如一个查询是 ALL 类型查询, 那么一般来说可以对相应的字段添加索引来避免.
ALL 类型因为是全表扫描, 因此在相同的查询条件下, 它是速度最慢的.而 index 类型的查询虽然不是全表扫描, 但是它扫描了所有的索引, 因此比 ALL 类型的稍快.
Extra
EXplain 中的很多额外的信息会在 Extra 字段显示, 常见的有以下几种内容:
- Using filesort
当 Extra 中有Using filesort时, 表示 MySQL 需额外的排序操作, 不能通过索引顺序达到排序效果. 一般有Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大.
例: SELECT * FROM order_info ORDER BY product_name;(索引是:`` `user_product_detail_index` (`user_id`, `product_name`, `productor`)``)
但是上面的查询中根据 product_name 来排序, 因此不能使用索引进行优化, 进而会产生 Using filesort.
如果我们将排序依据改为 ORDER BY user_id, product_name, 那么就不会出现 Using filesort 了
Using index "覆盖索引扫描", 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错
Using temporary 查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化.
优化小结:
-
最左前缀(索引使用顺序和定义顺序一致) - 将含有in的范围查询放到where条件的最后,防止索引失效
- using where 需要回原表查询,using index不需要回原表查询











