
架构拓扑图为:
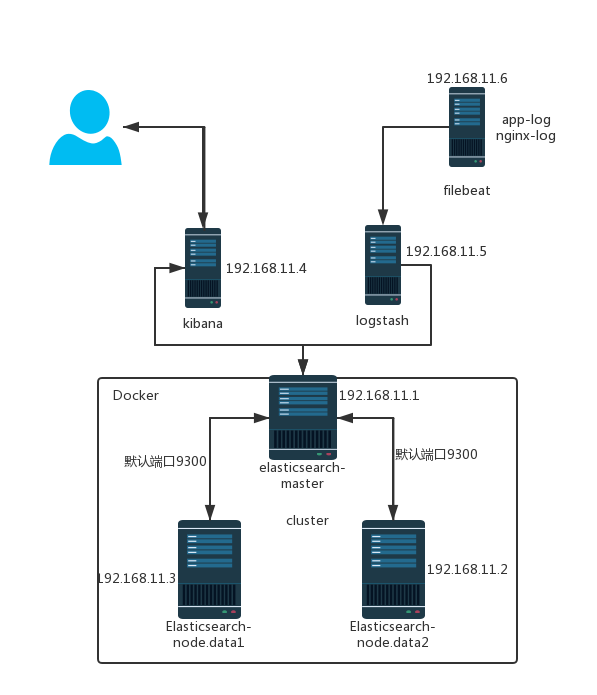
准备工作:
下载资源包:
Elasticsearch: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz # 这一步用docker启动,可以不用下载。
Kibana: wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86\_64.tar.gz
Logstash:wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz
Filebeat:wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-linux-x86\_64.tar.gz
安装:
根据拓扑图把对应的服务安装在对应的服务器。
tar xvf kibana-6.2.3-linux-x86_64.tar.gz -C /usr/local/
tar xvf logstash-6.2.4.tar.gz -C /usr/local/
tar -xvf filebeat-6.2.4-linux-x86_64.tar.gz -C /usr/local/
部署启动:
Elasticsearch-master(192.168.11.1):
需自行提前安装好docker 和 docker-compose。
vim docker-compose.yml
version: '2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.2.3
container_name: elasticsearch
environment:
- cluster.name=es-cluster
- bootstrap.memory_lock=true
- "network.publish_host=192.168.11.1"
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /data/elasticsearch_data:/usr/share/elasticsearch/data
ports:
- "192.168.11.1:9200:9200"
- "192.168.11.1:9300:9300"
mkdir -p /data/elasticsearch_data && chmod 775 /data/elasticsearch_data && docker-compose up -d
Elasticsearch-node2.data(192.168.11.2):
需自行提前安装好docker 和 docker-compose。
vim docker-compose.yml
version: '2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.2.3
container_name: elasticsearch
environment:
- cluster.name=es-cluster
- bootstrap.memory_lock=true
- "network.publish_host=192.168.11.2" - "discovery.zen.ping.unicast.hosts=192.168.11.1"
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /data/elasticsearch_data:/usr/share/elasticsearch/data
ports:
- "192.168.11.2:9200:9200"
- "192.168.11.2:9300:9300"
mkdir -p /data/elasticsearch_data && chmod 775 /data/elasticsearch_data && docker-compose up -d
Elasticsearch-node3.data(192.168.11.3):
需自行提前安装好docker 和 docker-compose。
vim docker-compose.yml
version: '2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.2.3
container_name: elasticsearch
environment:
- cluster.name=es-cluster
- bootstrap.memory_lock=true
- "network.publish_host=192.168.11.3" - "discovery.zen.ping.unicast.hosts=192.168.11.1"
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /data/elasticsearch_data:/usr/share/elasticsearch/data
ports:
- "192.168.11.3:9200:9200"
- "192.168.11.3:9300:9300"
mkdir -p /data/elasticsearch_data && chmod 775 /data/elasticsearch_data && docker-compose up -d
查看集群节点:curl -XGET 'http://192.168.11.1:9200/\_cat/nodes?pretty'
kibana(192.168.11.4):
cd /usr/local/kibana-6.2.3-linux-x86_64
cp ./config/kibana.yml ./config/kibana.yml.bak
echo '' > ./config/kibana.yml
vim ./config/kibana.yml
server.port: 5601
server.host: "192.168.11.4"
elasticsearch.url: "http://192.168.11.1:9200"
启动:./bin/kibana
扩展包(可装可不装):
kibana 报警扩展:
安装 ./bin/kibana-plugin install https://github.com/sirensolutions/sentinl/releases/download/tag-6.2.3-2/sentinl-v6.2.3.zip
重启 kibana
logstash(192.168.11.5)
cd /usr/local/logstash-6.2.4
vim nginx.conf
input {
beats {
port => 5066
host => "192.168.11.5"
codec => "json"
}
}
filter {
mutate {
gsub => ["message", "\\x", "\\\x"]
}
json {
source => "message"
}
}
output {
elasticsearch {
action => "index"
hosts => "192.168.11.1:9200"
index => "nginx-json-%{+YYYY.MM.dd}"
}
}
mkdir -p /data/logstash-data/nginx
启动:./bin/logstash -f ./nginx.conf --path.data=/data/logstash-data/nginx &
扩展
grok调试地址:http://grokdebug.herokuapp.com/
如需调试请修改output成以下,方便debug
output {
stdout {
codec => rubydebug
}
}
filebeat(192.168.11.6)
cd /usr/local/filebeat-6.2.4-linux-x86_64
vim nginx.yml
filebeat.prospectors:
- input_type: log
document_type: jsonlog
paths:
- /var/log/nginx/access.log
output:
logstash:
hosts: ["192.168.11.5:5066"]
启动:./filebeat -c ./nginx.yml &
nginx 日志的输出格式为:
log_format json '{"@timestamp":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"request":"$request",'
'"status":$status,'
'"body_bytes":$body_bytes_sent,'
'"user_agent":"$http_user_agent",'
'"resp_time":"$upstream_response_time",'
'"req_time":$request_time,'
'"host":"$host",'
'"@version":"1",'
'"http_x_forwarded_for":"$http_x_forwarded_for",'
'"upstream_addr":"$upstream_addr",'
'"req_body":"$request_body"}';
参考地址:
https://www.elastic.co/guide/index.html
http://docs.docker.com/compose/
https://www.elastic.co/guide/en/logstash/current/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/6.2/docker.html










