
MySql之自动同步表结构
开发痛点
在开发过程中,由于频繁的修改数据库的字段,导致rd和qa环境的数据库表经常不一致。
而由于这些修改数据库的操作可能由多个rd操作,很难一次性收集全。人手工去和qa环境对字段又特别繁琐,容易遗漏。
解决之道
于是笔者就写了一个能够自动比较两个数据库的表结构,并生成alter语句的程序。同时还可以进行配置从而自动这行这些alter语句。详情见github
原理
同步新增的表
如果rd环境新增的表,而qa环境没有,此程序可以直接输出create table语句。原理如下: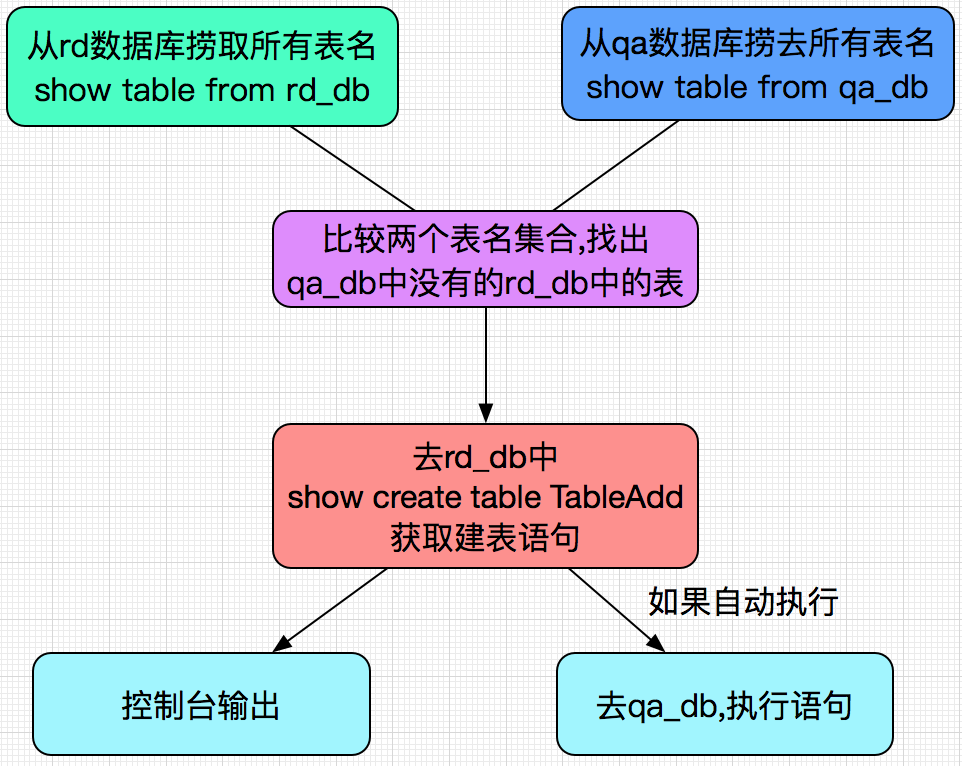
用到的sql主要有:
show table from rd_db;
show create table added_table_name;
同步表结构
如果rd表结构有改动,而qa环境没有,此程序可以直接输出alter语句,原理如下: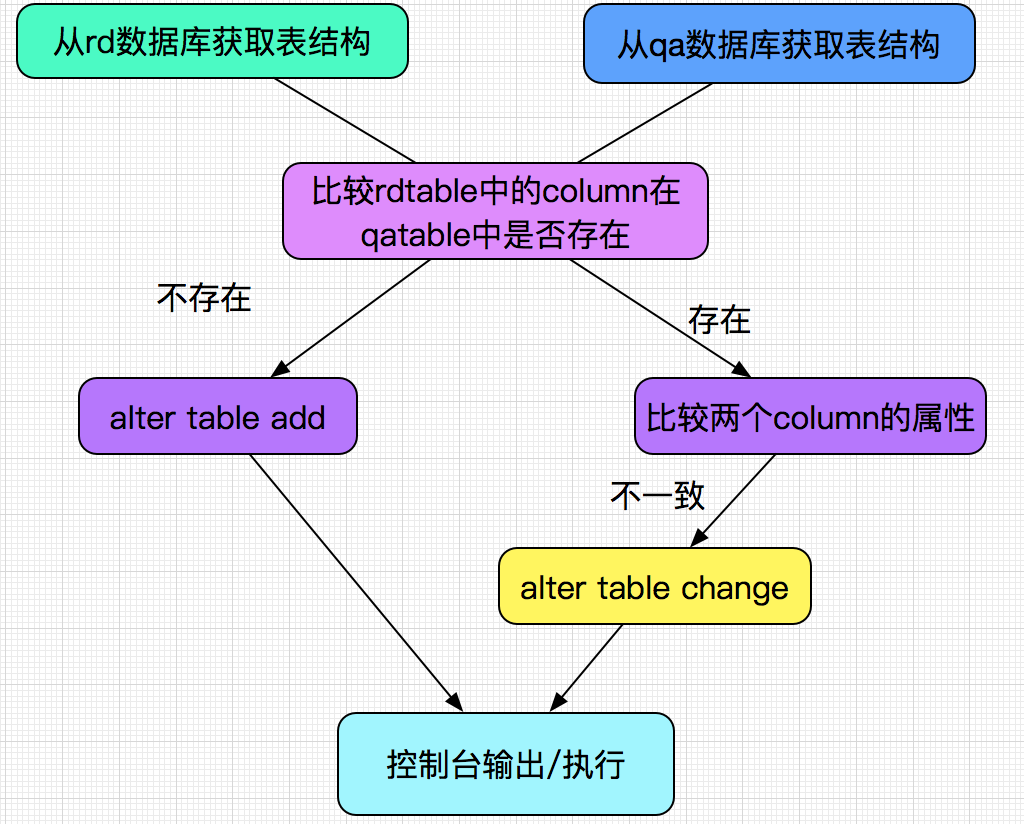
用到的sql有:
select
COLUMN_NAME,COLUMN_TYPE,IS_NULLABLE,COLUMN_DEFAULT,COLUMN_COMMENT,EXTRA
from
information_schema.columns
where
TABLE_SCHEMA='rd_db'
and TABLE_NAME = 'rd_table';
比较表结构的代码:
for (Column column : sourceTable.getColumns().values()) {
if (targetTable.getColumns().get(column.getName()) == null) {
// 如果对应的target没有这个字段,直接alter
String sql = "alter table " + target.getSchema() + "." + targetTable.getTableName() + " add " + column
.getName() + " ";
sql += column.getType() + " ";
if (column.getIsNull().equals("NO")) {
sql += "NOT NULL ";
} else {
sql += "NULL ";
}
if (column.getDefaultValue() != null) {
sql += "DEFAULT " + SqlUtil.getDbString(column.getDefaultValue()) + " ";
}
if (column.getComment() != null) {
sql += "COMMENT " + SqlUtil.getDbString(column.getComment()) + " ";
}
if (after != null) {
sql += "after " + after;
}
changeSql.add(sql+";");
} else {
// 检查对应的source 和 target的属性
String sql =
"alter table " + target.getSchema() + "." + targetTable.getTableName() + " change " + column
.getName() + " ";
Column sourceColumn = column;
Column targetColumn = targetTable.getColumns().get(sourceColumn.getName());
// 比较两者字段,如果返回null,表明一致
String sqlExtend = compareSingleColumn(sourceColumn, targetColumn);
if (sqlExtend != null) {
changeSql.add(sql + sqlExtend+";");
}
}
after = column.getName();
}
同步索引结构
如果rd表的索引有改变,而qa环境没有,此程序可以直接输出修改索引语句。原理和上面类似,在此不再赘述。
配置
sourceHost=127.0.0.1:3306
sourceUser=root
sourcePass=123123123
sourceSchema=mystique_db
sourceCharset=utf8
targetHost=127.0.0.1:3306
targetUser=root
targetPass=123123123
targetSchema=mystique_test
targetCharset=utf8
autoExecute=YES //此处表明自动同步
运行
按照上面的模板进行配置 用IDE打开,找到
alchemystar.runner.ShellRunner
运行其中的main方法即可
生成效果展示
alter table mystique_test.t_test_3 change id id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ''
alter table mystique_test.t_test_3 add index (name)
alter table mystique_test.t_test_3 drop index name_id
alter table mystique_test.t_test_3 add id_2 varchar(50) NULL DEFAULT '' COMMENT '' after name
如果打开了自动执行,会自动执行这些语句
公众号
关注笔者公众号,获取更多干货文章:
github链接
https://github.com/alchemystar/Lancer
码云链接
https://git.oschina.net/alchemystar/Lancer










