一、前言
大家好,我是崔艳飞。接到项目求助,需要对上千个文件夹中的文件进行压缩处理,并要删除源文件,只保留压缩后的压缩文件,数据量大,手动完成耗时耗力,用Python处理再合适不过了。
二、项目目标
批量对文件夹的内容进行压缩处理,满足客户要求。
三、项目准备
软件:PyCharm
需要的库:os, shutil,zipfile
四、项目分析
1)如何读取源文件?
利用OS库,获取文件夹名list,利用for循环,轻松拿到要压缩的源文件。
2)如何进行压缩处理?
利用zipfile库中的zipfile.ZipFile()对获取到的文件进行压缩处理。
3)如何删除源文件?
先利用os库的remove()删除文件,再利用shutil库的rmtree()删除空文件夹。
五、项目实现
1、第一步导入需要的三个库
import os as os
import shutil
import zipfile2、第二步定义删除文件函数和压缩文件函数
def del_(rootdir):
filelist = []
filelist = os.listdir(rootdir) # 列出该目录下的所有文件名
for f in filelist:
filepath = os.path.join(rootdir, f) # 将文件名映射成绝对路劲
if os.path.isfile(filepath): # 判断该文件是否为文件或者文件夹
os.remove(filepath) # 若为文件,则直接删除
elif os.path.isdir(filepath):
shutil.rmtree(filepath, True) # 若为文件夹,则删除该文件夹及文件夹内所有文件
shutil.rmtree(rootdir, True)
def zipDir(dirpath,outFullName):
zip = zipfile.ZipFile(outFullName,"w",zipfile.ZIP_DEFLATED)
for path,dirnames,filenames in os.walk(dirpath):
# 去掉目标跟路径,只对目标文件夹下边的文件及文件夹进行压缩
fpath = path.replace(dirpath,'')
for filename in filenames:
zip.write(os.path.join(path,filename),os.path.join(fpath,filename))
zip.close()3、第三步创建主函数
def main():
path_end = 'D:/a/h/'
date= os.listdir(path_end)
# 获取目标文件夹所有文件夹名列表
for f in date:
ljbc='D:/a/h/'+f+'/'+'查询信息.zip'
ljbc2 = 'D:/a/h/' + f + '/' + '下发修改.zip'
#以上两行是创建压缩后的文件名
ljcx='D:/a/h/'+f+'/查询信息'
ljxf = 'D:/a/h/' + f + '/下发修改'
#以上两行是要压缩的源文件
zipDir(ljcx,ljbc)
zipDir(ljxf, ljbc2)
del_(ljcx)
del_(ljxf)
if __name__ == '__main__':
main()六、效果展示
1、处理后的文件夹:
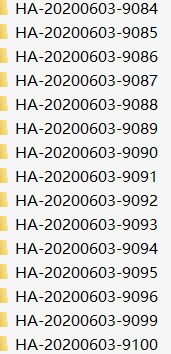
2、处理后的文件夹内的压缩文件:

七、总结
本文介绍了如何利用Python对大批量的文件进行批量压缩处理,其实就是几行语句就能实现,程序写好后,不到1分钟就能完成1个人1天也不可能完成的任务。人生苦短,要用Python!
最后需要本文项目代码的小伙伴,请在公众号后台回复“文件压缩”关键字进行获取,如果在运行过程中有遇到任何问题,请随时留言或者加小编好友,小编看到会帮助大家解决bug噢!
**-----**------**-----**---**** End **-----**--------**-----**-****
往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/HxDuyRDapmCEP8JZ5Fp47A,如有侵权,请联系删除。