
源文件放在github,如有谬误之处,欢迎指正。原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/hash-shuffle.md
正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍hash shuffle。
spark在1.2前默认为hash shuffle(spark.shuffle.manager = hash),但hash shuffle也经历了两个发展阶段。 ##第一阶段
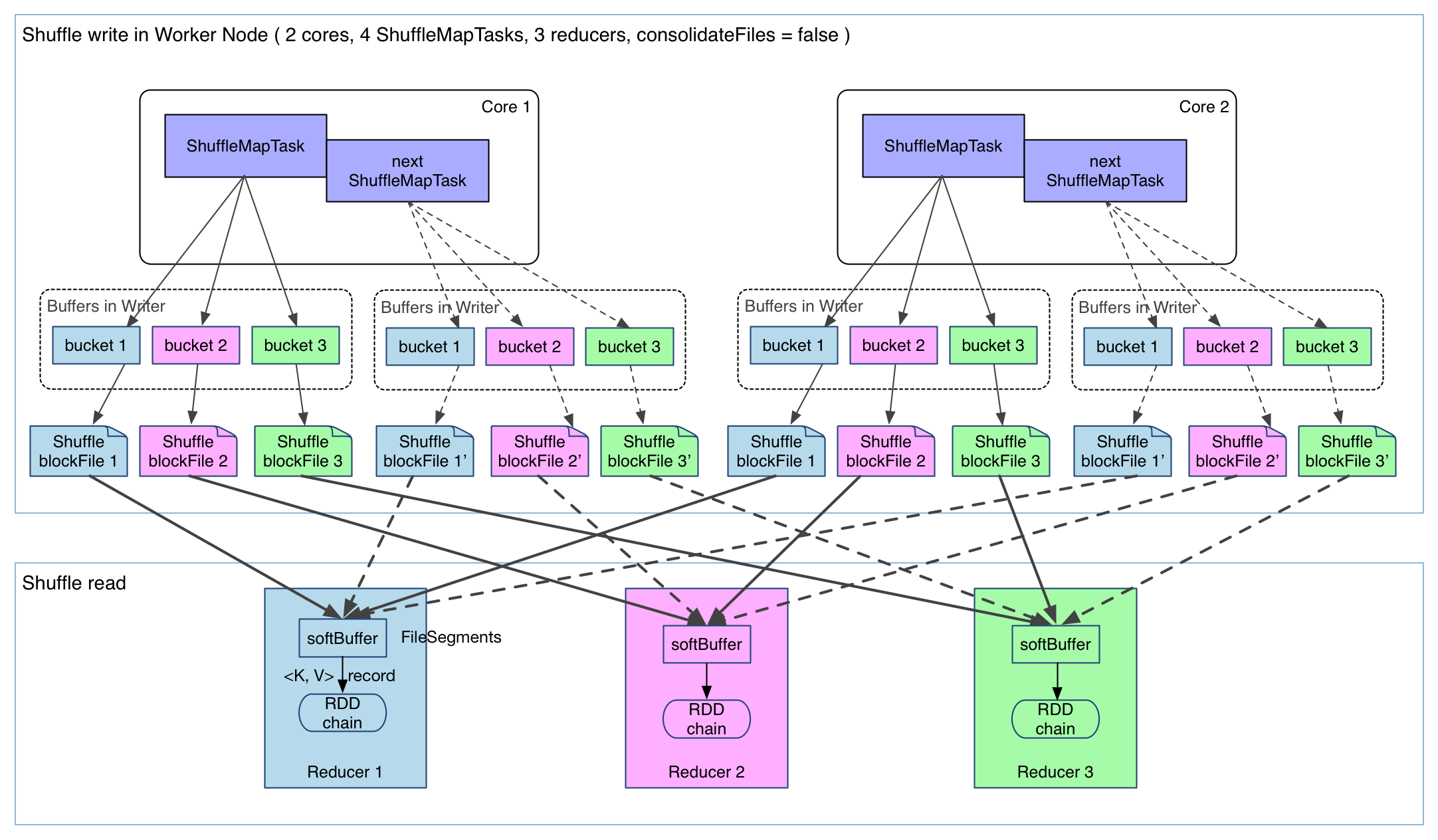
上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R = reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小为spark.shuffle.file.buffer.kb ,默认是 32KB(Spark 1.1 版本以前是 100KB)。
##第二阶段 这样的实现很简单,但有几个问题:
1 产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
2 缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M * R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores * R * 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
spark.shuffle.consolidateFiles默认为false,如果为true,shuffleMapTask输出文件可以被合并。如图
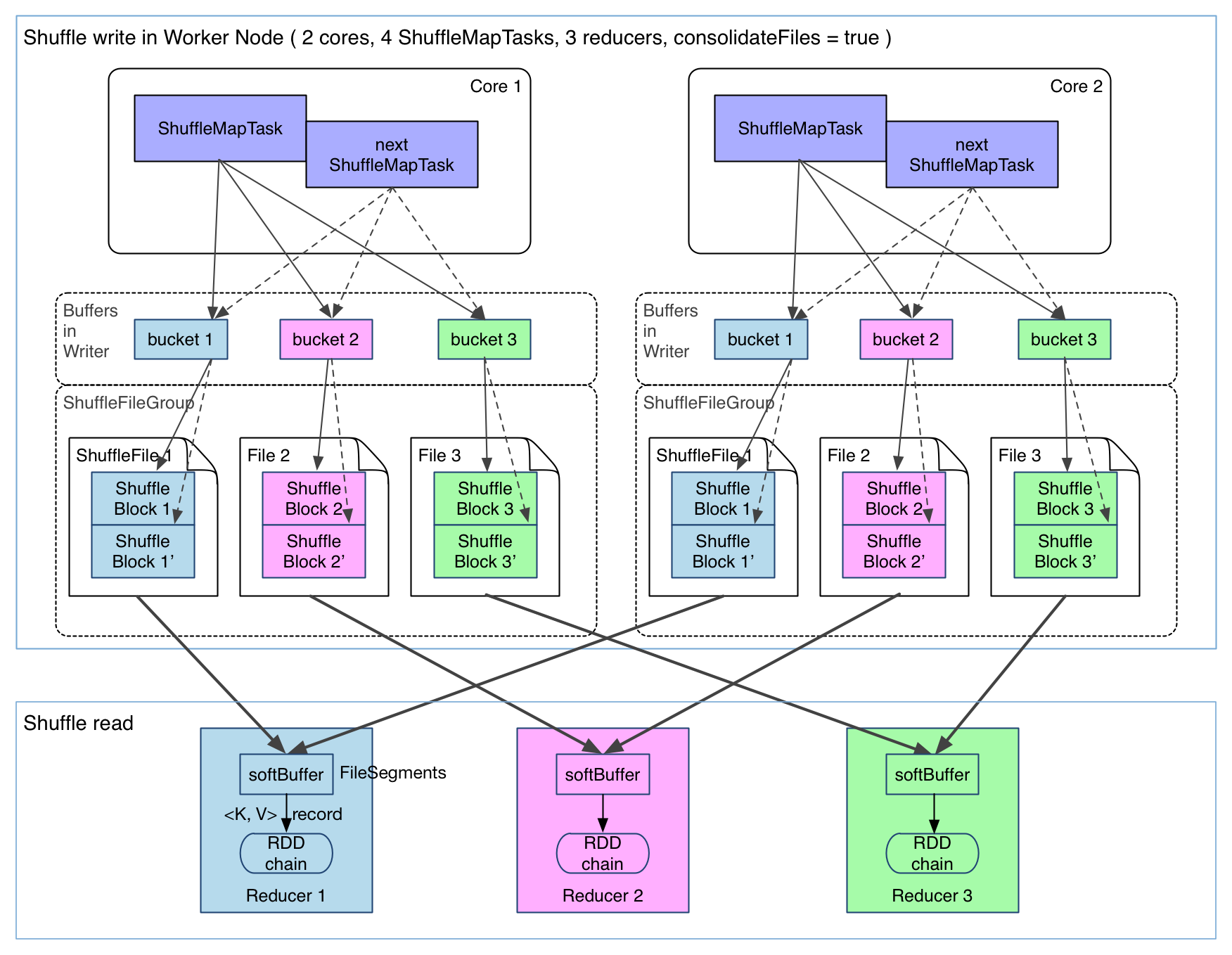
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i',每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores * R。但是缓存空间占用大还没有解决。
##总结
###优点
- 快-不需要排序,也不需要维持hash表
- 不需要额外空间用作排序
- 不需要额外IO-数据写入磁盘只需一次,读取也只需一次
###缺点
- 当partitions大时,输出大量的文件(cores * R),性能开始降低
- 大量的文件写入,使文件系统开始变为随机写,性能比顺序写要降低100倍
- 缓存空间占用比较大
当然,数据经过序列化、压缩写入文件,读取的时候,需要反序列化、解压缩。reduce fetch的时候有一个非常重要的参数spark.reducer.maxSizeInFlight,这里用 softBuffer 表示,默认大小为 48MB。一个 softBuffer 里面一般包含多个 FileSegment,但如果某个 FileSegment 特别大的话,这一个就可以填满甚至超过 softBuffer 的界限。如果增大,reduce请求的chunk就会变大,可以提高性能,但是增加了reduce的内存使用量。
如果排序在reduce不强制执行,那么reduce只返回一个依赖于map的迭代器。如果需要排序, 那么在reduce端,调用ExternalSorter。
##参考文献











