
源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正。原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/tungsten-sort-shuffle.md
正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍tungsten-sort。
spark在1.4以后可以通过(spark.shuffle.manager = tungsten-sort)开启Tungsten-sort shuffle。如果Tungsten-sort 发现自己无法处理,则会自动使用 Sort Based Shuffle进行处理。Tungsten-sort优化点主要有:
直接在serialized binary data上操作,不需要反序列化,使用unsafe内存copy函数直接copy数据。
提供cache-efficient sorter ShuffleExternalSorter 排序压缩记录指针和partition ids,使用一个8bytes的指针,把排序转化成了一个指针数组的排序。
spilling的时候不需要反序列化和序列化
spill的merge过程也无需反序列化即可完成,但需要shuffle.unsafe.fastMergeEnabled的支持
当且仅当下面条件都满足时,才会使用新的Shuffle方式:
Shuffle dependency 不能带有aggregation 或者输出需要排序
Shuffle 的序列化器需要是 KryoSerializer 或者 Spark SQL's 自定义的一些序列化方式.* > Shuffle 文件的数量不能大于 16777216
序列化时,单条记录不能大于 128 MB
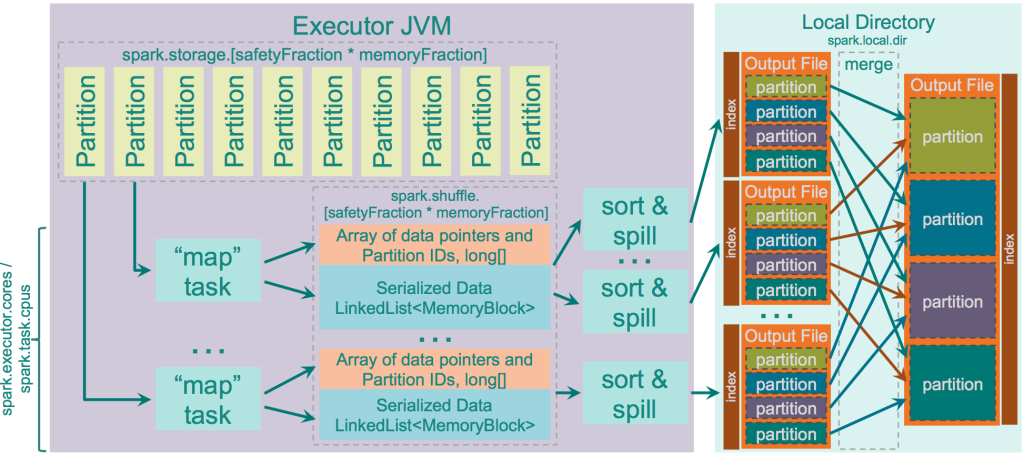
##优点 很多性能的优化
##缺点
- 不可以在mapper端排序
- 不稳定
- 没有提供off-heap排序缓存
##参考 Spark Tungsten-sort Based Shuffle 分析 探索Spark Tungsten的秘密











