
为什么我继续看好MySQL
最近几年,似乎总有一种声音在说,MySQL可能不太行了,原因无非是这么几条,MySQL功能不如PG强大,原生没有分库分表不如TIDB,OLAP性能差。
可事实真的如此吗?
我斗胆哔哔几句,这个行业大佬太多,个人高度有限,说错了勿怪,这只是我一家之言,欢迎留言指正。
一、功能不够多
先说说功能方面吧,PG号称功能最全,甚至还超过Oracle。
可事实呢,其市场占有率数据我是没有,但在传统行业,想超过Oracle,乃至SQL Server都不太可能,在互联网行业更是远远落后于MySQL。
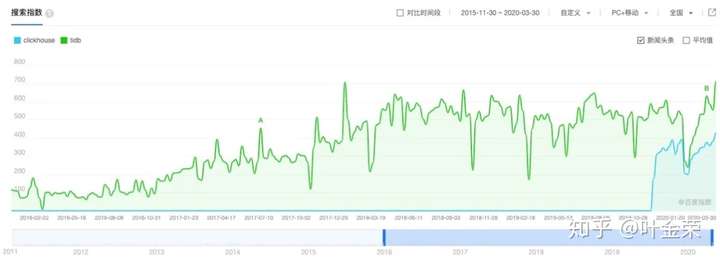
我们可以拿百度指数当参考(国内还是用百度更多,所以没用谷歌趋势数据),如下图:
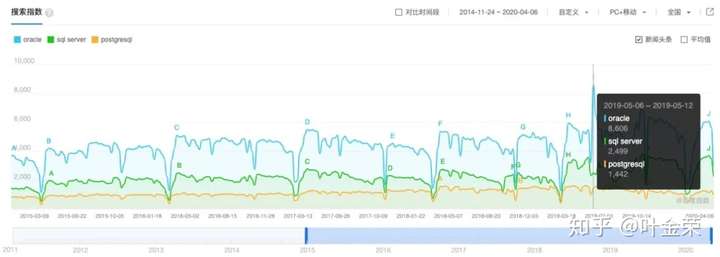
可以看到,在最高点上,PG是SQL Server的57.7%,是Oracle的16.76%。
有些同学可能会说了,我觉得身边很多人在用PG啊。关于这个,可以搜搜什么叫做”孕妇效应“。
再看互联网行业比较常用的MySQL、MongoDB、Redis的数据
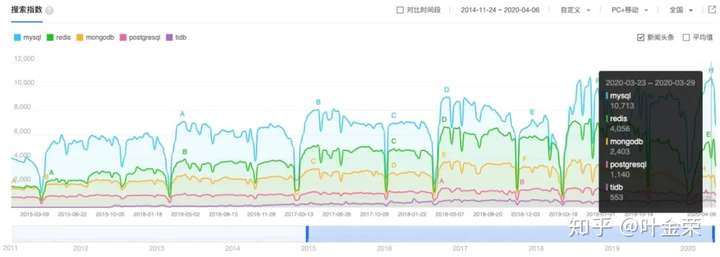
这组数据里,我加上了TIDB,对比度太明显了,不言自明。
到这里,可能有人会疑惑了,为什么MySQL在前有Oracle后有PG的情况下,还能大热起来。
对此,我个人有几点看法:
- 在互联网刚起步时(约2000年),大家选择MySQL是因为它开源、免费、学习成本低、使用成本低、很早就具备主从复制功能以方便架构扩展,所以趁着这波浪潮得到了快速普及。
- 创始人Monty也是非常勤奋的在做普及、布道工作,传说早期他曾经回复了数万个邮件来帮助大家解决使用MySQL的问题。
- 在新的一波去IOE浪潮中,MySQL作为首选,再次站在风口浪尖,PG作为第二梯队也享受了一部分红利。
- 在当前特殊环境下,又掀起一波新的去O运动,MySQL依旧是首选。只不过个别特殊的业务,才要求强制使用国产数据库,不过比例不高。
二、没有分布式
不得不说,很多人存在一个误区,认为在MySQL中,通常只要单表数据量超过千万,就一定要做分库分表,否则就会有很大性能瓶颈。
事实上,绝大多数的性能瓶颈原因在于没把MySQL用好。
我想大概有以下几方面原因:
- 可能是由于最基本的环境部署都没做好,例如还在用ext3/ext4文件系统,并且使用cfq的io scheduler。
- 没有适当的使用索引,造成了大量的行锁等待,以及查询效率低。
- 对MySQL的理解还是一知半解水平,至今还有人迷信用MyISAM引擎的只读性能比InnoDB引擎更快。
- 对MySQL的一些基本参数都没配置好,例如限制了InnoDB线程并发度,结果导致InnoDB大量的任务在排队;或者设置了redo log设置太小,导致频繁的checkpoint平行;或者大量事务长时间不提交,导致大量undo等等。早期甚至还有人用InnoDB的默认参数(innodb buffer pool只有8MB)进行压力测试,从而得到InnoDB是一坨屎的结论。
- 没有能力写出高效的SQL,或者为了图省事采用ORM之类的拼凑SQL,上线之前也没做好充分的压测,可能连基本的索引都没创建,或者创建了大量的单列索引。
符合上面几种情况的,估计只有未来真正的AIDB(人工智能DB)才能解决这个问题了吧,而指望通过换成其他数据库,也只是一厢情愿。
一个行平均长度大约200字节的表,三层高的B+树即可存放将近一亿数据量,在内存充分的前提下,如果能规避上述几个问题,用MySQL还是可以跑得很欢的。
所以,再说一次,MySQL中单表上千万后,并不是一定要做分库分表。
另外,可能有些人会号称某些分布式DB可以支撑几十TB数据量,拜托,能不能先堆积几十TB数据后,拿到TPS、QPS数据再来说?线上生产环境中,要把所有(包含历史)数据堆积一起才真的好吗?与其吹嘘一个集群有多少TB数据,不如吹吹能跑到多少TPS好伐。
当数据量真的特别大需要做分库分表了,国内外也有众多中间件可以支持,不过这时候的数据聚合的确是比较费劲,只能做取舍了。
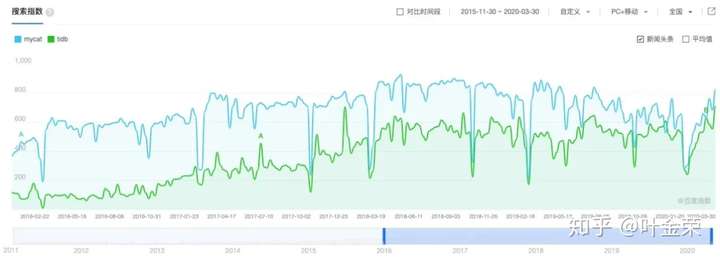
这里放个国内开发者最熟悉的mycat数据作为参考。
三、OLAP性能差
这个就有点过分了。
一个擅长玩咏春拳的,你非让他把太极打好,这不是强人所难是什么?
当然了,也有个别大师真的能同时打好咏春和太极,但他肯定不能到达宗师级。
术业有专攻,就让MySQL先把OLTP做好,做到极致。OLAP的事,要求不是太高的话,还可以用MariaDB的ColumnStore引擎,其前身是InfiniDB。另外,在Oracle云上也已提供这个业务了,阿里云也有分析型数据库,腾讯云最新的TXSQL也即将发布CSTORE分析引擎。
如果要求比较高,则就考虑Elasticsearch、ClickHouse等方案吧,也并不复杂。
写在最后
大家可能会以为本文是特别针对PG或TIDB的,事实肯定不是如此。我之前有篇文章《**MySQL 8.0来了,逆之者亡...**》发布之后,一堆杠精来留言,我只想说下面几句话:
你拿着地球仪跟他说:“你看,地球是圆的吧。” 对方会不屑地说:“这么假的东西都做得出来。” 你为了说服他,去找宇航员在太空拍的地球照片:“喏,你看,地球是圆的吧。” 哪知对方瞪着眼睛说:“你看你看,它不就是平的嘛。” 上面这段话,同样针对本文今天所指的某些调调。最后的最后,没有所谓的银弹,没有哪个数据库能妄想吃下所有蛋糕。把握当下,不管别人怎么说,在学习MySQL的道路上不断精进,站得越高,才能看的更远。我,一如既往的看好MySQL。
全文完。
由我主讲的知数堂「MySQL优化课」第17期已发车,我们的课程从第15期就升级成MySQL 8.0版本了,现在上车刚刚好,一起开启MySQL 8.0的修行之旅吧
另外,叶老师在腾讯课堂《MySQL性能优化》精编版第一期已完结,本课程讲解读几个MySQL性能优化的核心要素:合理利用索引,降低锁影响,提高事务并发度。
下面是自动拼团的链接,组团价仅需78元
https://ke.qq.com/course/479779?from=800004099&tuin=47bb23#term_id=100575214











