
1
背景
本文将用一个蚂蚁集团线上实际案例,分享我们是如何排查由于 inflation 引起的 MetaSpace FGC 问题。
蚂蚁集团的智能监控平台深度利用了 Spark 的能力进行多维度数据聚合,Spark 由于其高效、易用、分布式的能力在大数据处理中十分受欢迎。
关于智能监控的计算能力相关介绍,可以参考《蚂蚁金服在 Service Mesh 监控落地经验总结》 。
2
案例背景
在某次线上问题中出现不间断性的任务彪高与积压,数据产出延迟,非常不符合预期。 查看 SparkUI 的 Event Timeline 发现下边的现象:

大家应该都知道 Spark job 工作节点分为 driver 和 executor,driver 更多的是任务管理和分发,executor 负责任务的执行。在整个 Spark job 生命周期开始时这两种角色被新建出来,存活到 Spark job 生命周期结束。而上图中的情况一般为 executor 因为各种异常情况失去心跳而被主动替换。查看对应 executor 的日志发现有2分钟没有打印,怀疑为 FGC 卡死了。最终在另一个现场找到了 gc 日志:
2020-06-29T13:59:44.454+0800: 55336.665: [Full GC (Metadata GC Threshold) 2020-06-29T13:59:44.454+0800: 55336.665: [CMS[YG occupancy: 2295820 K (5242880 K)]2020-06-29T13:59:45.105+0800: 55337.316: [weak refs processing, 0.0004879 secs]2020-06-29T13:59:45.105+0800: 55337.316: [class unloading, 0.1113617 secs]2020-06-29T13:59:45.217+0800: 55337.428: [scrub symbol table, 0.0316596 secs]2020-06-29T13:59:45.248+0800: 55337.459: [scrub string table, 0.0018447 secs]: 5326206K->1129836K(8388608K), 85.6151442 secs] 7622026K->3425656K(13631488K), [Metaspace: 370361K->105307K(1314816K)], 85.8536592 secs] [Times: user=88.94 sys=0.07, real=85.85 secs]
观察到因为 Metadata 的原因,导致 FGC,整个应用冻结80秒。众所周知 Metadata 主要存储一些类等相关的元信息,其应该是相对恒定的,那么究竟是什么原因导致了 MetaSpace 的变化,让我们一探究竟。
3
排查过程
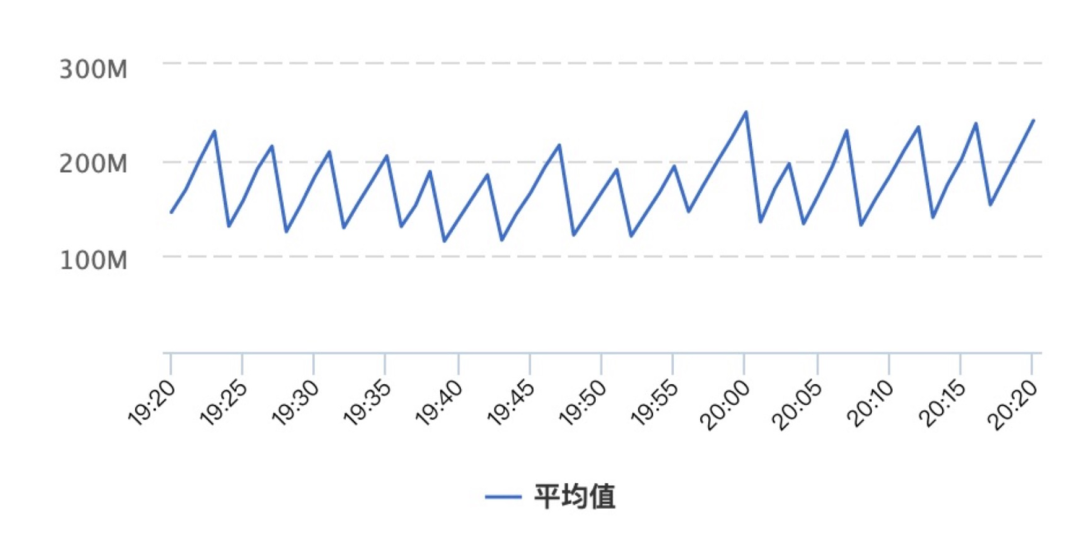
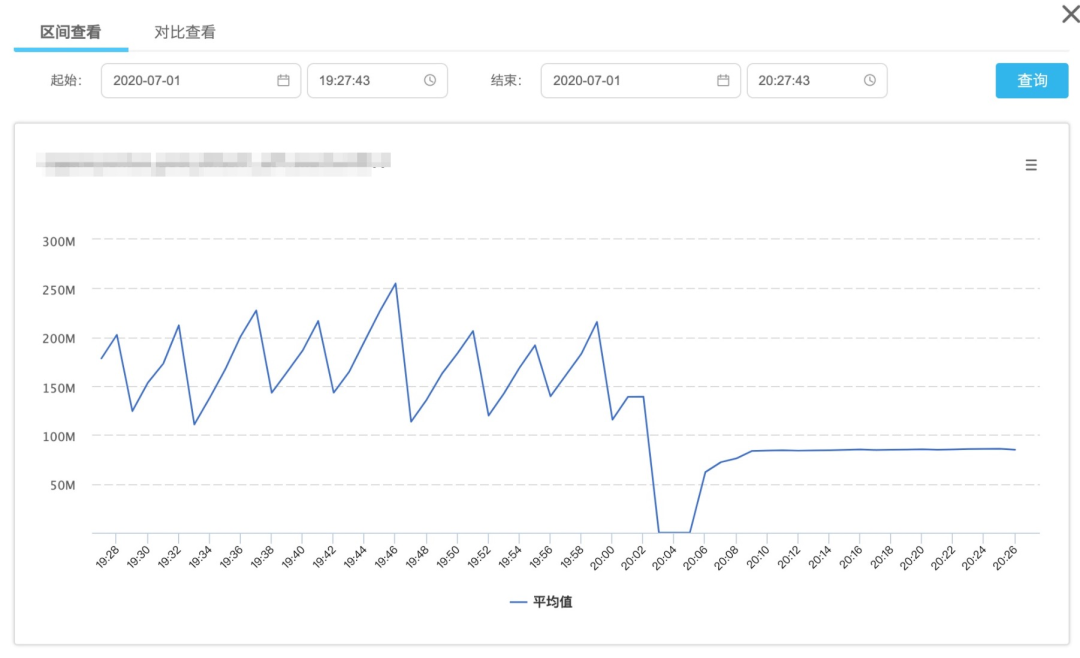
MetaSpace 的目前参数为 -XX:MetaspaceSize=400m -XX:MaxMetaspaceSize=512m 这个已经非常多了,查看监控,发现 MetaSpace 的曲线如下图的锯齿状,这个说明不断的有类对象生成和卸载,在极端情况会到 400m 以上,所以触发 FGC 是符合常理的。 但是整个应用的生命周期中,理论上不应该有大量的类在不断的生成和卸载。
先看下代码,是否有类动态生成,发现有2个地方比较可疑:
QL 表达式,这个地方会有动态的类生成;
关键路径上泛型的使用;
但是经过排查和验证,发现这些都不是关键的点,因为虽然是泛型但类的数量是固定的,并且 QL 表达式有 cache。
最终定位到一个 Spark 算子,发现一个现象:每次执行 reduce 这个操作时都会有大量的类对象生成。
那么可以大胆的猜测:是由于 reduce 时发生 shuffle,由数据的序列化和反序列化引起。
添加启动参数,-XX:+TraceClassLoading -XX:+TraceClassUnloading ,在类加载和卸载的情况下可以看到明细信息,同时对问题现场做内存 dump,发现有大量的 DelegatingClassLoader,并动态的在内存中生成了 sun.reflect.GeneratedSerializationConstructorAccessor 类。
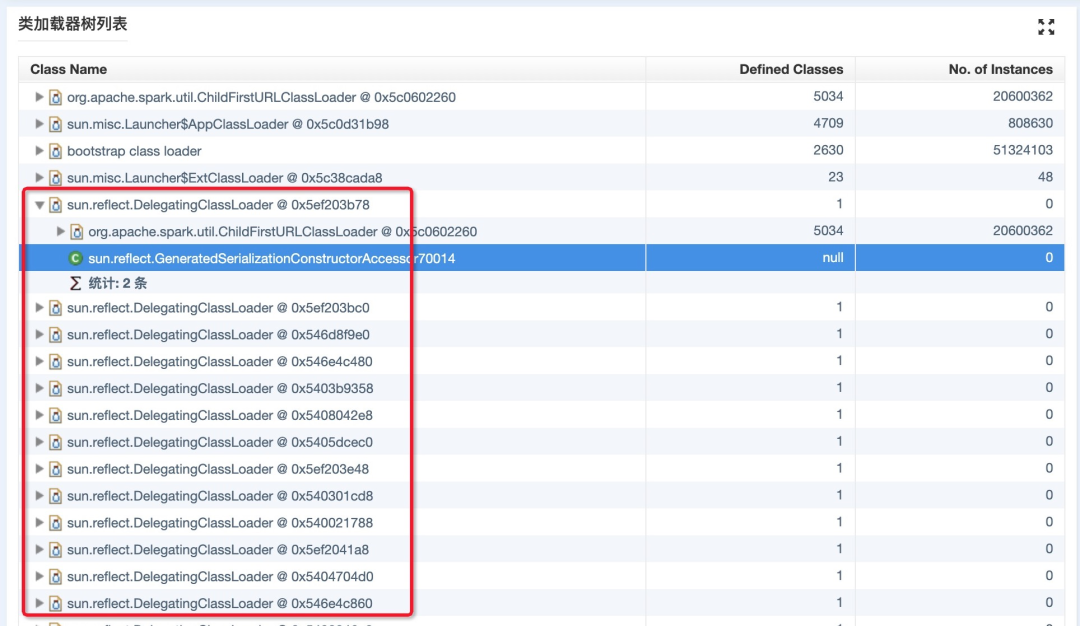
那么,很明显引起 MetaSpace 抖动的原因就是 DelegatingClassLoader 生成了很多 ConstructorAccessor 对应的类对象,这个类是动态生成的,保存在内存中,无法找到原型。
为了查看内存中这个类的具体信息,找到原型,这里用到了一个非常强大的工具:arthas,arthas 是 Alibaba 开源的 Java 诊断工具,推荐每一位研发人员学习,具体教程见 :
https://alibaba.github.io/arthas/quick-start.html
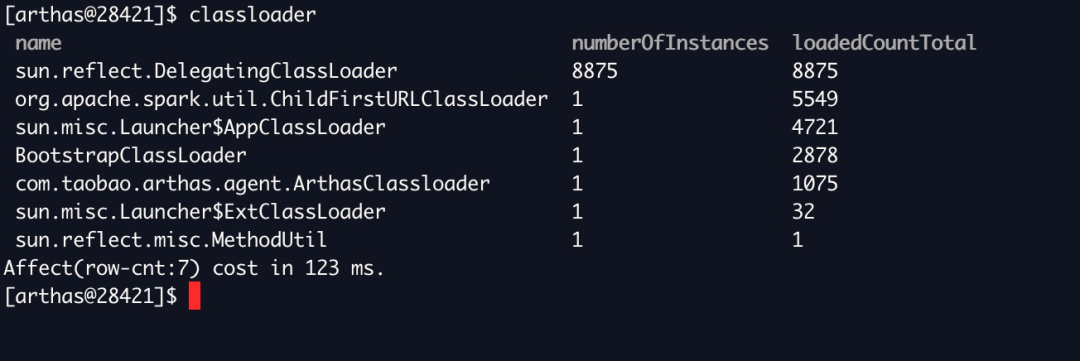
arthas 可以很方便的观察运行中的 JVM 的各种状态,找一个现场用 classloader 命令观察,发现有好几千 DelegatingClassLoader:
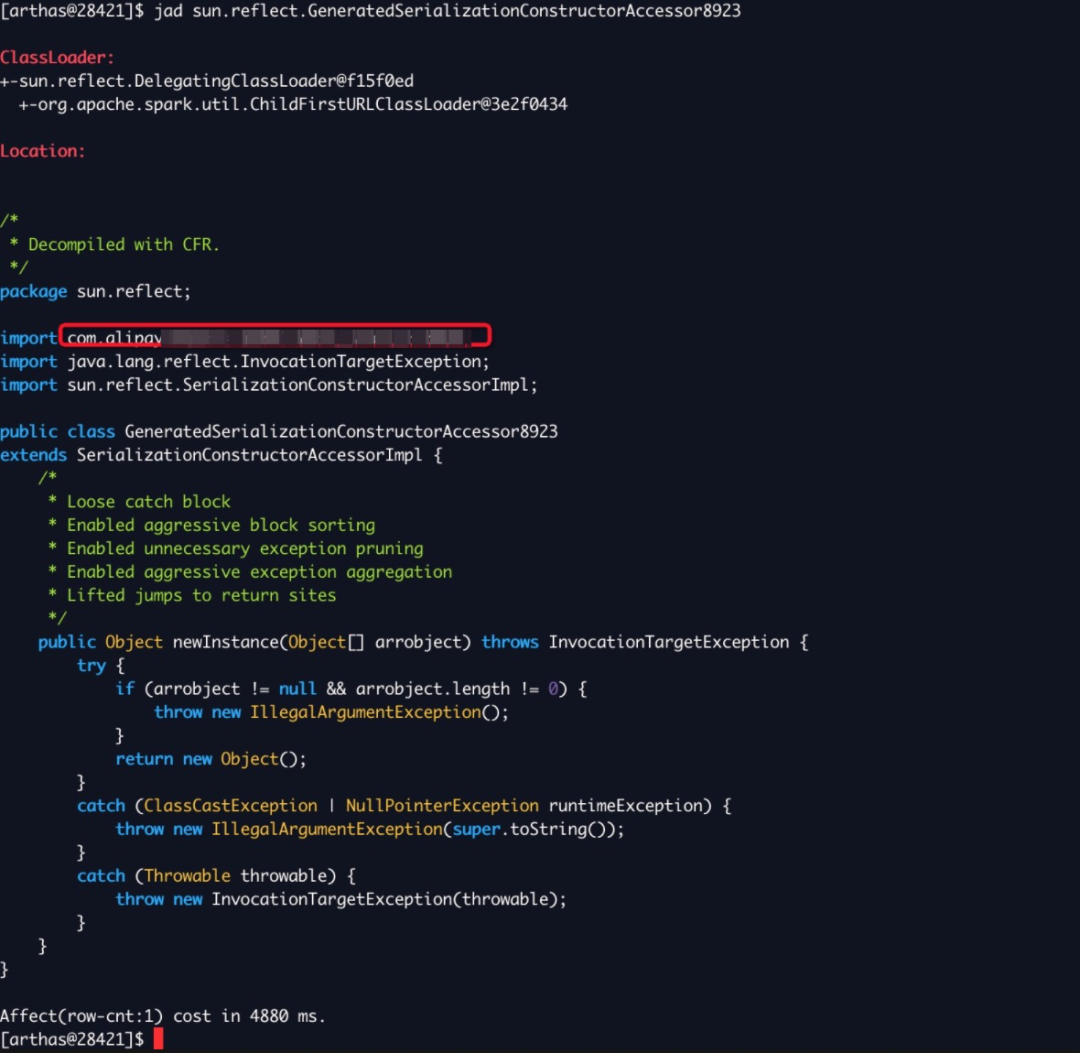
随便挑一个 DelegatingClassLoader 下的类反序列化看下,整个类没什么特别的,就是 new 一个对象出来,但是有个细节:引入了 com.alipay 这个包下的类,这个地方应该能提供什么有用的信息。
我们尝试把所有 GeneratedSerializationConstructorAccessor 的类 dump 下来做下统计,OpenJDK 可以做 ClassDump,找了下社区发现个小工具:
https://github.com/hengyunabc/dumpclass
java -jar dumpclass.jar -p 1234 -o /home/hadoop/dump/classDump sun.reflect.GeneratedSerializationConstruc*
可以看到导出了大概 9000 个 GeneratedSerializationConstructorAccessor 相关的类:

用 javap 反编译后做下统计:
find ./ -name "GeneratedSerializationConstructorAccessor*" | xargs javap -verbose | grep "com.alipay.*" -o | sort | uniq -c

发现有的类只生成 3 次,有的上千次,那么他们区别是什么?对比下发现差别在是否有默认的构造函数。
4
根因分析
根因是由于在反序列化时触发了 JVM 的“inflation”操作,关于这个术语,下边这个解释非常通俗易懂:
“When using Java reflection, the JVM has two methods of accessing the information on the class being reflected. It can use a JNI accessor, or a Java bytecode accessor. If it uses a Java bytecode accessor, then it needs to have its own Java class and classloader (sun/reflect/GeneratedMethodAccessor class and sun/reflect/DelegatingClassLoader). Theses classes and classloaders use native memory. The accessor bytecode can also get JIT compiled, which will increase the native memory use even more. If Java reflection is used frequently, this can add up to a significant amount of native memory use. The JVM will use the JNI accessor first, then after some number of accesses on the same class, will change to use the Java bytecode accessor.This is called inflation, when the JVM changes from the JNI accessor to the bytecode accessor. Fortunately, we can control this with a Java property. The sun.reflect.inflationThreshold property tells the JVM what number of times to use the JNI accessor. If it is set to 0, then the JNI accessors are always used. Since the bytecode accessors use more native memory than the JNI ones, if we are seeing a lot of Java reflection, we will want to use the JNI accessors. To do this, we just need to set the inflationThreshold property to zero.”
由于 spark 使用了 kryo 序列化,翻译了相关代码和文档:
InstantiatorStrategy
Kryo provides DefaultInstantiatorStrategy which creates objects using ReflectASM to call a zero argument constructor. If that is not possible, it uses reflection to call a zero argument constructor. If that also fails, then it either throws an exception or tries a fallback InstantiatorStrategy. Reflection uses setAccessible , so a private zero argument constructor can be a good way to allow Kryo to create instances of a class without affecting the public API. DefaultInstantiatorStrategy is the recommended way of creating objects with Kryo. It runs constructors just like would be done with Java code. Alternative, extralinguistic mechanisms can also be used to create objects. The Objenesis StdInstantiatorStrategy uses JVM specific APIs to create an instance of a class without calling any constructor at all. Using this is dangerous because most classes expect their constructors to be called. Creating the object by bypassing its constructors may leave the object in an uninitialized or invalid state. Classes must be designed to be created in this way. Kryo can be configured to try DefaultInstantiatorStrategy first, then fallback to StdInstantiatorStrategy if necessary. kryo.setInstantiatorStrategy(new DefaultInstantiatorStrategy(new StdInstantiatorStrategy())); Another option is SerializingInstantiatorStrategy, which uses Java's built-in serialization mechanism to create an instance. Using this, the class must implement java.io.Serializable and the first zero argument constructor in a super class is invoked. This also bypasses constructors and so is dangerous for the same reasons as StdInstantiatorStrategy. kryo.setInstantiatorStrategy(new DefaultInstantiatorStrategy(new SerializingInstantiatorStrategy()));
结论很清晰:
如果 Java 对象有默认的构造函数,DefaultInstantiatorStrategy 调用 Class.getConstructor().newInstance() 构建出来。在这个过程中 JDK 会将构造出来的 constructor accessor 缓存起来,避免反复生成。
否则 StdInstantiatorStrategy 调用 Java 的特殊 API(如下图的 newConstructorForSerialization)直接生成对象而不通过构造函数。
相关的代码在:
org.objenesis.instantiator.sun.SunReflectionFactoryHelper#getNewConstructorForSerializationMethod
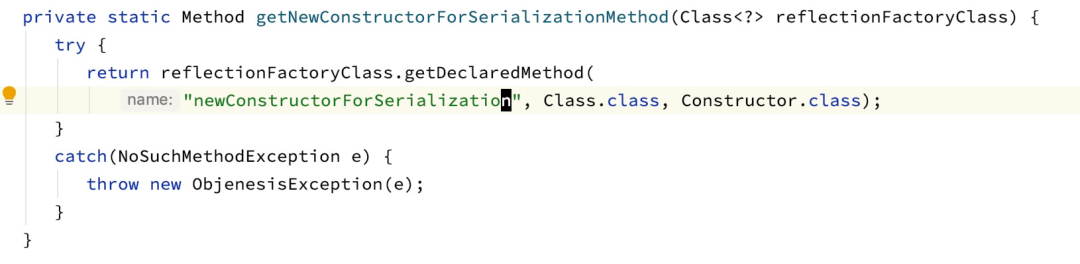
这个过程中没有 cache 的过程,导致不断的生成 constructor accessor,最后发生 inflation 生成了非常多的Metadata。
**5
**
总结
inflation 是一个比较冷门的知识,但是每一个研发应该都会在有意无意见遇到它。 那么在使用反射的能力时、甚至是第三方库在大量使用反射来实现某些功能时,都需要我们去注意和思考。
同时,问题的排查是需要按逻辑去思考和渐进寻找根因的,脑袋一团乱麻只会走不少弯路,引以为戒。最后本文问题通过添加私有构造函数后解决,MetaSpace 监控空锯齿状消失:
作者介绍
凌屿,高级开发工程师,一直从事智能监控相关研发工作,在海量数据清洗、大数据集处理、分布式系统建设等有深入研究。
6
关于我们
欢迎来到「蚂蚁智能运维」的世界。 本公众号由蚂蚁集团技术风险中台团队出品,面向关注智能运维、技术风险等技术的同学,将不定期与大家分享云原生时代下蚂蚁集团在智能运维的架构设计与创新方面的思考与实践。
蚂蚁技术风险中台团队,负责蚂蚁集团的技术风险底座平台建设,包括智能监控、资金核对、性能容量、全链路压测以及风险数据基础设施等平台和业务能力建设,解决世界级的分布式处理难题,识别和解决潜在的技术风险,参与蚂蚁双十一等大型活动,通过平台能力保障整体蚂蚁系统在极限请求量下的高可用和资金安全。
关于「智能运维」有任何想要交流、讨论的话题,欢迎留言告诉我们。
PS:技术风险中台正在招聘技术专家,欢迎加入我们,有兴趣联系 techrisk-platform-hire@list.alibaba-inc.com

🎉 欢迎****支持关注「智能运维」的你~
* 点下右下角“在看”
* 到公众号对话框发送“智能运维”,试试手气~
* 本期互动奖品“蚂蚁公仔”

本文分享自微信公众号 - 蚂蚁智能运维(gh_a6b742597569)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。






