前言:
网络渗透中,网站一直是黑客们重点攻击的目标。面对网站,攻击者经常会想找到网站后台,登录上去,从而进一步获得网站服务器控制权。

所以,如何获得网站后台登录地址,就是非常重要的第一步。
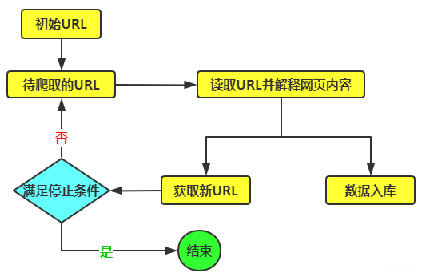
爬虫分析
爬虫分析的原理,是通过分析网站页面的HTML源代码,从里面不断爬取链接,分析潜在的后台登录地址。一般来说,后台登录页面的地址中,通常会出现login、admin、user等字样。

字典枚举
很多时候,通过爬虫难以获取到后台登录地址,因为有可能存在没有任何一个页面里面包含登录页面的链接的情况。这个时候,咱们还可以借助字典的方式,进行枚举发起请求观察返回情况。现在很多网站都是用的一些公共的开源博客、BBS、CMS等框架打出来的,比如Discuz!等,而这些开源的项目后台登录页面名字都是固定的,如果网站搭建者没有自己更改,那就非常容易拿到这个地址。
一个强大的字典包含了几万十几万的常用后台登录地址特征,通过枚举就可能找到后台登录地址。
暴力枚举
最后这种顾名思义,暴力枚举!字典枚举的核心在于要有一个强大的字典,但如果目标后台登录地址不在字典中,那就无能为力了。爬虫和字典都无能为力的情况下,就只能靠暴力枚举了,就跟试密码一样,字符组合,没啥好说的。
说完了三种方法,那小伙伴们肯定想问了,有没有什么工具呢?有,当然有,而且还不止一款。接下来就给大家介绍几款当下黑客们最常用的网站扫描工具。
DirBuster
DirBuster是OWASP(开放Web安全项目- Open Web Application Security Project)开发的一款专门用于探测Web服务器的目录和隐藏文件。
由于使用Java编写,电脑中要装有JDK才能运行。
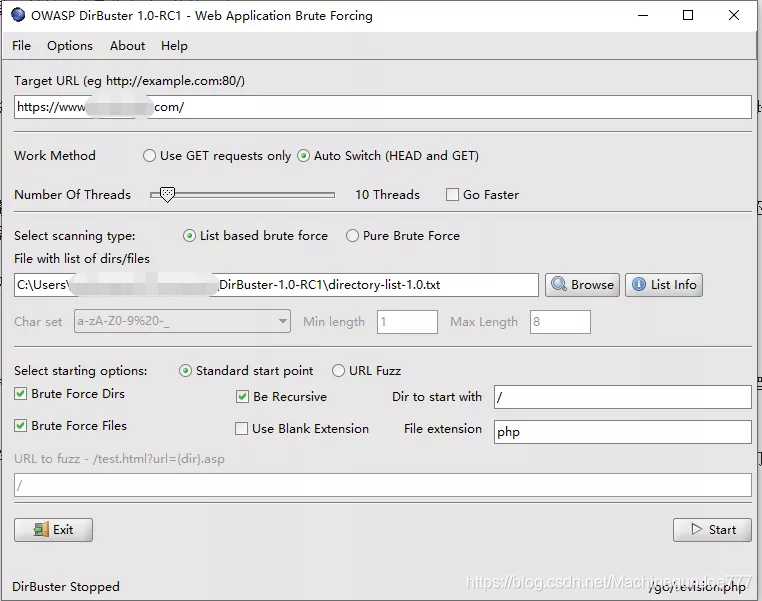
输入网站地址,进行一些简单配置,就能开始扫描。同时支持基于字典的扫描和暴力枚举。
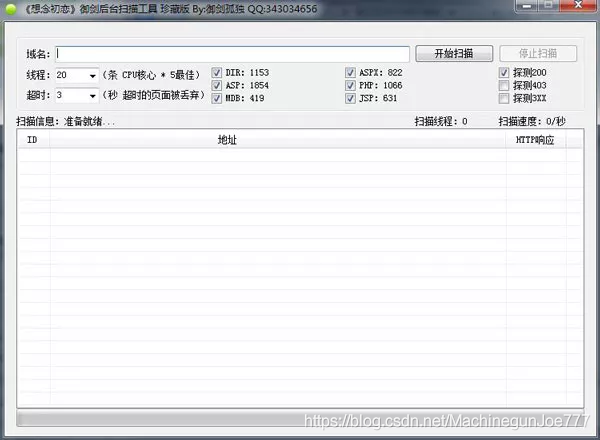
御剑
听名字,御剑就是咱们国人写的,出自大牛御剑孤独,同样支持字典枚举,比起DirBuster,御剑更加得简洁轻便,操作起来非常得心应手。
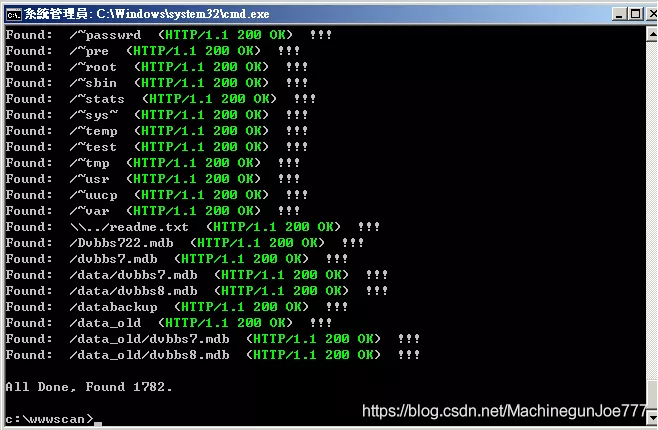
wwwscan
wwwscan算是一个老牌的后台扫描工具了,界面更加简单,支持命令行和可视化界面两种模式:
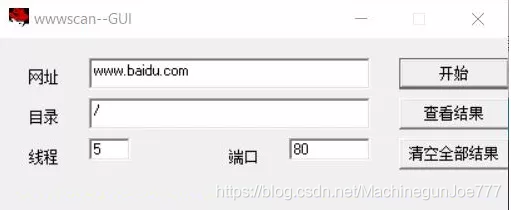
在命令行模式下,支持参数:
-p:设置端口号
-m:设置最大线程数
-t:设置超时时间
-r:设置扫描的起始目录
-ssl:是否使用SSL
使用命令示例:
- wwwscan.exe www.baidu.com -p 8080 -m 10 -t 16
- wwwscan.exe www.baiadu.com -r "/test/" -p 80
- wwwscan.exe www.baidu.com –ssl
除了用这些工具,Google Hacking也常常用来进行后台扫描。比如使用inurl语法进行搜索:
- inurl:login.php
- inurl:login.jsp
- inurl:login.asp
通过这些工具,就能轻松找到网站后台地址啦。