
Docker基本介绍
一.什么是Docker
在docker的官方之什么是docker中提到了一句话:“当今各大组织或者团体的创新都源于软件(例如OA、ERP等),其实很多公司都是软件公司"。用户量的激增导致了并发、指数级增加的数据、应用的可靠性等问题,单体应用已经应对不了这些问题,于是诞生了分布式、集群、微服务、边缘计算等各种名词、架构风格和满足这种架构风格的各种框架,那我们接下来跟大家谈谈这些技术名词。
分布式:将一个复杂的应用按照模块进行拆分,每个拆分的模块做成一个应用,分开部署,分开运行,各个模块之间通过webservice、http rest、rpc的方式进行调用。但是分布式系统中面临着很多棘手的问题:1. 如果某一个应用crash掉了,会导致调用该模块的其他模块也无法正常工作;2. 因为网络抖动或者硬件的问题导致数据的一致性问题(即分布式事务问题);3. 运维和硬件成本的急剧上升。
集群:集群是指将某一个应用或者某个模块部署在多台机器上(这些机器上跑的代码是相同的),然后通过负载均衡的方式让每个应用都能处理请求,即使某一个应用宕掉了,其他的应用一样可以处理请求,集群是为了解决我们上面提到的分布式应用中的第一个问题,但是集群也面临着诸多的问题:1. 运维和硬件成本的急剧增加;2. 实现集群势必会引入第三方的插件,那么第三方插件如何去保障其稳定运行;
微服务:微服务只是一种架构风格,最早是由Martin Fowler(博客点击这里)提出,他对微服务的解释是:In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies(简而言之,微服务是一种架构的风格,将每一个单独的应用来作为一个服务套件,每一个服务套件运行在其独立的进程当中,使用轻量级的方式相互调用,通常采用HTTP的方式。这些个服务是要建立在业务能力和自动化独立部署的基础上的。这些服务间应该以一种去中心化的方式运行,而且这些服务可以使用不同的语言、不同的存储机制来实现)。我用自己的话来表达一下,所谓的微服务就是将一个可以独立部署、业务能力独立的应用,应用之间耦合度尽量降低(只能尽量降低,不可能实现绝对的解耦),尽可能的去中心化。微服务也同样的面临着诸多的问题:1. 分布式事务问题;2. 运维和硬件成本急剧上升。
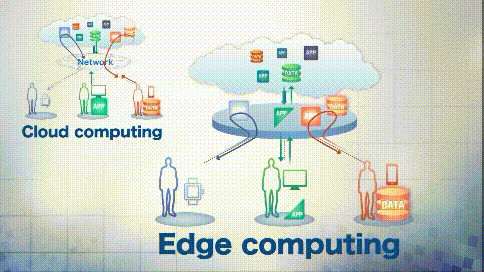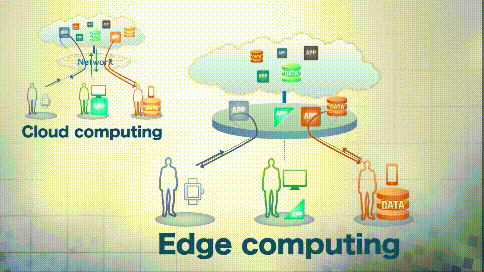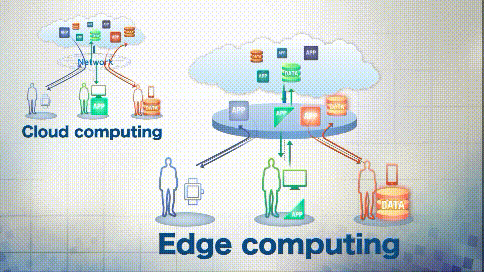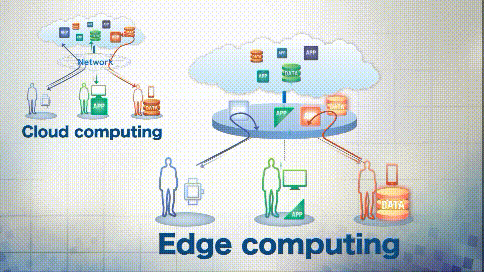
边缘计算:首先跟大家说一下,为什么要在这里提到边缘计算呢?因为本文讲的是docker, docker中提到了边缘计算。所谓的边缘计算是指在接近数据源的地方进行数据的处理,而不是将数据集中到一起进行处理,边缘计算可以实现数据的实时分析,将有价值的数据过滤后丢给云端。下面给一张图方便大家的理解:
我们在回到本节标题“什么是docker”,我们在介绍完上面这些名词后,会发现无论当今所流行的不论是分布式、集群还是微服务都面临着一个问题:运维和硬件成本的急剧上升。那么docker的出现就是为了解决这个问题:解决运维和硬件成本的问题。
提到这里笔者结合自己的工作经历跟大家讲解一下我以前在某家公司是如何解决这个问题的,我们公司购买一台服务器,然后在服务器上虚拟出多个计算机,然后在虚拟的机器上部署我们的应用,所谓虚拟机是借助于一些软件虚拟出一台和我们的物理机一样的机器,也有CPU、内存、硬盘、光驱等。虽然我们可以在一台真实的物理机上虚拟出多台机器,但是每个机器上其实都是有一套完整的操作系统,那么多台虚拟机上就有多套操作系统,这些操作系统也是要消耗物理机的资源的,那么如何解决这个问题呢?这同样回到我们该节的主题“什么是docker”。

二. docker能解决什么问题
其实这个问题,我们在第一节“什么是docker”这个章节已经给出了答案。在本节我们会给出系统的总结:
2.1 资源的复用
上节笔者说到我们公司在解决运维和机器成本问题的时候说到,通过传统的虚拟机的方式每一台虚拟机都有一套完整的操作系统,那么我们能不能就使用一个操作系统,每个隔离的进程只运行我们的应用和所依赖的第三方软件,docker恰恰可以解决这个问题。
2.2 一致的环境
我相信做过开发的朋友都有这样的经历,我们在本地开发一个应用,尤其是分布式应用,我们需要在本地安装多台虚拟机,在本地测试各种功能完好。接着修改各种参数后辛辛苦苦部署到测试机上后,测试的同事经过紧张、严谨的测试,一切都那么的prefect。当我们高高兴兴的修改完各种参数后部署到生产环境,我嘞个擦,各种问题都出现。开发人员经常挂在嘴边的几句话“昨天我跑着还是好好的呀”,“测试的时候还是好好的呀”,导致开发人员说这些话的原因是因为开发、测试、生产环境的不一致所导致的。docker也可以解决这个问题,docker的镜像提供了除内核以外完整运行环境,确保的环境的一致性。
2.3 启动速度更快
以往的虚拟机的方式启动的时候需要的时间会很长,因为要启动操作系统,可能需要几分钟甚至更长。但是docker启动只需要几秒、几毫秒。
2.4 应用的迁移
给朋友举个例子,以前你的应用部署在阿里云上,那么那天你的领导需要将应用签署到腾讯云上,使用docker的话,会变得非常的简单。












