大家好,我是黄伟。今天给大家介绍芒果数据库,一起来看看吧。
前言
Mongodb,分布式文档存储数据库,由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个高性能,开源,无模式的文档型数据库,是当前NoSql数据库中比较热门的一种。它在许多场景下可用于替代传统的关系型数据库或键/值存储方式。下面我们来说说它的具体用法吧。
一、安装配置
1.下载
下载地址如下:
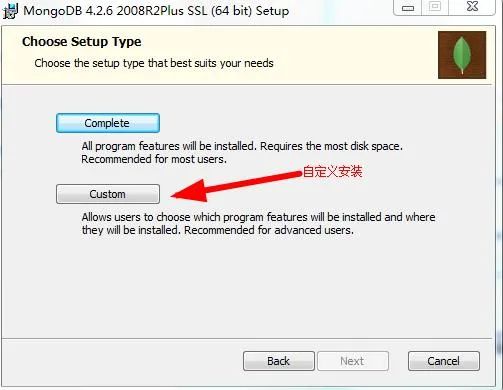
https://590m.com/file/7715018-442253530然后点击msi安装文件进行安装,由于比较大,建议不要安装在C盘,选择下图中的选项哦。
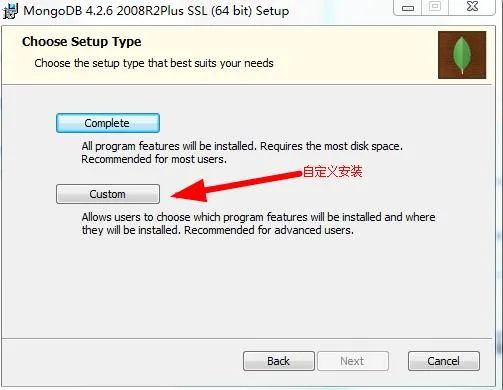
在这里我选择的是E:\mongodb,按着步骤来,整体来说比较简单,唯一需要注意的是,有一个选项不能勾选,如下图:
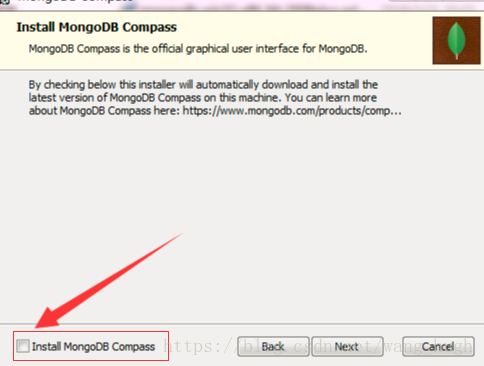
2.配置文件
创建E:\mongodb\data\log目录,用来存放日志文件;
在E:\mongodb\data\log目录里新建mongodb.log,用来存放日志信息;
创建E:\mongodb\data\db目录,用来存放数据库数据;
并在E:\mongodb目录下创建mongo.config,在文件内部复制如下文本:
#数据文件 此处=后对应到数据所存放的目录
dbpath=E:\mongodb\data\db
#日志文件 此处=后对应到日志文件所在路径
logpath=E:\mongodb\data\log\mongodb.log
#错误日志采用追加模式,配置这个选项后mongodb的日志会追加到现有的日志文件,而不是从新创建一个新文件
logappend=true
#启用日志文件,默认启用
journal=true
#过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
#端口号 默认为27017
port=270173.配置环境变量
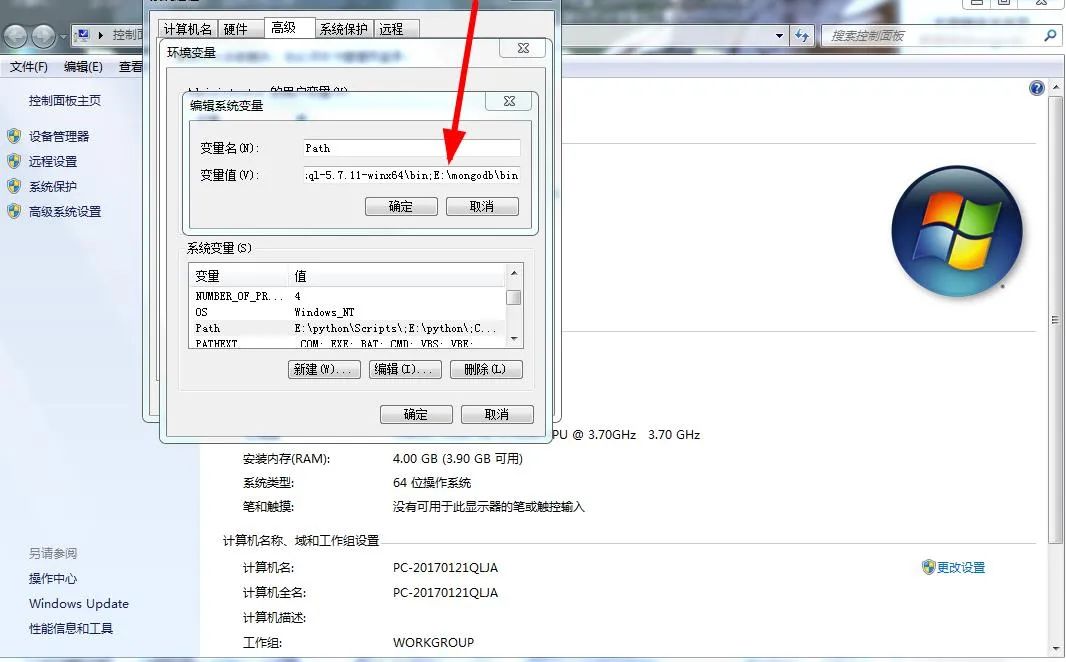
4.创建数据库文件存放位置
进入命令提示符,键入如下命令:
mongod.exe --dbpath E:\mongodb\data\db--dbpath 是创建数据库文件的存放位置,mongo需要确认该目录位置
5.验证可否正常访问
我们在浏览器中输入以下的网站:
http://localhost:27017/如图:

浏览器返回这样一串英文即表示mongodb数据库成功启动。
但是每次这样才能启动太麻烦,我们可以将它添加到系统任务中,让它开机自启动啊。
6.安装日志文件和服务名
C:\Users\Administrator>mongod.exe --dbpath E:\mongodb\data\db -logpath E:\mongo
db\data\log\mongodb.log -install -serviceName "MongoDB"如果它显示已存在,如图:
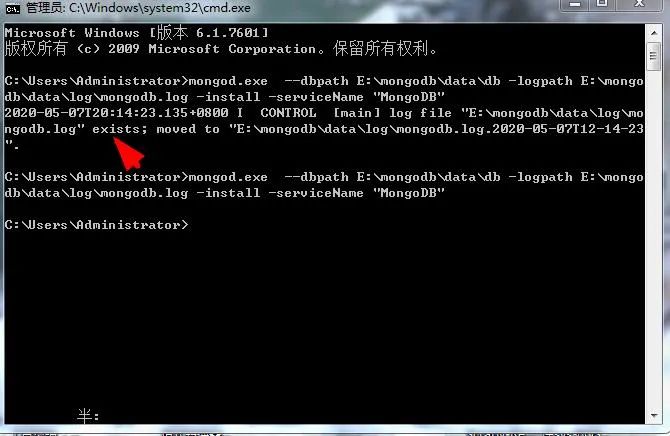
那么,先删除服务:
sc delete MongoDB再次输入上个命令就好了。
7.启动mongodb
然后我们将它启动起来:
net start MongoDB可以看到启动成功了,不容易啊。

关闭mongodb服务:
net stop MongoDB二、mongodb的数据库增删改查
众所周知,mongodb没有表这个概念,存储都是靠集合来完成,因此我们需要创建的是集合。
我们先看看mongodb最常见的数据库操作,首先 打开命令提示符,输入如下命令进入环境:
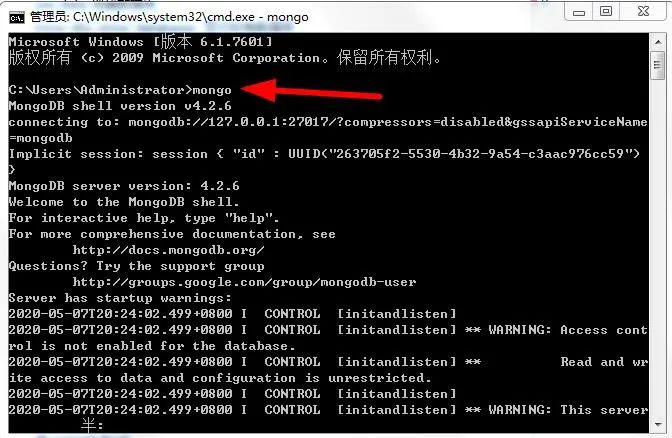
// 创建数据库
use data
//显示所有数据库
show dbs
show databases
//查看当前数据库
db
db.getName()
// 删除当前数据库
db.dropDatabase()
//修复当前数据库
db.repairDatabase()
//从指定的机器上复制指定数据库数据到某个数据库
db.copyDatabase("my_db", "you_db", "127.0.0.1")
//从指定主机上克隆数据库
db.cloneDatabase(“127.0.0.1”)
//创建集合 固定集合大小为100 最大数值1000
db.createCollection('student',{capped:true,size:100,max:1000})
//显示所有集合
show collections
//得到当前db的所有聚集集合
db.getCollectionNames()
//显示当前db所有聚集索引的状态
db.printCollectionStats()
//删除集合
db.hw.drop()
//得到指定名称的聚集集合
db.getCollection("hw")
//插入集合 _id存在就报错
db.hw.insert({_id:0001,'name':'hw','age':10})
//显示集合内容
db.hw.find()
//显示一条集合内容
db.hw.findOne()
//格式化显示集合内容
db.hw.find().pretty()
//保存集合_id存在就更新
db.hw.save({_id:0001,'name':'hw','age':10})
//更新集合
$set 指定键并更新 不存在则创建 $unset 删除
db.hw.update({'name':'hw'},{'name':'xz'}) //更新一条数据替换
db.hw.update({'name':'hw'},{$set{'name':'xz'}}) //更新一条数据更新
db.hw.update({'name':'hw'},{'name':'xz'},{multi:true}) //更新全部数据
//删除集合数据
db.hw.remove({'name':'hw'},{justOne:true}) //删除一条数据
db.hw.remove({'name':'hw'},{justOne:false}) //删除全部数据
//集合重命名
db.user.renameCollection("hw"); 将user重命名为hw
//查询数据
$lt--小于 $lte--小于等于
$gt--大于 $gte--大于等于
$ne--不等于 $in $nin--是否处在该范围
$and $or 查询条件与或
$type
/^abc/ $regex:'abc$' 正则表达式
limit(num) 显示指定数量的结果
skip(num) 跳过指定数量的结果
$where 查询函数
_id默认显示,不显示则把值设为0
sort() 排序,参数为1升序 -1 降序
count() 统计查询结果数量 也可把查询参数放进count中
distinct() 消除重复数据
db.hw.find({age:{$gte:18}})
db.hw.find({age:{$in:[12,32,21]}})
db.hw.find({$and:{age:{$in:[12,32,21]},{age:{$gte:18}}}})
db.hw.find({age:{$gte:18}}).skip(3).limit(2)
db.hw.find({age:/^abc/,name:{$regex:'123$'}})
db.hw.find($where:function(){return this.age<=19})
db.hw.find({age:{$gte:18}}).sort({age:1})
db.hw.distinct({age:{$gte:18}})三、索引
//建立唯一值的索引
db.hw.ensureIndex({name:1},{'unique':true}) //1升序 -1降序
db.hw.find({name:'he'}).explain('executionStats') //获取时间
//查看集合中所有索引
db.hw.getIndexes()
//删除索引
db.hw.dropIndex('name')
//重建索引
db.hw.reIndex()四、数据聚合
//数据聚合
$group分组 $match过滤数据 $project修改文档结构
$sort排序 $limit指定数量 $skip 跳过
$unwind 拆分数组类型的字段 $pushAll
$sum 和 $avg 平均值 $push 添加值至数组
$pop $addToSet $pull $rename $bit
$first开头 $last结尾 $min $max
db.hw.aggregate({$group:{_id:'$name',count:{$sum:1},avg_age:{$avg:'$age'}}}
,{$project:{name:'$_id',count:'$count',avg_age:'$avg_age'}},
{$match:{age:{$gt:20}}},{$unwind:{'$age',preserveNullAndEmptyArrays:true}} //true保留缺失值
)五、数据备份与恢复
//备份数据
mongodump -h dbhost -d dbname -o dbdirectory
-h 服务器地址
-d 需要备份的数据库名称
-o 备份数据库存放位置
//数据恢复
mongorestore -h dbhost -d dbname --dir dbdirectory
-h 服务器地址
-d 需要恢复的数据库实例
--dir 备份数据所在位置六、数据监控
//监控
Mongostat 检测数据库状态
Mongotop sleeptime - -locks 跟踪一个MongoDB的实例七、高级查询
<,>,>=,<=
这四个就不用解释了,最常用的,也是最简单的。
db.collection.find({ "field" : { $gt: value } } ) // 大于 : field > value
db.collection.find({ "field" : { $lt: value } } ) // 小于 : field < value
db.collection.find({ "field" : { $gte: value } } ) // 大于等于 : field >= value
db.collection.find({ "field" : { $lte: value } } ) // 小于等于 : field <= value
如果要同时满足多个条件,记得要这样用:
db.collection.find({ "field" : { $gt: value1, $lt: value2 } } ) // value1 < field < value
$ne 不等于
db.things.find( { x : { $ne : 3 } } )
条件相当于x<>3,即x不等于3。
$mod 取模运算
db.things.find( { a : { $mod : [ 10 , 1 ] } } )
条件相当于a % 10 == 1 即a除以10余数为1的。
$nin 不属于
db.things.find({j:{$nin: [2,4,6]}})
条件相当于 j 不等于 [2,4,6] 中的任何一个。
$in 属于
db.things.find({j:{$in: [2,4,6]}})
条件相当于j等于[2,4,6]中的任何一个。
$all 全部属于
db.things.find( { a: { $all: [ 2, 3 ] } } )
与$in类似,但必须是[]的值全部都存在。
$size 数量,尺寸
db.things.find( { a : { $size: 1 } } )
条件相当于a的值的数量是1(a必须是数组,一个值的情况不能算是数量为1的数组)。
$exists 字段存在
db.things.find( { a : { $exists : true } } )
db.things.find( { a : { $exists : false } } )
true返回存在字段a的数据,false返回不存在字段a的数据。
$type 字段类型
db.things.find( { a : { $type : 2 } } )
条件是a类型符合的话返回数据。
参数类型如下图:
Type Name Type Number
Double 1
String 2
Object 3
Array 4
Binary data 5
Object id 7
Boolean 8
Date 9
Null 10
Regular expression 11
JavaScript code 13
Symbol 14
JavaScript code with scope 15
32-bit integer 16
Timestamp 17
64-bit integer 18
Min key 255
Max key 127
Regular Expressions 正则表达式
db.customers.find( { name : /acme.*corp/i } )
类似sql中的like方法。
行开始 /^ 行结束 $/
这里要特别特别特别地注意一点,关乎查询效率:
While /^a/, /^a./, and /^a.$/ are equivalent and will all use an index in the same way, the later two require scanning the whole string so they will be slower. The first format can stop scanning after the prefix is matched.
意思大概就是指在查询以a开头字符串时,可以有三种形式, /^a/, /^a./,和/^a.$/ 。后面两种形式会扫描整个字符串,查询速度会变慢。第一种形式会在查到符合的开头后停止扫描后面的字符。
所以要特别注意。
几个附加参数:
i的意思是忽略大小写。(这个很重要,很常用)
m的意思是支持多行。(不过ME没有尝试过)
x的意思是扩展。(也没用过)
$or 或 (注意:MongoDB 1.5.3后版本可用)
db.foo.find( { $or : [ { a : 1 } , { b : 2 } ] } )
符合条件a=1的或者符合条件b=2的数据都会查询出来。
与其它字段一起查询:
db.foo.find( { name : "bob" , $or : [ { a : 1 } , { b : 2 } ] } )
符合条件name等于bob,同时符合其它两个条件中任意一个的数据。
Value in an Array 数组中的值
例如数据库中存在这样的数据:
{ "_id" : ObjectId("4c503405645fa23b31e11631"), "colors" : [ "red", "black" ] }
查询
db.things.find( { colors : "red" } );
即可查到上面那条数据。
$elemMatch 要素符合
t.find( { x : { $elemMatch : { a : 1, b : { $gt : 1 } } } } )
结果:
{ "_id" : ObjectId("4b5783300334000000000aa9"),
"x" : [ { "a" : 1, "b" : 3 }, 7, { "b" : 99 }, { "a" : 11 } ]
}
x其中一个要素符合那个检索条件就可以被检索出来。(不过一般谁用像x这样的结构去保存数据呢?)
Value in an Embedded Object 内嵌对象中的值
例如数据库中存在这样的数据:
{ "_id" : ObjectId("4c503773645fa23b31e11632"), "author" : { "name" : "Dan Brown", "age" : 38 }, "book" : "The Lost Symbol" }
查询:
db.postings.find( { "author.name" : "Dan Brown" } );
即可查到上面那条数据。
查询内嵌对象的属性,记得要加上“”,字段是“author.name”,而不是author.name。
$not 不是
db.customers.find( { name : { $not : /acme.*corp/i } } );
这是一个与其它查询条件组合使用的操作符,不会单独使用。
只要你理解了前面的查询操作即可,只是再加上了$not,结果就是得到了没有$not的相反结果集。
sort() 排序
这个非常实用。即sql语言中的OrderBy。
db.myCollection.find().sort( { ts : -1 } )
也可以多个字段排序
db.myCollection.find().sort( { ts : -1 ,ds : 1 } )
这里的1代表升序,-1代表降序。
经过ME的实验,小于0的数字就是降序,0以上(包括0)就是升序。
limit() skip()
这两个ME想连起来讲,它们就是你实现数据库分页的好帮手。
limit()控制返回结果数量,如果参数是0,则当作没有约束,limit()将不起作用。
skip()控制返回结果跳过多少数量,如果参数是0,则当作没有约束,skip()将不起作用,或者说跳过了0条。
例如:
db.test.find().skip(5).limit(5)
结果就是取第6条到第10条数据。
snapshot() (没有尝试)
count() 条数
返回结果集的条数。
db.test.count()
在加入skip()和limit()这两个操作时,要获得实际返回的结果数,需要一个参数true,否则返回的是符合查询条件的结果总数。
例子如下:
> db.test.find().skip(5).limit(5).count()
9
> db.test.find().skip(5).limit(5).count(true)
4
八、用户操作
//添加一个用户
db.addUser("hw")
db.addUser("hw", "123321", true) #添加用户、设置密码、是否只读
//数据库认证、安全模式
db.auth("hw", "123123")
//显示当前所有用户
show users
//删除用户
db.removeUser("hw")九、其它命令
//查询指定数据库的集合的可用的存储空间
db.hw.storageSize()
//查询集合已分配的存储空间
db.hw.totalSize()
//查看数据库服务器的状态
db.serverStatus()
//查询指定数据库的统计信息
db.stats()
//当前db版本
db.version()
//查看当前db的链接机器地址
db.getMongo()十、可视化工具提高交互
为了让我们的操作更加人性化,更加直观的显示操作数据,我们可以使用一款可视化工具,今天我给大家带来的就是Navicat-mongo 这款工具,它是Navicat家族中一款只针对mongo数据库进行操作的数据库可视化工具。下载地址:
https://590m.com/file/7715018-442253555软件理由破解程序,只需进行简单操作即可进行破解。
下载好后按照提示进行安装即可,
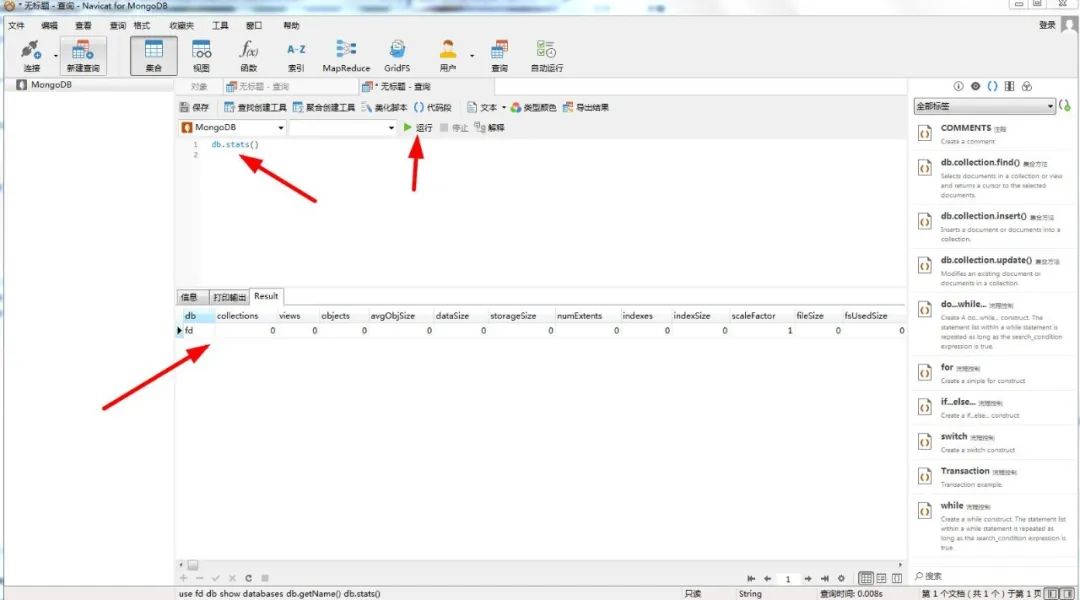
这样基本就能完成数据库的操作了,接下来就是大家伙照着命令去敲了。
总结
本文从Mongodb的安装、配置、数据增删改查、索引操作、数据聚合、数据备份与恢复、监控、高级查询、用户操作等十个方面进行介绍Mongodb,一篇文章带你搞懂Mongodb数据库。
想要学习更多网络爬虫知识,请点击阅读原文前往爬虫网站。
**-----**------**-----**---**** End **-----**--------**-----**-****

往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/0H5HgwJRyW9jtEHQ2W336Q,如有侵权,请联系删除。