
互联网应用随着业务的发展,部分单表数据体量越来越大,应对服务性能与稳定的考虑,有做分库分表、数据迁移的需要,本文介绍了vivo帐号应对以上需求的实践。
一、前言
Canal 是阿里巴巴开源项目,关于什么是 Canal?又能做什么?我会在后文为大家一一介绍。
在本文您将可以了解到vivo帐号使用 Canal 解决了什么样的业务痛点,基于此希望对您所在业务能有一些启示。
二、Canal介绍
1. 简介
Canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
2. 工作原理
2.1 MySQL 主备复制原理
Canal最核心的运行机制就是依赖于MySQL的主备复制,我们优先简要说明下MySQL主备复制原理。
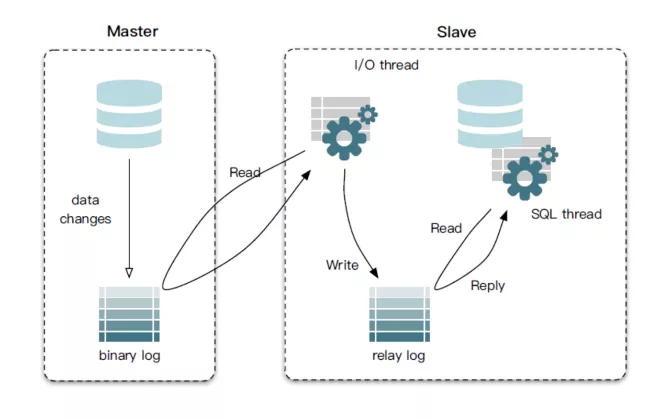
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)。
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)。
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据。
2.2 MySQL Binary Log介绍
MySQL-Binlog是 MySQL 数据库的二进制日志,用于记录用户对数据库操作的SQL语句(除了数据查询语句)信息。
如果后续我们需要配置主从数据库,如果我们需要从数据库同步主数据库的内容,我们就可以通过 Binlog来进行同步。
2.3 Canal 工作原理
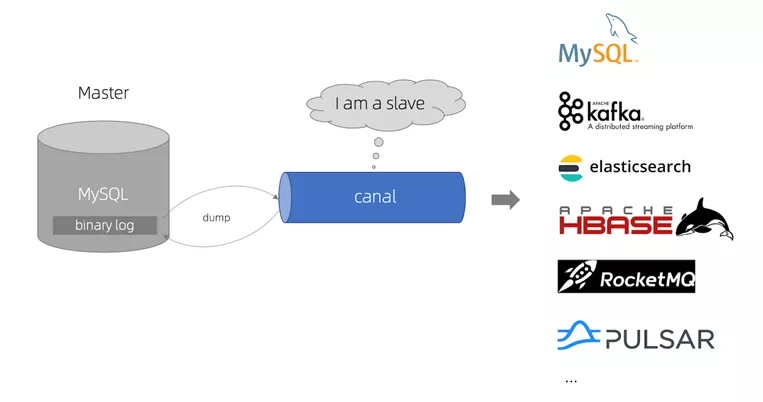
Canal 模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议。
MySQL master收到dump请求,开始推送binary log给slave(也就是Canal)。
Canal 解析 binary log 对象(原始为byte流)。
Canal 把解析后的 binary log 以特定格式的进行推送,供下游消费。
2.4 Canal 整体架构
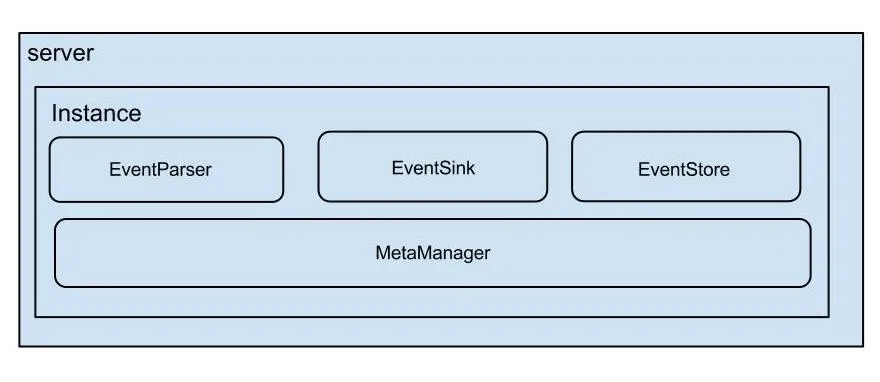
说明:
server 代表一个canal运行实例,对应于一个jvm
instance 对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
EventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
与数据库交互模拟从库,发送dump binlog请求,接收binlog进行协议解析并做数据封装,并将数据传递至下层EventSink进行存储,记录binlog同步位置。EventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
数据过滤、数据归并、数据加工、数据路由存储。EventStore (数据存储)
管理数据对象存储,包括新binlog对象的写入管理、对象订阅的位置管理、对象消费成功的回执位置管理。MetaManager (增量订阅&消费信息管理器)
负责binlog对象整体的发布订阅管理器,类似于MQ。
2.5 Canal 数据格式
下面我们来一起看下Canal内部封装的 Binlog对象格式,更好的理解 Canal。
Canal能够同步 DCL、 DML、 DDL。
业务通常关心 INSERT、 UPDATE、 DELETE引起的数据变更。

EntryProtocol.proto
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳]
schemaName [数据库实例]
tableName [表名]
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组]
afterColumns [Column类型的数组]
Column
index [column序号]
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为文本]
2.6 Canal 示例 demo
下面我们通过实际代码逻辑的判断,查看 Binlog解析成Canal 对象的数据模型,加深理解
- insert 语句


- delete语句


- update语句

2.7 Canal HA 机制
线上服务的稳定性极为重要,Canal是支持HA的,其实现机制也是依赖Zookeeper来实现的,与HDFS的HA类似。
Canal的HA分为两部分,Canal server和Canal client分别有对应的HA实现。
Canal Server:为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态。
Canal Client:为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
依赖Zookeeper的特性(本文不着重讲解zookeeper特性,请在网络上查找对应资料):
Watcher机制
EPHEMERAL节点(和session生命周期绑定)
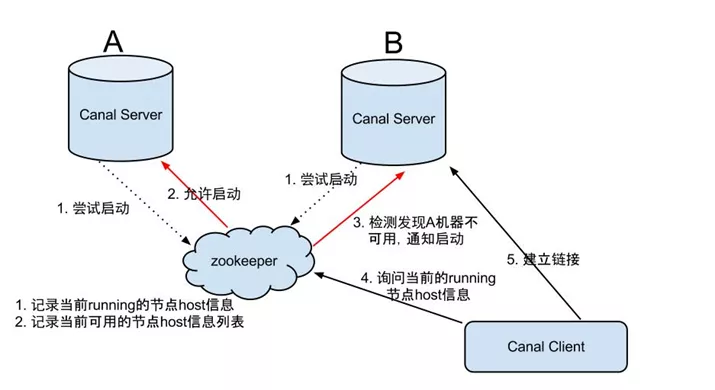
大致步骤:
Canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)。
创建 ZooKeeper节点成功后,对应的Canal server就启动对应的Canal instance,没有创建成功的Canal instance就会处于standby状态。
一旦ZooKeeper发现Canal server A创建的节点消失后,立即通知其他的Canal server再次进行步骤1的操作,重新选出一个Canal server启动instance。
Canal client每次进行connect时,会首先向ZooKeeper询问当前是谁启动了Canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect。
2.8 Canal 使用场景
上面介绍了Canal 的原理与运行机制,下面我们从实际场景来看,Canal 能够为我们业务场景解决什么样的问题。
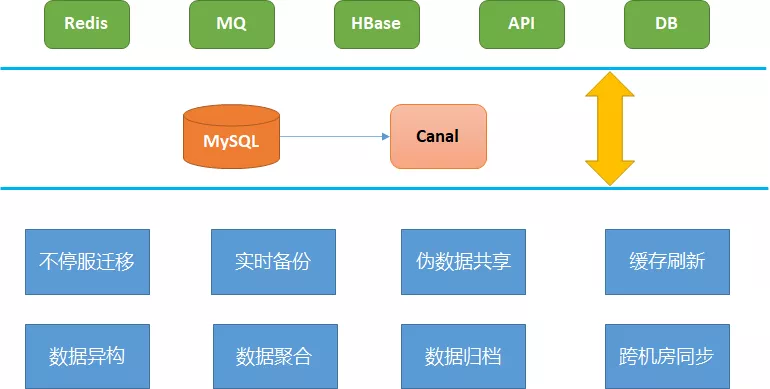
2.8.1 不停服迁移
业务在发展初期,为了快速支撑业务发展,很多数据存储设计较为粗放,比如用户表、订单表可能都会设计为单表,此时常规手段会采用分库分表来解决容量和性能问题。
但数据迁移会面临最大的问题:线上业务需要正常运行,如果数据在迁移过程中有变更,如何保证数据一致性是最大的挑战。
基于Canal,通过订阅数据库的 Binlog,可以很好地解决这一问题。
可详见下方vivo帐号的不停机迁移实践。
2.8.2 缓存刷新
互联网业务数据源不仅仅为数据库,比如 Redis 在互联网业务较为常用,在数据变更时需要刷新缓存,常规手段是在业务逻辑代码中手动刷新。
基于Canal,通过订阅指定表数据的Binlog,可以异步解耦刷新缓存。
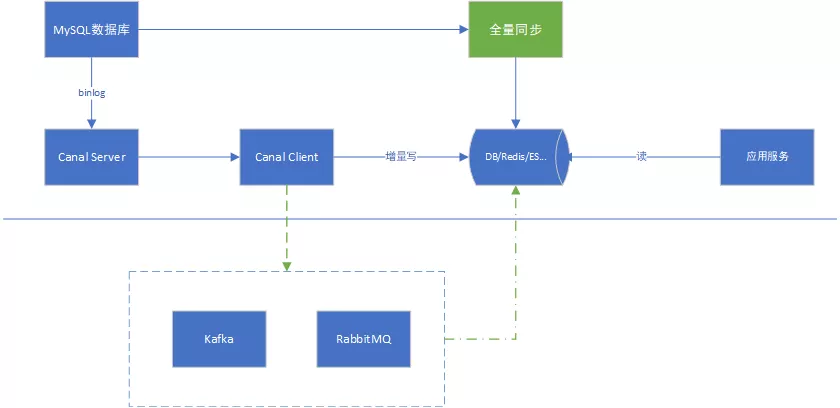
2.8.3 任务下发
另一种常见应用场景是“下发任务”,当数据变更时需要通知其他依赖系统。
其原理是任务系统监听数据库变更,然后将变更的数据写入MQ/Kafka进行任务下发。
比如帐号注销时下游业务方需要订单此通知,为用户删除业务数据,或者做数据归档等。
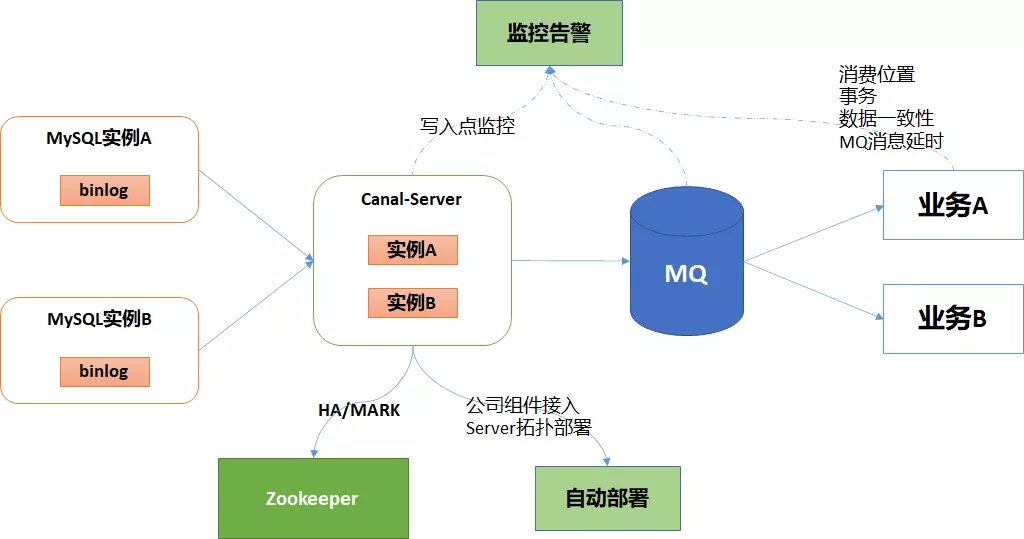
基于Canal可以保证数据下发的精确性,同时业务系统中不会散落着各种下发MQ的代码,从而实现了下发归集,如下图所示:
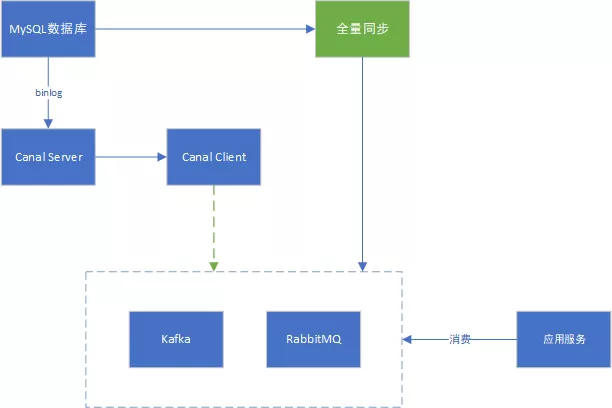
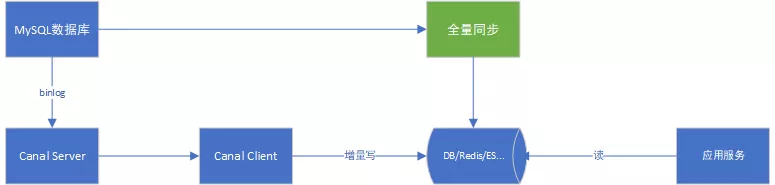
2.8.4 数据异构
在大型网站架构中,数据库都会采用分库分表来解决容量和性能问题,但分库分表之后带来的新问题。
比如不同维度的查询或者聚合查询,此时就会非常棘手。一般我们会通过数据异构机制来解决此问题。
所谓的数据异构,那就是将需要join查询的多表按照某一个维度又聚合在一个DB中。
基于Canal可以实现数据异构,如下图示意:

3、Canal 的安装及使用
Canal的详细安装、配置与使用,请查阅官方文档 >> 链接
三、帐号实践
1、实践一:分库分表
1.1 需求
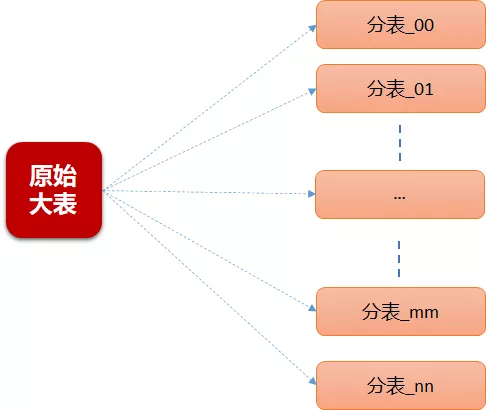
- 难点:
表数据量大,单表3亿多。
常规定时任务迁移全量数据,时间长且对业务有损。
- 核心诉求:
不停机迁移,最大化保证业务不受影响
“给在公路上跑着的车换轮胎”
1.2 迁移方案
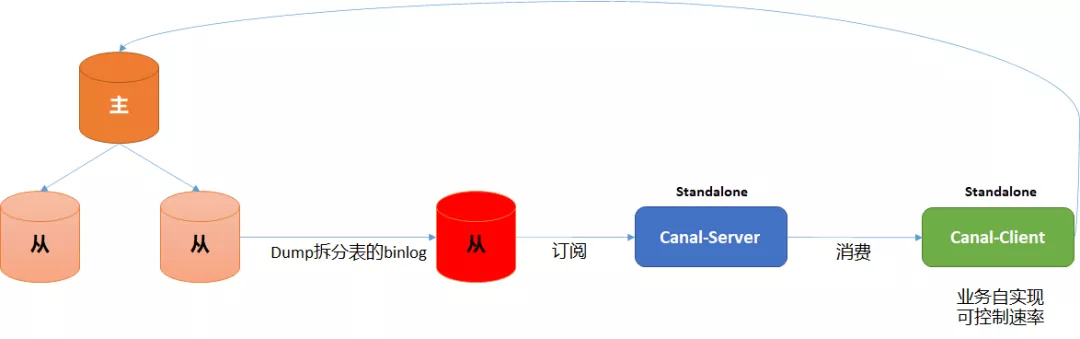
1.3 迁移过程

整体过程大致如下:
- 分析帐号现有痛点
单表数据量过大:帐号单表3亿+
用户唯一标识过多
业务划分不合理
确定分库分表方案
存量数据迁移方案
使用传统的定时任务迁移,时长过长,且迁移过程中为了保证数据一致性,需要停机维护,对用户影响较大。
确定使用canal进行迁移,对canal做充分调研与评估,与中间件及DBA共同确定,可支持全量、以及增量同步。
迁移过程通过开关进行控制,单表模式 → 双写模式 → 分表模式。
数据迁移周期长,迁移过程中遇到部分未能预估到的问题,进行了多次迁移。
迁移完成后,正式切换至双写模式,即单表及分表同样写入数据,此时数据读取仍然在单表模式下读取数据,Canal仍然订阅原有单表,进行数据变更。
运行两周后线上未产生新问题,正式切至分表模式,此时原有单表不再写入数据,即单表不会再有新的Binlog产生,切换后线上出现了部分问题,即时跟进处理,“有惊无险”。
2、实践二:跨国数据迁移
2.1 需求
在vivo海外业务开展初期,海外部分国家的数据存储在中立国新加坡机房,但随着海外国家法律合规要求越来越严格,特别是欧盟地区的GDPR合规要求,vivo帐号应对合规要求,做了比较多的合规改造工作。
部分非欧盟地区的国家合规要求随之变化,举例澳洲当地要求满足GDPR合规要求,原有存储在新加坡机房的澳洲用户数据需要迁移至欧盟机房,整体迁移复杂度增加,其中涉及到的难点有:
不停机迁移,已出货的手机用户需要能正常访问帐号服务。
数据一致性,用户变更数据一致性需要保证。
业务方影响,不能影响现网业务方正常使用帐号服务。
2.2 迁移方案
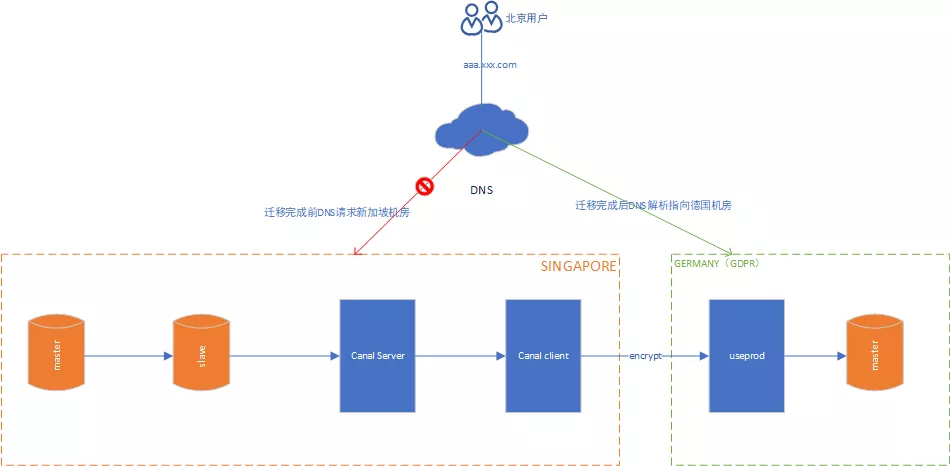
2.3 迁移过程
在新加坡机房搭建备库,主从同步 Binlog。
搭建 Canal 的server及client端,同步订阅消费Binlog。
client端基于订阅的Binlog进行解析,将数据加密传输至欧盟GDPR机房。
欧盟应用数据解析传输的数据,落地存储。
数据同步完成后运维同事协助将上层域名的DNS解析转发至欧盟机房,完成数据切换。
观察新加坡机房Canal服务运行情况,没有异常后停止Canal服务。
通过业务方,帐号侧完成切换。
待业务方同步切换完成后,将新加坡机房的数据清除。
3、经验总结
3.1 数据序列化
Canal底层使用protobuf作为数据数据列化的方式,Canal-client在订阅到变更数据时,为null的数据会自动转换为空字符串,在ORM侧数据更新时,因判断逻辑不一致,导致最终表中数据更新为空字符串。
3.2 数据一致性
帐号本次线上Canal-client只有单节点,但在数据迁移过程中,因业务特性,导致数据出现了不一致的现象,示例大致如下:
用户换绑手机号A。
Canal此时在还未订阅到此 Binlog position。
用户又换绑手机号B。
在对应时刻,Canal消费到更新手机号A的Binlog,导致用户新换绑的手机号做了覆盖。
3.3 数据库主从延时
出于数据一致性地考虑(结合帐号业务数据未达到需要分库的必要性),帐号分表在同一数据库进行,即迁移过程中分表数据不断地进行写入,加大数据库负载的同时造成了从库读取延时。
解决方案:增加速率控制,基于业务的实际情况,配置不同的策略,例如白天业务量大,可以适当降低写入速度,夜间业务量小,可以适当提升写入速度。
3.4 监控告警
在整体数据迁移过程中,vivo帐号在client端增加了实时同步数据的简易监控手段,即基于业务表基于内存做计数。
整体监控粒度较粗,包括以上数据不一致性,在数据同步完成后,未能发现异常,导致切换至分表模式下出现了业务问题,好在逻辑数据可以通过补偿等其他手段弥补,且对线上数据影响较小。
四、拓展思考
1、现有问题分析
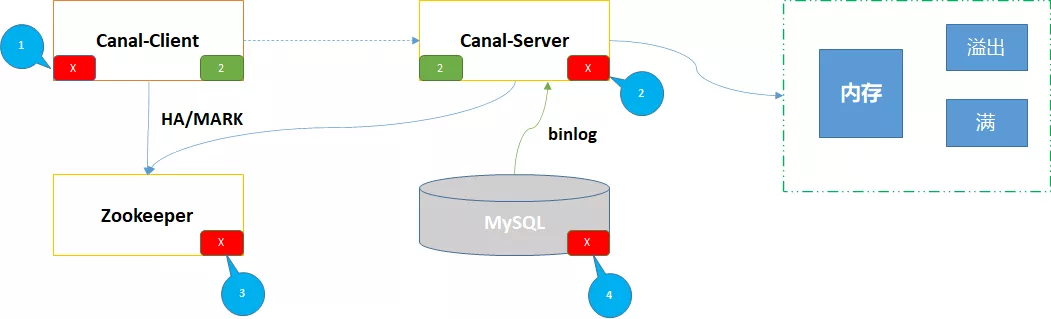
以上是基于 Canal现有架构画出的简易图,虽然基于HA整体高可用,但细究后还是会发现一些隐患,其中标记红色X的节点,可以视为可能出现的故障点。

2、通用组件复用
基于以上可能出现的问题点,我们可以尝试做上图中的优化。

3、延展应用-多数据中心同步
在互联网行业,大家对“异地多活”已经耳熟能详,而数据同步是异地多活的基础,所有具备数据存储能力的组件如:数据库、缓存、MQ等,数据都可以进行同步,形成一个庞大而复杂的数据同步拓扑,相互备份对方的数据,才能做到真正意义上"异地多活”。
本逻辑不在本次讨论范围内,大家可以参阅以下文章内容,笔者个人认为讲解较为详细:http://www.tianshouzhi.com/api/tutorials/canal/404
五、参考资料
作者:vivo 产品平台开发团队














