
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接: https://blog.csdn.net/vbirdbest/article/details/81051579
一:数据库的设计
数据库命名:数据库名的命名一般和项目的名称保持一致,不要随意的起名字。
数据库编码: 采用utf8mb4而不使用utf8
MySQL 的“utf8”实际上不是真正的UTF-8,真正的UTF-8是每个字符最多四个字节,而MySQL的“utf8”只支持每个字符最多三个字节。MySQL一直没有修复这个 bug,他们在 2010 年发布了一个叫作“utf8mb4”的字符集,绕过了这个问题。MySQL的“utf8mb4”才是真正的“UTF-8”。所有在使用“utf8”的 MySQL和MariaDB用户都应该改用“utf8mb4”,永远都不要再使用“utf8”。第三方像微信和QQ的昵称一般包含一些表情符号等,这些符号是属于UTF-8的,但是如果数据库中使用utf-8将不能保存,只能将数据库编码改为utf8mb4才能保存第三方的昵称这种数据
二:表的设计
数据库表的好坏是数据库设计的基础,而且一旦数据库表设计完毕并投入使用,将来再进行修改就比较麻烦,因此在进行数据库设计的时候一定要尽可能的考虑周到。
1. 表名
表的命名一般遵守 “业务名称 _ 表名“或者是“项目名_ 表名“的格式,对于业务名称一般都是简写,不全拼,全拼表名会太长,如sys_user(系统模块对应的用户表),对于一些公用的可以使用tbl(table)作为模块名,如字典表 tbl_dictionary
表名不使用复数形式,表名应该仅仅表示表里面的实体内容,不应该表示实体数量
为什么要使用前缀?
如果多个项目都使用同一个数据库的话,可以防止命名冲突,例如用户表,如果没有前缀,只能有一个叫user的,其它项目也想使用这个名字就没法用了,为了解决这种问题,可以在表名上增加一个前缀,前缀为项目名称,如xxx_user, yyy_user; 在公司中可以经常看到有时候数据库中的所有表都用项目的简称做前缀,很可能所有表只有这一种前缀,也没有分多个前缀。 不同项目一般都会创建自己的数据库,但是不能保证万一会使用同一个数据库的情况,如两个项目关联很大可能会使用同一个数据库,这样使用前缀就能解决命名冲突的问题。
在比较复杂的系统中,通过表名前缀可以大概了解到表所在的模块和分类,这样做日常开发和运维的时候看起来比较方便,新人了解系统数据结构的时候也有章可循,这种方式就是使用多种前缀的方式
2. 字段名
- MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、 表名、字段名,都不允许出现任何大写字母,避免节外生枝。
- 一般所有表都要有id, id必为主键,类型为bigint unsigned,单表时自增、步长为1; 有些特殊场景下(如在高并发的情况下该字段的自增可能对效率有比价大的影响)id是通过程序计算出来的一个唯一值而不是通过数据库自增长来实现的。
- 一般情况下主键id和业务没关系的,例如订单号不是主键id,一般是订单表中的其他字段,一般订单号order_code为字符类型
- 一般情况下每张表都有着四个字段create_id,create_time,update_id,update_time, 其中create_id表示创建者id,create_time表示创建时间,update_id表示更新者id,update_time表示更是时间,这四个字段的作用是为了能够追踪数据的来源和修改
- 最好不要使用备用字段(个人观点), 禁用保留字,如 desc、range、match、delayed 等
- 表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint (1 表示是,0 表示否), 任何字段如果为非负数,必须是unsigned。表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除
- 如果某个值能通过其他字段能计算出来就不需要用个字段来存储,减少存储的数据
- 为了提高查询效率,可以适当的数据冗余,注意是适当
- 强烈建议不使用外键, 数据的完整性靠程序来保证
- 单条记录大小禁止超过8k, 一方面字段不要太多,有的都能上百,甚至几百个,另一方面字段的内容不易过大像文章内容等这种超长内容的需要单独存到另一张表
3. 字段的数据类型
不同的数据类型搜索的方式不同,所以说要选择合适的数据类型。
用尽量少的存储空间来存数一个字段的数据, 缩小存储空间换取查询时间,能用int的就不用char或者varchar,能用tinyint的就不用int,使用UNSIGNED存储非负数值,其中无符号值可以避免误存负数,且扩大了表示范围。合适的字符存储长度,不但节约数据库表的存储空间、节约索引存储,更重要的是提升检索速度。
尽量使用数字型字段,提高数据比对效率。
①:字符类型
- char是固定长度的字符类型,它的处理速度比varchar快,缺点是浪费存储空间,当实际存储的值小于指定的长度时会以空格来填充,对于长度变化不大并且对查询速度有较高的要求可以选择char。适合存储用户密码的MD5哈希值,手机号,性别,因为它的长度总是一样的。对于经常改变的值,char也好于varchar,因为固定长度的行不容易产生碎片,对于很短的列,char的效率也高于varchar。char(1)字符串对于单字节字符集只会占用一个字节,但是varchar(1)则会占用2个字节,因为1个字节用来存储长度信息 。如果存储的字符串长度几乎相等,使用char定长字符串类型。
- varchar是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。varchar的长度是字符长度,而不是字节长度。varchar还会使用额外的存储空间来记录可变字符串的长度
- 列的最大长度小于255则只需要额外占用一个字节来记录字符串的长度
- 列的最大长度大于255则需要额外占用两个字节来记录字符串的长度
- 不同存储引擎对char和varchar的使用原则不同,myisam:建议使用国定长度的数据列代替可变长度。innodb:建议使用varchar,大部分表都是使用innodb,所以varchar的使用频率更高
②:数值类型
选用合适的长度非常重要,能用tinyint就不用integer
- 金额类型的字段尽量使用long用分表示,尽量不要使用bigdecimal,严谨使用float和double因为计算时会丢失经度
- 如果需要使用小数严谨使用float,double,使用定点数decimal,decimal实际上是以字符串的形式存储的,所以更加精确,java中与之对应的数据类型为BigDecimal
- 如果值为非负数,一定要使用unsigned,无符号不仅能防止负数非法数据的保存,而且还能增大存储的范围
- 不建议使用ENUM、SET类型,使用TINYINT来代替
decimal不会经度丢失,但是会占用更多的存储空间,占用空间越大就需要越多的磁盘IO,磁盘IO是影响MySQL性能的一个最重要的因素,所以还需慎用,对于金额直接使用bigint存储分
误区:
创建表时我们经常看到长度这一列,例如 tinyint(2),对于整型来说小括号中的2不是指的存储长度,而是指的零填充,对于字符串指的是长度,zerofill零填充,当数据的长度小于指定的长度时,会使用0来填充缺失的长度。零填充在mysql客户度中看不出来,使用命令行可以看出来。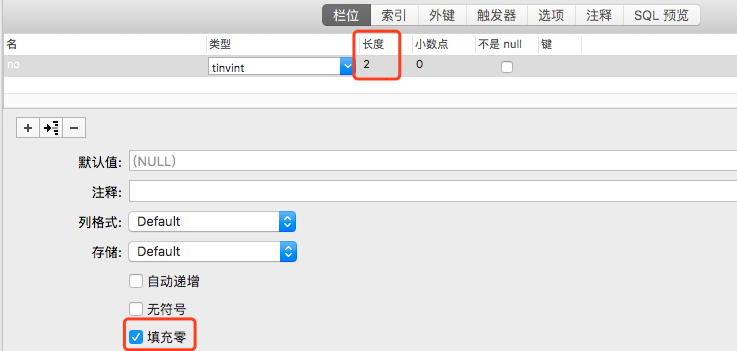
如果tinyint(2)中的2代表长度,那么102就插入不成功,事实上是插入成功的。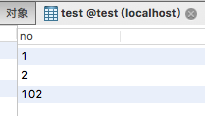
使用命令行可以看到1和2因不到两位长度,差一位,需要用0来填充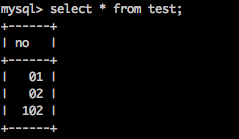
③:日期类型
根据实际需要选择能够满足应用的最小存储日期类型。
- 如果应用只需要记录年份,那么仅用一个字节的year类型。
- 如果记录年月日用date类型, date占用4个字节,存储范围10000-01-01到9999-12-31
- 如果记录时间时分秒使用它time类型
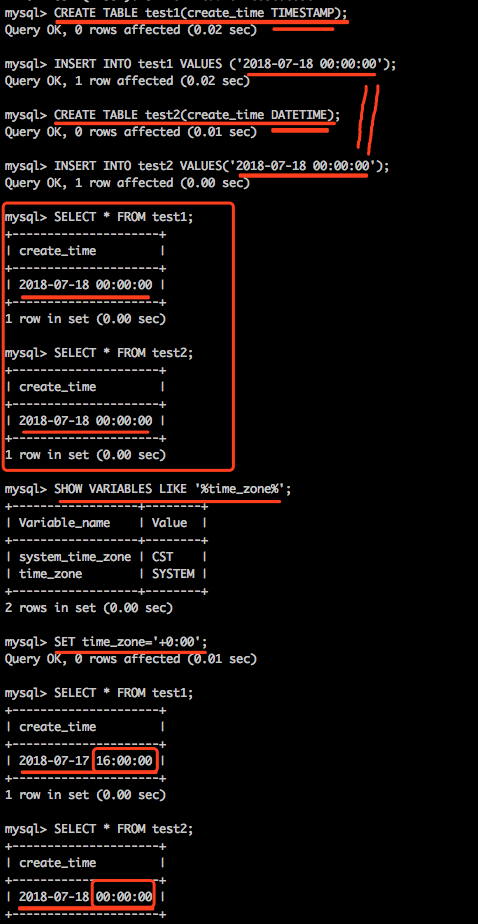
- 如果记录年月日并且记录的年份比较久远选择datetime,而不要使用timestamp,因为timestamp表示的日期范围要比datetime短很多
- 如果记录的日期需要让不同时区的用户使用,那么最好使用timestamp, 因为日期类型值只有它能够和实际时区相对应
- datetime默认存储年月日时分秒不存储毫秒fraction,如果需要存储毫秒需要定义它的宽度datetime(6)
timestamp与datetime
两者都可用来表示YYYY-MM-DD HH:MM:SS[.fraction]类型的日期。
都可以使用自动更新CURRENT_TIMESTAMP
对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,将其又转化为客户端当前时区进行返回。而对于DATETIME,不做任何改变,基本上是原样输入和输出。
timestamp占用4个字节:timestamp所能存储的时间范围为:’1970-01-01 00:00:01.000000’ 到 ‘2038-01-19 03:14:07.999999’
datetime占用8个字节 :datetime所能存储的时间范围为:’1000-01-01 00:00:00.000000’ 到 ‘9999-12-31 23:59:59.999999’
总结:TIMESTAMP和DATETIME除了存储范围和存储方式不一样,没有太大区别。如果需要使用到时区就必须使用timestamp,如果不使用时区就使用datetime因为datetime存储的时间范围更大
注意:
- 禁止使用字符串存储日期,一般来说日期类型比字符串类型占用的空间小,日期时间类型在进行查找过滤是可以利用日期进行对比,这比字符串对比高效多了,日期时间类型有丰富的处理函数,可以方便的对日期类型进行日期的计算
- 也尽量不要使用int来存储时间戳
PROCEDURE analyse(): 用于分析表的数据类型
SELECT * FROM tbl_user PROCEDURE analyse();
3. 是否为null
MySQL字段属性应该尽量设置为NOT NULL,除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL 。
在MySql中NULL其实是占用空间的,“可空列需要更多的存储空间”:需要一个额外字节作为判断是否为NULL的标志位“需要mysql内部进行特殊处理”, 而空值”“是不占用空间的。
含有空值的列很难进行查询优化,而且对表索引时不会存储NULL值的,所以如果索引的字段可以为NULL,索引的效率会下降很多。因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替null。
联表查询的时候,例如SELECT user.username, info.introduction FROM tbl_user user LEFT JOIN tbl_userinfo info ON user.id = info.user_id; 如果tbl_userinfo.introduction设置的可以为null, 假如这条sql查询出了对应的记录,但是username有值,introduction没有值,那么就不是很清楚这个introduction是没有关联到对应的记录,还是关联上了而这个值为null,null意思表示不明确,有歧义
注意:NULL在数据库里是非常特殊的,任何数跟NULL进行运算都是NULL, 判断值是否等于NULL,不能简单用=,而要用IS NULL关键字。使用 ISNULL()来判断是否为 NULL 值,NULL 与任何值的直接比较都为 NULL。
- NULL<>NULL的返回结果是NULL,而不是false。
- NULL=NULL的返回结果是NULL,而不是true。
- NULL<>1的返回结果是NULL,而不是true。
4. 存储引擎
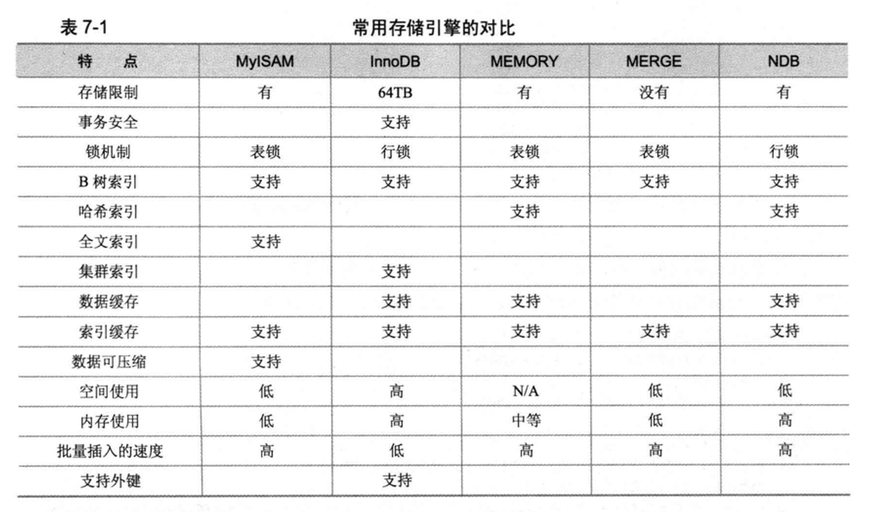
常用的存储引擎的选择有MYISAM、InnoDB、MEMORY,不同的存储引擎支持的功能不一样,MySQL5.5之后默认的是InnoDB。绝大部分场景都是使用InnoDB引擎。
- MYISAM 不支持事务, 不支持外键,其优势是访问速度快,对事务完整性没有要求或者以select、insert为主的应用程序可以选择这个引擎,支持全文索引,表锁,注意:MYISAM 在删除数据时好像类似于逻辑删除,需要定时物理删除,清理碎片:optimize table 名称;
- InnoDB 支持事务,不支持全文索引,标锁,支持外键
- MEMORY:查询速度极快,数据在内存中不持久化,数据库重启数据就消失,类似于缓存的作用memcache
表引擎取决于实际应用场景;日志及报表类表建议用myisam,只读的表;与交易,审核,金额相关的表建议用innodb引擎。
建议:不要混合使用存储引擎,实际场景中会有MyISAM和InnoDB混合使用的情况,但是这样有问题,比如一个事务同时操作了myisam引擎的表和innodb引擎的表,而myisam是不支持事务的,就会造成myisam表没有回滚。现在开发中绝大部分都是使用InnoDB,也不经常见到myisam,至少我工作中没见到过。

mysql5.0之后默认为InnoDB创建表的时候可以指定engine,也可以通过alter table语句来修改存储引擎。
create table tbl_user (
)engine=InnoDB default charset=utf-8;
alter table tbl_user engine = innodb;













