
一、 背景
在早期从MySQL到TiDB实施同步操作过程中,我们大多数用的是mydumper+loader进行整体全量备份的导出,之后拿到meta信息后,通过syncer实现增量同步,整体操作起来比较麻烦,涉及的配置文件较多,其基本原理就是Syncer 通过把自己注册为一个 MySQL Slave 的方式,和 MySQL Master 进行通信,然后不断读取 MySQL Binlog,进行 Binlog Event 解析,规则过滤和数据同步。其架构如下: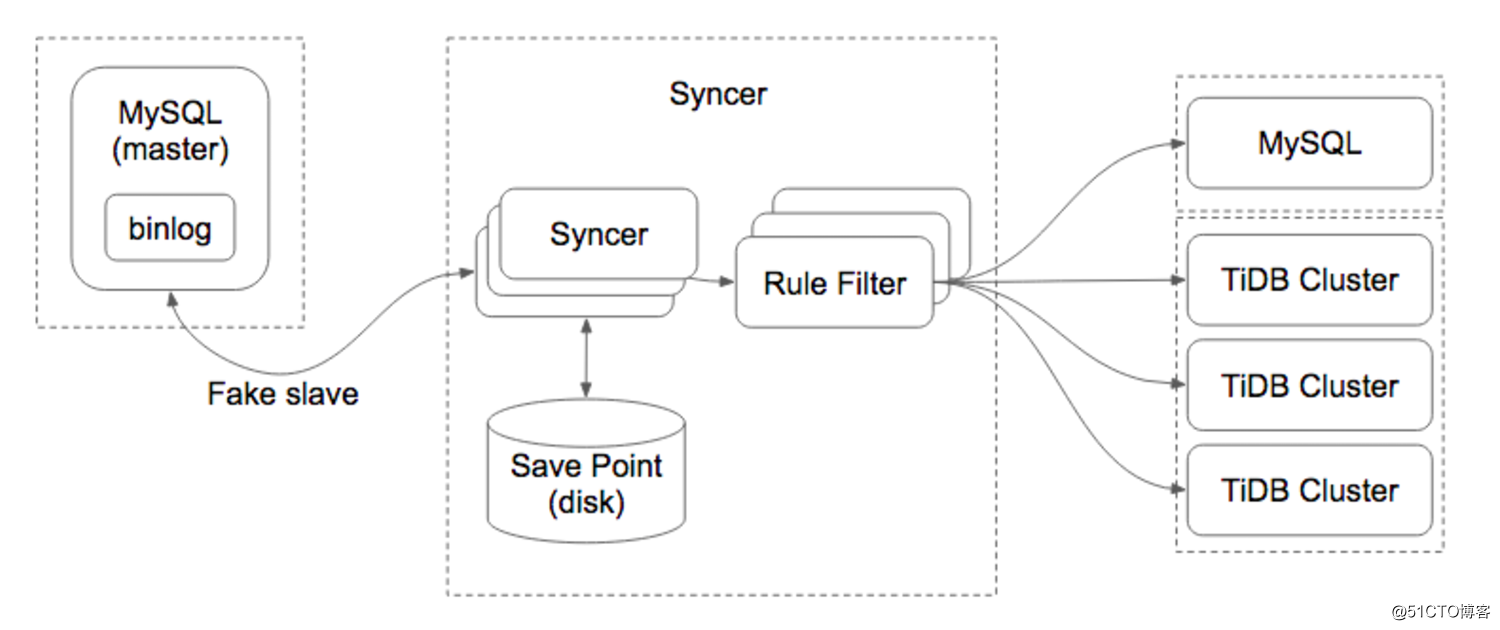
而后pingcap官方推出了TiDB Data Migration (DM)套件,这一套件极大地降低了同步工具使用的门槛。
DM是一体化的数据迁移任务管理平台,支持从 MySQL 或 MariaDB 到 TiDB 的全量数据迁移和增量数据复制。使用 DM 工具有利于简化错误处理流程,降低运维成本。后续更是有dm-portal工具方便dba通过图形化界面的方式进行选择性导出和自动生成配置文件,虽然有一些小bug和不够人性化的方面,但无伤大雅,可惜的是这个项目最后咨询官方得知被砍掉了,不再进行维护。
二、 原因
我有幸从DM内测版本开始就接触和使用这一工具,直至其最新版1.0.6,见证了DM功能不断的完善,真切体会到了这一工具给我们带来的帮助,我认为这是每一个DBA和TiDB使用者都应该了解甚至熟练掌握的工具,因为大多数场景下,我们使用TiDB并不是全新的系统上去直接建库建表,而是从MySQL迁移过来,先进行性能对比和测试,而后进行数据迁移的,因此熟练掌握DM工具可以让你的工作事半功倍。
三、架构
集群配置
集群版本:v3.0.5
集群配置:普通SSD磁盘,128G内存,40 核cpu
tidb21 TiDB/PD/pump/prometheus/grafana/CCS
tidb22 TiDB/PD/pump
tidb23 TiDB/PD/pump
tidb01 TiKV
tidb02 TiKV
tidb03 TiKV
tidb04 TiKV
tidb05 TiKV
tidb06 TiKV
tidb07 TiKV
tidb08 TiKV
tidb09 TiKV
tidb10 TiKV
tidb11 TiKV
tidb12 TiKV
tidb13 TiKV
tidb14 TiKV/DM-prometheus/DM-grafana/DMM
tidb15 TiKV/DMW1
tidb16 TiKV/DMW1
正常来说,官方建议抽出单独的机器来部署DM,且推荐每个节点上部署单个 DM-Worker 实例。除非机器拥有性能远超 TiDB 软件和硬件环境要求中推荐配置的 CPU 和内存,并且每个节点配置 2 块以上的硬盘或大于 2T 的 SSD,才推荐单个节点上部署不超过 2 个 DM-Worker 实例。而我们的线上环境机器比较吃紧,所以一直以来都是和TiKV进行混部的,例如上述架构中,选取了tidb14,tidb15,tidb16进行dm相关的软件部署。所幸运行起来效果还可以,但有条件的建议大家还是老老实实按照官方文档,单独部署。
DM架构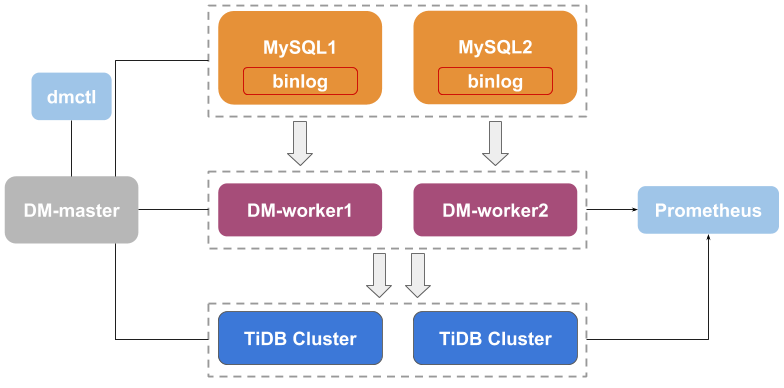
DM架构如上图所示,主要包括三个组件:DM-master,DM-worker 和 dmctl。
DM-master 负责管理和调度数据迁移任务的各项操作
DM-worker 负责执行具体的数据迁移任务
dmctl 是用来控制 DM 集群的命令行工具
具体的功能本文不再赘述,可参考官方文档了解每一个模块的详细功能
DM特性
Table routing 合并迁移
Block & allow table lists 白名单
Binlog event filter binlog级别过滤
Shard support 合库合表
四、新特性
dm从内测版本开始,每一个版本的迭代都修复和新加入了不少功能,这里我单独拎出来1.0.5这个版本,因为从这个版本开始,它支持了以前从来没有但又让人早就期盼已久的功能:online ddl的支持。
众所周知,MySQL在数据量大了后,没有人会直接去对原表进行alter,大多数人都通过第三方工具pt-online-schema-change或者gh-ost来进行改表,以此削减改表期间对线上业务的影响。而早期的dm不支持该功能时,每次上游改完表后,由于临时表(_xxxx_new,_xxx_gho等)不在白名单里,会直接导致下游tidb丢失该DDL,引发同步异常报警。当然,如果你是全库同步,那自然不会有这个问题,但绝大多数场景下都是部分表导入到TiDB,用到了白名单功能的情况下就会导致该问题出现。而1.0.5版本后,这便不再是问题,虽然目前仅仅只能同时支持一种改表工具,但对比之前来说,无疑是我认为最好的改进,还没用的朋友们不妨试一试。
例如:
上游通过pt-online-schema-change工具为表helei5新增一列
--alter="ADD column hl2 varchar(10) not null default '';" D=h_2,t=helei5
先看下没有配置跳过的情况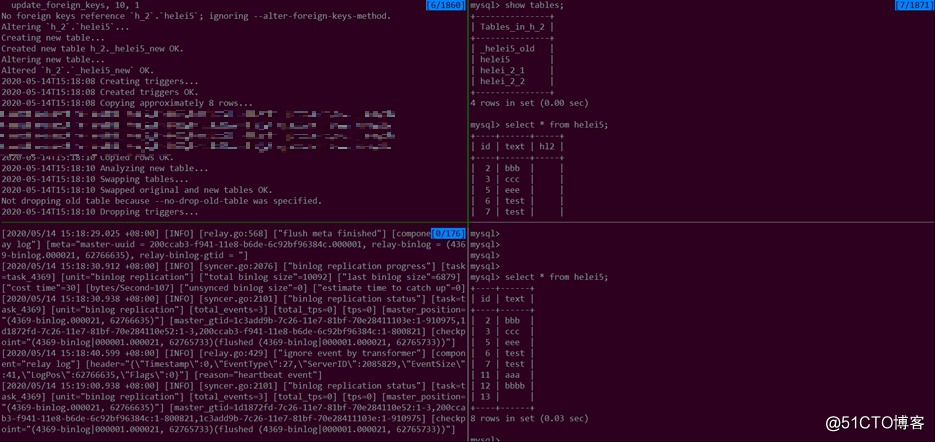
几个关键的词:
skip event 因为不在白名单中被跳过
skip event, need handled ddls is empty ,中间表因为被过滤掉在下游不存在,
所以提示is empty,也被跳过RENAME TABLE `h_2`.`helei5` TO `h_2`.`_helei5_old`",
"RENAME TABLE `h_2`.`_helei5_new` TO `h_2`.`helei5`
rename操作在上游为了保证原子性是一条SQL实现表名互换的,
我们可以看到,好在拆分后也依旧是被跳过的,这是因为中间表不存在
rename的ddl里部分表例如_helei5_new是空的,所以整个SQL不会被执行
"RENAME TABLE `h_2`.`helei5` TO `h_2`.`_helei5_old`的话被执行了是我们不希望看到的
此时task状态依旧是running,但下游已经没有新增的列
{
"taskName": "task_4369",
"taskStatus": "Running",
"workers": [
“192.168.1.248:8262"
]
此时插入包含新列h2的数据
mysql> insert into helei5 values(14,'cccc','pt alter');
这个时候dm就会报错
{
"taskName": "task_4369",
"taskStatus": "Error - Some error occurred in subtask. Please run `query-status task_4369` to get more details.",
"workers": [
“192.168.1.248:8262"
]
报错信息是:
msg": "[code=36027:class=sync-unit:scope=internal:level=high] current pos (4369-binlog|000001.000021, 62771055): gen insert sqls failed, schema: h_2, table: helei5: Column count doesn't match value count: 2 (columns) vs 3 (values)
点位:
sync": {
"totalEvents": "3",
"totalTps": "0",
"recentTps": "0",
"masterBinlog": "(4369-binlog.000021, 62774081)",
"masterBinlogGtid": "1c3add9b-7c26-11e7-81bf-70e28411103e:1-910975,1d1872fd-7c26-11e7-81bf-70e284110e52:1-3,200ccab3-f941-11e8-b6de-6c92bf96384c:1-800846",
"syncerBinlog": "(4369-binlog|000001.000021, 62765733)",
因为少列,所以报错,我们在下游添加列,然后跳过
mysql> alter table helei5 add column h2 varchar(10) not null default '';
跳过语句是:
» sql-skip --worker=192.168.1.248:8262 --binlog-pos=4369-binlog|000001.000021:62765733 task_4369
{
"result": true,
"msg": "",
"workers": [
{
"result": true,
"worker": "",
"msg": ""
}
]
}
dm-worker的日志有如下内容:
[2020/05/14 15:48:05.883 +08:00] [INFO] [operator.go:136] ["set a new operator"] [task=task_4369] [unit="binlog replication"] ["new operator"="uuid: b52784e4-e804-46f5-974c-ca811a34dc30, pos: (4369-binlog|000001.000021, 62765733), op: SKIP, args: "]
执行恢复任务
» resume-task task_4369
{
"taskName": "task_4369",
"taskStatus": "Running",
"workers": [
“192.168.1.248:8262"
在添加online-ddl-scheme: "pt"参数后,下游成功读取到pt-online-schama-change加的新列: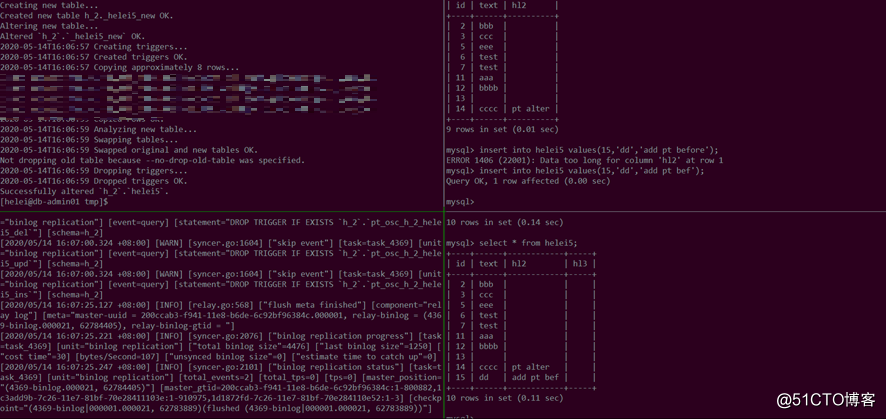
gh-ost工具同理:
几个关键词:
ghc表的创建DM是忽略的:
prepare to handle ddls
skip event, need handled ddls is empty
gho表的创建和新DDL也是忽略的,而是把该 DDL 记录到 dm_meta.{task_name}\_onlineddl 以及内存中:
prepare to handle ddls
skip event, need handled ddls is empty
del表的创建也是忽略的:
rename /* gh-ost */ table `h_2`.`helei5` to `h_2`.`_helei5_del`, `h_2`.`_helei5_gho` to `h_2`.`helei5`
不执行 rename to _helei5_del。当要执行 rename ghost_table to origin table 的时候,并不执行 rename 语句,而是把记录在内存中的 DDL 读取出来,然后把 ghost_table、ghost_schema 替换为 origin_table 以及对应的 schema,再执行替换后的 DDL。
操作完日志会有:
finish online ddl and clear online ddl metadata in normal mode
在添加online-ddl-scheme: "gh-ost"的参数后,下游也读取到了加的列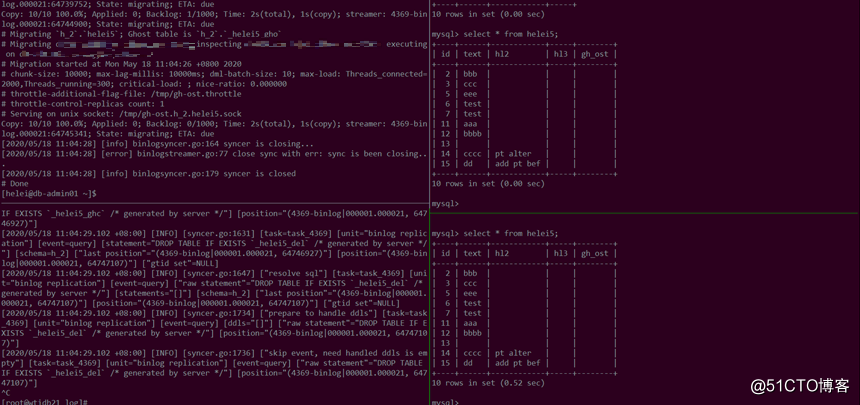
五、1062的踩坑
在早期,我们有一个业务通过DM同步到TiDB,但每过几个小时后,同步总是中断,而每次我们人工resume task又能恢复,咨询后得知resume操作后,dm内部前几分钟是debug模式,执行的replace。
当时的报错内容如下:
>> query-status task_3306
...
...
"msg": "[code=10006:class=database:scope=not-set:level=high] execute statement failed: commit: Error 1062: Duplicate entry '21277ed5f5e7c3b646a5229269d54d3a7fccc08bf34c8f2113fdd4df62f4a229' for key 'clientid'\ngithub.com/pingcap/dm/pkg/terror.(*Error).Delegate\n
>>query-error task_3306
"errorSQL": "[tp: insert, sql: INSERT INTO `360sudi`.`client` (`id`,`clientid`,`toid`,`updatetime`) VALUES (?,?,?,?);, args: [4102315138 62ba2a78af090ab1337c6b62f8dedfc8b6338007cdeb5a7ea4e7f4b4c23e3e0c 3250350869 2019-11-21 19:54:56], key: 4102312246, ddls: []
用自增id的主键查:
[helei@db01 ~]$ curl http://192.168.1.1:10080/mvcc/key/360/client/4102315138
{
"key": "7480000000000011945F7280000000F4845C82",
"region_id": 2278436,
"value": {
"info": {
"writes": [
{
"type": 3,
"start_ts": 412703076417274370,
"commit_ts": 412703076417274370
}
]
}
}
}
根据查询出来的 commit-ts 使用 pd-ctl tso 命令看下在下游已经存在的记录提交的时间
[root@tidb helei]# /data1/tidb-ansible-3.0.5/resources/bin/pd-ctl -i -u http://192.168.1.2:2379
» tso
Usage: tso <timestamp>
» tso 412703076417274327
system: 2019-11-21 19:54:57.124 +0800 CST
logic: 471
» tso 412702903507091560
system: 2019-11-21 19:43:57.524 +0800 CST
logic: 104
»
查找 dm-worker 日志中跟这个记录相关的内容
-binlog.000020, 185499141), relay-binlog-gtid = "]
[2019/11/21 19:54:47.710 +08:00] [INFO] [syncer.go:2004] ["binlog replication progress"] [task=task_3306] [unit="binlog replication"] ["total binlog size"=378940822] ["last binlog size"=378533105] ["cost time"=30] [bytes/Second=13590] ["unsynced binlog size"=0] ["estimate time to catch up"=0]
[2019/11/21 19:54:47.710 +08:00] [INFO] [syncer.go:2029] ["binlog replication status"] [task=task_3306] [unit="binlog replication"] [total_events=1528442] [total_tps=1455] [tps=40] [master_position="(3306-binlog.000020, 185616633)"] [master_gtid=] [checkpoint="(3306-binlog|000001.000020, 185616633)(flushed (3306-binlog|000001.000020, 185484711))"]
[2019/11/21 19:54:57.157 +08:00] [ERROR] [db.go:269] ["execute statements failed after retry"] [task=task_3306] [unit="binlog replication"] [queries="[INSERT INTO `360sudi`.`client` (`id`,`clientid`,`toid`,`updatetime`) VALUES (?,?,?,?);]"] [arguments="[[4102315138 62ba2a78af090ab1337c6b62f8dedfc8b6338007cdeb5a7ea4e7f4b4c23e3e0c 3250350869 2019-11-21 19:54:56]]"] [error="[code=10006:class=database:scope=not-set:level=high] execute statement failed: commit: Error 1062: Duplicate entry '62ba2a78af090ab1337c6b62f8dedfc8b6338007cdeb5a7ea4e7f4b4c23e3e0c' for key 'clientid'"]
比较下第二个步骤查询出来的时间和第三个步骤查询出来的时间
第二个步骤 2019-11-21 19:54:57.124 +0800 CST
第三个步骤 2019/11/21 19:54:57.157 +08:00
第二个步骤2019-11-21 19:43:57.524的时间,在第三个步的worker日志里未找到相关
我们尝试过:
1.将dm下游配置为单一tidb而非tidb的lvs,防止多个ip写入ntp引起毫秒级的误差(无果)
2.task文件针对syncer的worker进行限制,只让一个syncer进行同步(无果)
3.业务变更为replace into,开始测试
改syncer worker count的时候,光rolling_update是没用的,需要dm-ctl去stop/start task才可以生效
可以看到,15:25起,qps在syncer worker count配置为16后瞬间从256涨到4k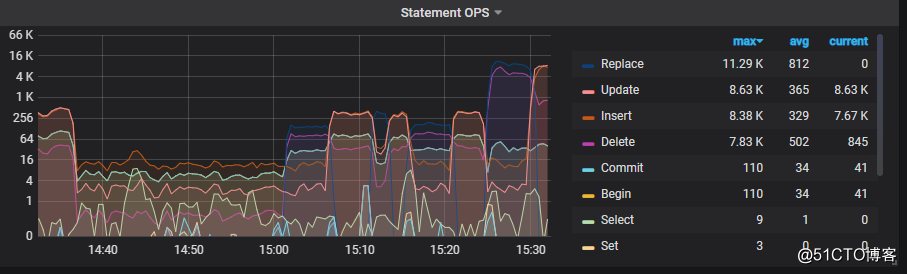
限制worker,库里也有多个而非一个进程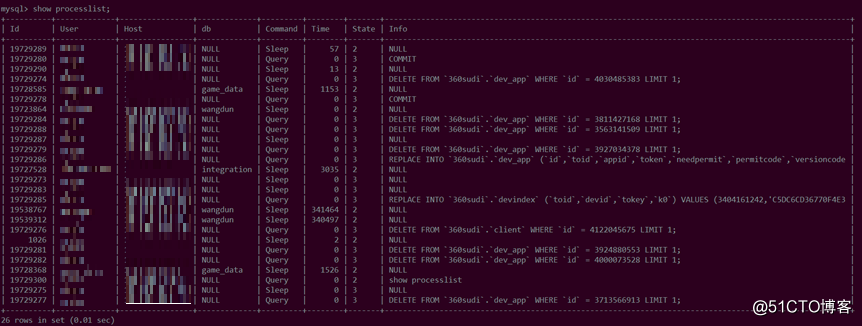
而单个进程依然会报错1062不说,还会导致延迟不断增加,之后我们又调整会16后,能看到快速追上上游主库日志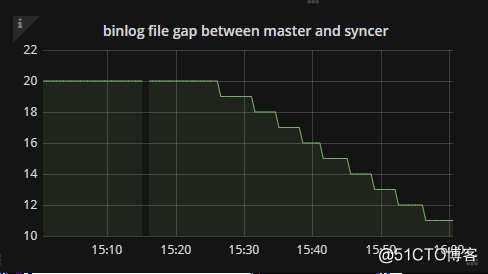
最终我们是通过业务更改replace into解决该问题
六、DM大批量导入调参
集群稳定运行旗舰,有新数据要通过DM灌入,此时会影响已有集群的稳定性
如下图所示,能看到DM导入期间集群响应出现延迟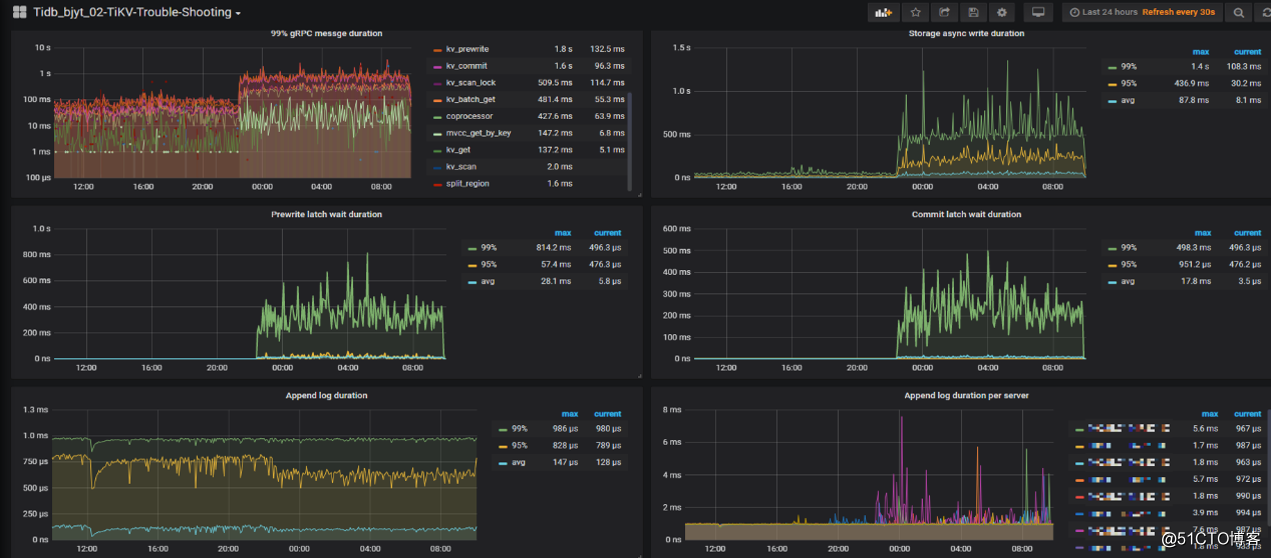
我们通过如下参数从原值调到-新值规避了这一问题,但每个集群场景和配置完全不同,适度谨慎调整,调整前应了解每一个参数的含义,如下仅做参考
raftstore:
apply-pool-size: 3-4
store-pool-size: 3-4
storage:
scheduler-worker-pool-size: 4-6
server:
grpc-concurrency: 4-6
rocksdb:
max-background-jobs: 8-10
max-sub-compactions: 1-2
七、限制
版本限制:
- 数据库版本
- 5.5 < MySQL 版本 < 8.0
- MariaDB 版本 >= 10.1.2
- 仅支持 TiDB parser 支持的 DDL 语法
- 上下游 sql_model 检查
- 上游开启 binlog,且 binlog_format=ROW
DM不支持的类型:
1)一次删除多个分区的操作则会报错:
alter table dsp_group_media_report drop partition p202006 ,p202007 ;
2)drop含有索引的列操作会报错
Alter table dsp_group drop column test_column;
DM-portal限制:
●在早期还没有dm-portal自动化生成task时,我们都是自行编写DM的task同步文件
●后来有了dm-portal自动化生成工具,只要图形页面点点点就可以了
但该工具目前有一个问题是,没有全库正则匹配,几遍你只勾选一个库,他底层是默认把每张表都给你配置一遍。这就会出现当上层MySQL新创建某张表的时候,下游会被忽略掉,例如当你使用改表工具gh-ost或者pt-online-schema-change,你的临时表都会被当做为不在白名单内而被忽略,这个问题使用者需要注意。我们也已经反馈给了官方。且如文章第四节所示,已于1.0.5版本修复。
DM-worker清理配置:
[purge]
interval = 3600
expires = 7
remain-space = 15
关于relay-log,默认是不清理的,就和mysql的expire_logs_days一样,这块可以通过dm-worker的配置文件来进行配置,例如将expires配置为7,代表7天后删除:
#默认expires=0,即没有过期时间,而remain-space=15意思是当磁盘只剩于15G的时候开始尝试清理,这种情况我们极少会碰到,因此这个清理方式其实基本上是用不到的。所以建议有需要删除过期relay-log的小伙伴,直接配置expires保留天数就可以了。
DM导入完成后,应该提供是否在完成后自动删除全备文件的选项,可以默认不删,由使用者决定是否删除。
从使用者角度来说,全量备份目录无论是全量一次性导入还是all增量同步,后续都不会再使用到。如果dm-worker和tikv混部,会导致全备文件占据大量磁盘空间,引起tikv region评分出现异常,导致性能下降,这一点如果有相同的架构的朋友们需得注意。
默认调度策略是当磁盘剩余的有效空间不足 40% ,处于中间态时则同时考虑数据量和剩余空间两个因素做加权和当作得分,当得分出现比较大的差异时,就会开始调度。
所以DM导入完成后,要记得删除全量备份,就是dumped_data.task_xxx文件夹,这个全量备份一般都会比较大,而且默认是不删除的,也没有配置项。如果dm-worker和tikv混部,就会出现某个tikv节点磁盘已使用率高于其他,这时pd的store region score就会相比其他节点出现异常。引起性能抖动和duration升高
八、总结和感慨
零零散散,大大小小的分享也做了很多了,从小白用户第一次在2019年7月接触TiDB,到入选核心成员组,到MVA,到DEVCON 2020作为嘉宾宣讲360在TiDB的分享,再到后续获TUG最具有影响力内容奖章,笔者一直都是本着分享才能让人进步的态度,毫无保留去分享技术干货。因为我真真切切的感受到了TiDB产品本身,以及TiDB社区在不断的做大,做强。就拿我司来说,360集团目前已经8个业务线在使用,4套集群,总数据量接近190TB,稳定流畅运行。目前12月份还接了一个大部门的80人TiDB内部培训,从我自己来说,我要感谢TiDB,感谢社区,我分享的同时,也有很多大牛帮助我改正文中的错误,让我自己也有了进一步的提升。同时我还认识了很多的很多志同道合的朋友,有美团,58同城,新东方,伴鱼,汽车之家,京东数科等等,我愿意进一步去毫无保留的分享,来认识更多的朋友。














