
本文分享自天翼云开发者社区《Flink 与Flink可视化平台StreamPark教程(CDC功能)》,作者:l****n
基本概念
flinkCDC功能是面向binlog进行同步、对数据的增删改进行同步的工具,能够实现对数据的动态监听。目前其实现原理主要为监听数据源的binlog对数据的变化有所感知。
在这里,我们只需引入相关依赖即可进行操作,如下所示
<!-- flink connector cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink.sql.connector.cdc.version}</version>
</dependency>需要注意的是,flinkcdc关于flink的版本严格,在选择相应的cdc版本时,可查看相关官方的依赖表,在本实例中,选择2.2.1版本的mysqlcdc进行演示。
| Flink® CDC Version | Flink® Version |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13., 1.14. |
| 2.3.* | 1.13., 1.14., 1.15.*, 1.16.0 |
Flink SQL CDC 内置了 Debezium 引擎,利用其抽取日志获取变更的能力,将 changelog 转换为 Flink SQL 认识的 RowData 数据。RowData 代表了一行的数据,在 RowData 上面会有一个元数据的信息 RowKind,RowKind 里面包括了插入(+I)、更新前(-U)、更新后(+U)、删除(-D),这样和数据库里面的 binlog 概念十分类似。通过 Debezium 采集的数据,包含了旧数据(before)和新数据行(after)以及原数据信息(source),op 的 u表示是 update 更新操作标识符(op 字段的值c,u,d,r 分别对应 create,update,delete,reade),ts_ms 表示同步的时间戳。
使用api进行操作
使用flink标准DataStreamApi进行开发,能够配合CDC功能对数据的动态输入进行获取。如下代码实现了一个从mysql进行动态CDC读取的样例,这里使用了相应的mysql-cdc的数据源依赖进行读取。```
package cn.ctyun.demo.api.watermark;
import cn.ctyun.demo.api.utils.TransformUtil;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
public class ViewContentStreamWithoutWaterMark {
public static DataStream<JSONObject> getViewContentDataStream(StreamExecutionEnvironment env){
// 1.创建Flink-MySQL-CDC的Source
MySqlSource<String> viewContentSouce = MySqlSource.<String>builder()
.hostname("49.7.189.190")
.port(3307)
.username("root")
.password("Adm@163.comCdc")
.databaseList("test_cdc_source")
.tableList("test_cdc_source.view_content")
.startupOptions(StartupOptions.initial())
.deserializer(new JsonDebeziumDeserializationSchema())
.serverTimeZone("Asia/Shanghai")
.build();
// 2.使用CDC Source从MySQL读取数据
DataStreamSource<String> mysqlDataStreamSource = env.fromSource(
viewContentSouce,
WatermarkStrategy.noWatermarks(),
"ViewContentStreamNoWatermark Source"
);
// 3.转换为指定格式
return mysqlDataStreamSource.map(TransformUtil::formatResult);
}
}使用flinksql进行操作
flinksql操作,能够简化大量操作,具体如下代码所示。在这里我们只需要提供简单的sql语句即可完成对mysql数据源的动态读取。通过指定连接器类型为'connector' = 'mysql-cdc',通过此配置项调用mysql cdc连接器。
package cn.ctyun.demo.flinksql;
import cn.ctyun.demo.flinksql.udf.HashScalarFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @classname: ReadFromCdc
* @description: 通过cdc获取数据变化进行输入
* @author: Liu Xinyuan
* @create: 2023-04-12 15:09
**/
public class FlinkSqlReadFromCdc {
public static void main(String[] args) throws Exception {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.disableOperatorChaining();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1. 创建读取表,使用mysql-cdc进行,注意此时应标记主键
String source_ddl = "CREATE TABLE UserSource (" +
" id INT, " +
" name VARCHAR, " +
" phone VARCHAR, " +
" sex INT, " +
" primary key (id) not enforced" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = '*******'," +
" 'port' = '3307'," +
" 'username' = '" + parameterTool.get("user") + "', " +
" 'password' = '" + parameterTool.get("passwd") + "'" +
" 'database-name' = 'test_cdc_source'," +
" 'table-name' = 'test_user_table'," +
" 'debezium.log.mining.continuous.mine'='true',"+
" 'debezium.log.mining.strategy'='online_catalog', " +
" 'debezium.database.tablename.case.insensitive'='false',"+
" 'jdbc.properties.useSSL' = 'false' ," +
" 'scan.startup.mode' = 'initial')";
tableEnv.executeSql(source_ddl);
// 2. 创建写出表,使用mysql进行
String sink_ddl = "CREATE TABLE UserSink (" +
" id INT, " +
" name VARCHAR, " +
" phone VARCHAR, " +
" sex INT, " +
" primary key (id) not enforced" +
") WITH (" +
" 'connector.type' = 'jdbc', " +
" 'connector.url' = 'jdbc:mysql://******:3306/flink_test_sink?useSSL=false', " +
" 'connector.table' = 'test_user_table', " +
" 'connector.username' = '" + parameterTool.get("sinkUser") + "', " +
" 'connector.password' = '" + parameterTool.get("sinkPasswd") + "'" +
" 'connector.write.flush.max-rows' = '1'" +
")";
tableEnv.executeSql(sink_ddl);
// 3.简单的数据清洗,将电话号码进行hash掩码
tableEnv.createTemporarySystemFunction("MyHASH", HashScalarFunction.class);
Table maskedTable = tableEnv.sqlQuery("SELECT id, name, MyHASH(phone) as phone, sex FROM UserSource");
tableEnv.createTemporaryView("MaskedUserInfo", maskedTable);
// 4.使用insert语句进行数据输出,在这里进行一定地清洗
String insertSql = "INSERT INTO UserSink SELECT * FROM MaskedUserInfo";
TableResult tableResult = tableEnv.executeSql(insertSql);
tableResult.print();
}
}刚才的代码中定义了一套简单的数据同步+电话号码掩码的操作。这里重点看cdc相关的配置项,如下所示。这里有一个重点的配置项, 'scan.startup.mode' = 'initial'此处是cdc的关键所在,MySQL CDC 消费者可选的启动模式, 合法的模式为 "initial","earliest-offset","latest-offset","specific-offset" 和 "timestamp"。这里使用的initial模式为在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog,也就是先进行一次全表扫描后再进行后续的增量同步,由于测试数据较小可以如此进行,cdc的使用者可以根据个人情况进行选择。
String source_ddl = "CREATE TABLE UserSource (" +
" id INT, " +
" name VARCHAR, " +
" phone VARCHAR, " +
" sex INT, " +
" primary key (id) not enforced" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = '******'," +
" 'port' = '3307'," +
" 'username' = '" + parameterTool.get("user") + "', " +
" 'password' = '" + parameterTool.get("passwd") + "'" +
" 'database-name' = 'test_cdc_source'," +
" 'table-name' = 'test_user_table'," +
" 'debezium.log.mining.continuous.mine'='true',"+
" 'debezium.log.mining.strategy'='online_catalog', " +
" 'debezium.database.tablename.case.insensitive'='false',"+
" 'jdbc.properties.useSSL' = 'false' ," +
" 'scan.startup.mode' = 'initial')";启用后,整个流程为对其中的数据增量同步,由于我们使用的是initial模式,因此我们的数据在任务启动的时候,首先进行了一次全量同步,全量地将信息同步,并且进行了掩码操作。

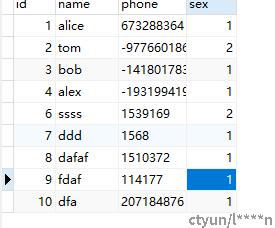 后续如果添加新的信息也会进行同步,删除亦然。
后续如果添加新的信息也会进行同步,删除亦然。
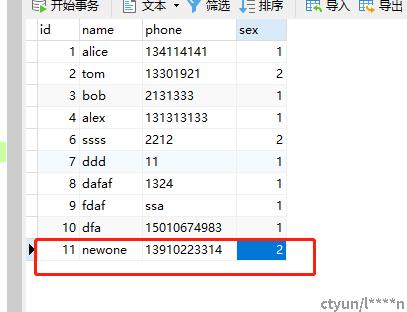
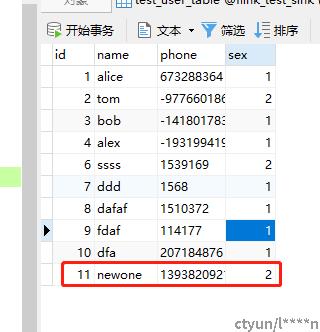
断点续传
断点续传功能是flink-cdc在2.0版本后逐渐推行的新功能。此功能能够支持使用savepoint、checkpoint等方式进行断点续传功能。意思为如果我们在中途保留一个保存点,那么任务如果重启的话将会从保存点开始同步cdc数据,中间不会遗失数据(除非手动删除binlog)。目前flink cdc如果需要实现断点续传则需要开启checkpoint功能。关于flink的savepoint、checkpoint功能将会在后续章节展开进行讲解。


