
LangChain
LangChain是一个以 LLM (大语言模型)模型为核心的开发框架,LangChain的主要特性:
- 可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等
- 允许语言模型与其环境交互
- 封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件
- 可以使用链的方式组装这些组件,以便最好地完成特定用例。
围绕以上设计原则,LangChain解决了现在开发人工智能应用的一些切实痛点。以 GPT 模型为例:
- 数据滞后,现在训练的数据是到 2021年9月。
- token数量限制,如果让它对一个300页的pdf进行总结,直接使用则无能为力。
- 不能进行联网,获取不到最新的内容。
- 不能与其他数据源链接。
另外作为一个胶水层框架,极大地提高了开发效率,它的作用可以类比于jquery在前端开发中的角色,使得开发者可以更专注于创新和优化产品功能。

1、Model I/O
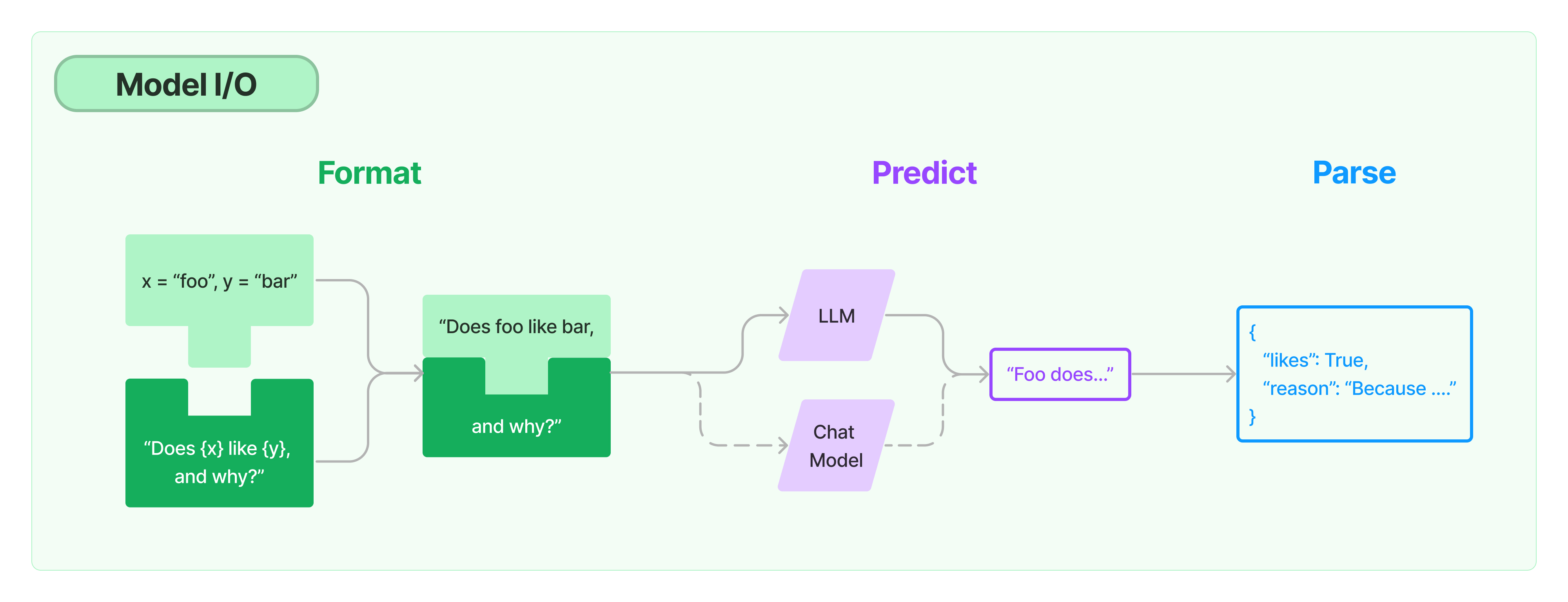
LangChain提供了与任何语言模型交互的构建块,交互的输入输出主要包括:Prompts、Language models、Output parsers三部分。
1.1 Prompts
LangChain 提供了多个类和函数,使构建和使用提示词变得容易。Prompts模块主要包含了模板化、动态选择和管理模型输入两部分。其中:
1.1.1 Prompt templates
提示模版类似于ES6模板字符串,可以在字符串中插入变量或表达式,接收来自最终用户的一组参数并生成提示。
一个简单的例子:
const multipleInputPrompt = new PromptTemplate({
inputVariables: ["adjective", "content"],
template: "Tell me a {adjective} joke about {content}.",
});
const formattedMultipleInputPrompt = await multipleInputPrompt.format({
adjective: "funny",
content: "chickens",
});
console.log(formattedMultipleInputPrompt);
// "Tell me a funny joke about chickens.
同时可以通过 PipelinePrompt将多个PromptTemplate提示模版进行组合,组合的优点是可以很方便的进行复用。比如常见的系统角色提示词,一般都遵循以下结构:{introduction} {example} {start},比如一个【名人采访】角色的提示词:
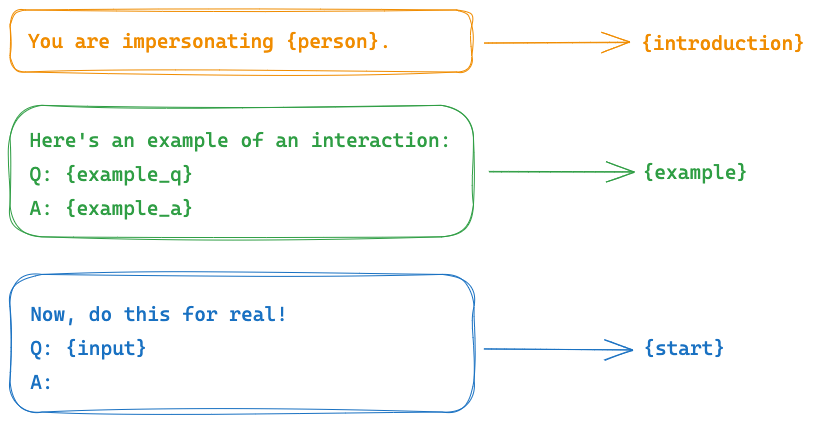
使用PipelinePrompt组合实现:
import { PromptTemplate, PipelinePromptTemplate } from "langchain/prompts";
const fullPrompt = PromptTemplate.fromTemplate(`{introduction}
{example}
{start}`);
const introductionPrompt = PromptTemplate.fromTemplate(
`You are impersonating {person}.`
);
const examplePrompt =
PromptTemplate.fromTemplate(`Here's an example of an interaction:
Q: {example_q}
A: {example_a}`);
const startPrompt = PromptTemplate.fromTemplate(`Now, do this for real!
Q: {input}
A:`);
const composedPrompt = new PipelinePromptTemplate({
pipelinePrompts: [
{
name: "introduction",
prompt: introductionPrompt,
},
{
name: "example",
prompt: examplePrompt,
},
{
name: "start",
prompt: startPrompt,
},
],
finalPrompt: fullPrompt,
});
const formattedPrompt = await composedPrompt.format({
person: "Elon Musk",
example_q: `What's your favorite car?`,
example_a: "Telsa",
input: `What's your favorite social media site?`,
});
console.log(formattedPrompt);
/*
You are impersonating Elon Musk.
Here's an example of an interaction:
Q: What's your favorite car?
A: Telsa
Now, do this for real!
Q: What's your favorite social media site?
A:
*/
1.1.2 Example selectors
为了大模型能够给出相对精准的输出内容,通常会在prompt中提供一些示例描述,如果包含大量示例会浪费token数量,甚至可能会超过最大token限制。为此,LangChain提供了示例选择器,可以从用户提供的大量示例中,选择最合适的部分作为最终的prompt。通常有2种方式:按长度选择和按相似度选择。
按长度选择:对于较长的输入,它将选择较少的示例来;而对于较短的输入,它将选择更多的示例。
...
// 定义长度选择器
const exampleSelector = await LengthBasedExampleSelector.fromExamples(
[
{ input: "happy", output: "sad" },
{ input: "tall", output: "short" },
{ input: "energetic", output: "lethargic" },
{ input: "sunny", output: "gloomy" },
{ input: "windy", output: "calm" },
],
{
examplePrompt,
maxLength: 25,
}
);
...
// 最终会根据用户的输入长度,来选择合适的示例
// 用户输入较少,选择所有示例
console.log(await dynamicPrompt.format({ adjective: "big" }));
/*
Give the antonym of every input
Input: happy
Output: sad
Input: tall
Output: short
Input: energetic
Output: lethargic
Input: sunny
Output: gloomy
Input: windy
Output: calm
Input: big
Output:
*/
// 用户输入较多,选择其中一个示例
const longString =
"big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else";
console.log(await dynamicPrompt.format({ adjective: longString }));
/*
Give the antonym of every input
Input: happy
Output: sad
Input: big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else
Output:
*/
按相似度选择:查找与输入具有最大余弦相似度的嵌入示例
...
// 定义相似度选择器
const exampleSelector = await SemanticSimilarityExampleSelector.fromExamples(
[
{ input: "happy", output: "sad" },
{ input: "tall", output: "short" },
{ input: "energetic", output: "lethargic" },
{ input: "sunny", output: "gloomy" },
{ input: "windy", output: "calm" },
],
new OpenAIEmbeddings(),
HNSWLib,
{ k: 1 }
);
...
// 跟天气类相关的示例
console.log(await dynamicPrompt.format({ adjective: "rainy" }));
/*
Give the antonym of every input
Input: sunny
Output: gloomy
Input: rainy
Output:
*/
// 跟尺寸相关的示例
console.log(await dynamicPrompt.format({ adjective: "large" }));
/*
Give the antonym of every input
Input: tall
Output: short
Input: large
Output:
*/
1.2 Language models
LangChain支持多种常见的Language models提供商(详见附录一),并提供了两种类型的模型的接口和集成:
- LLM:采用文本字符串作为输入并返回文本字符串的模型
- Chat models:由语言模型支持的模型,但将聊天消息列表作为输入并返回聊天消息
定义一个LLM语言模型:
import { OpenAI } from "langchain/llms/openai";
// 实例化一个模型
const model = new OpenAI({
// OpenAI内置参数
openAIApiKey: "YOUR_KEY_HERE",
modelName: "text-davinci-002", //gpt-4、gpt-3.5-turbo
maxTokens: 25,
temperature: 1, //发散度
// LangChain自定义参数
maxRetries: 10, //发生错误后重试次数
maxConcurrency: 5, //最大并发请求次数
cache: true //开启缓存
});
// 使用模型
const res = await model.predict("Tell me a joke");
取消请求和超时处理:
import { OpenAI } from "langchain/llms/openai";
const model = new OpenAI({ temperature: 1 });
const controller = new AbortController();
const res = await model.call(
"What would be a good name for a company that makes colorful socks?",
{
signal: controller.signal, //调用controller.abort()即可取消请求
timeout: 1000 //超时时间设置
}
);
流式响应:通常,当我们请求一个服务或者接口时,服务器会将所有数据一次性返回给我们,然后我们再进行处理。但是,如果返回的数据量很大,那么我们需要等待很长时间才能开始处理数据。
而流式响应则不同,它将数据分成多个小块,每次只返回一部分数据给我们。我们可以在接收到这部分数据之后就开始处理,而不需要等待所有数据都到达。
import { OpenAI } from "langchain/llms/openai";
const model = new OpenAI({
maxTokens: 25,
});
const stream = await model.stream("Tell me a joke.");
for await (const chunk of stream) {
console.log(chunk);
}
/*
Q
:
What
did
the
fish
say
when
it
hit
the
wall
?
A
:
Dam
!
*/
此外,所有的语言模型都实现了Runnable 接口,默认实现了invoke,batch,stream,map等方法, 提供了对调用、流式传输、批处理和映射请求的基本支持
1.3 Output parsers
语言模型可以输出文本或富文本信息,但很多时候,我们可能想要获得结构化信息,比如常见的JSON结构可以和应用程序更好的结合。LangChain封装了一下几种输出解析器:
| 名称 | 中文名 | 解释 |
|---|---|---|
| BytesOutputParser | 字节输出 | 转换为二进制数据 |
| CombiningOutputParser | 组合输出 | 组合不同的解析器 |
| CustomListOutputParser | 自定义列表输出 | 指定分隔符并分割为数组格式 |
| JsonOutputFunctionsParser | JSON函数输出 | 结合OpenAI回调函数格式化输出 |
| OutputFixingParser | 错误修复 | 解析失败时再次调用LLM以修复错误 |
| StringOutputParser | 字符串输出 | 转换为字符串 |
| StructuredOutputParser | 结构化输出 | 通常结合Zod格式化为JSON对象 |
一个自定义列表的解析器案例:
...
const parser = new CustomListOutputParser({ length: 3, separator: "\n" });
const chain = RunnableSequence.from([
PromptTemplate.fromTemplate(
"Provide a list of {subject}.\n{format_instructions}"
),
new OpenAI({ temperature: 0 }),
parser,
]);
/* 最终生成的prompt
Provide a list of great fiction books (book, author).
Your response should be a list of 3 items separated by "\n" (eg: `foo\n bar\n baz`)
*/
const response = await chain.invoke({
subject: "great fiction books (book, author)",
format_instructions: parser.getFormatInstructions(),
});
console.log(response);
/*
[
'The Catcher in the Rye, J.D. Salinger',
'To Kill a Mockingbird, Harper Lee',
'The Great Gatsby, F. Scott Fitzgerald'
]
*/
一个完整的Model I/O案例:将一个国家的信息:名称、首都、面积、人口等信息结构化输出
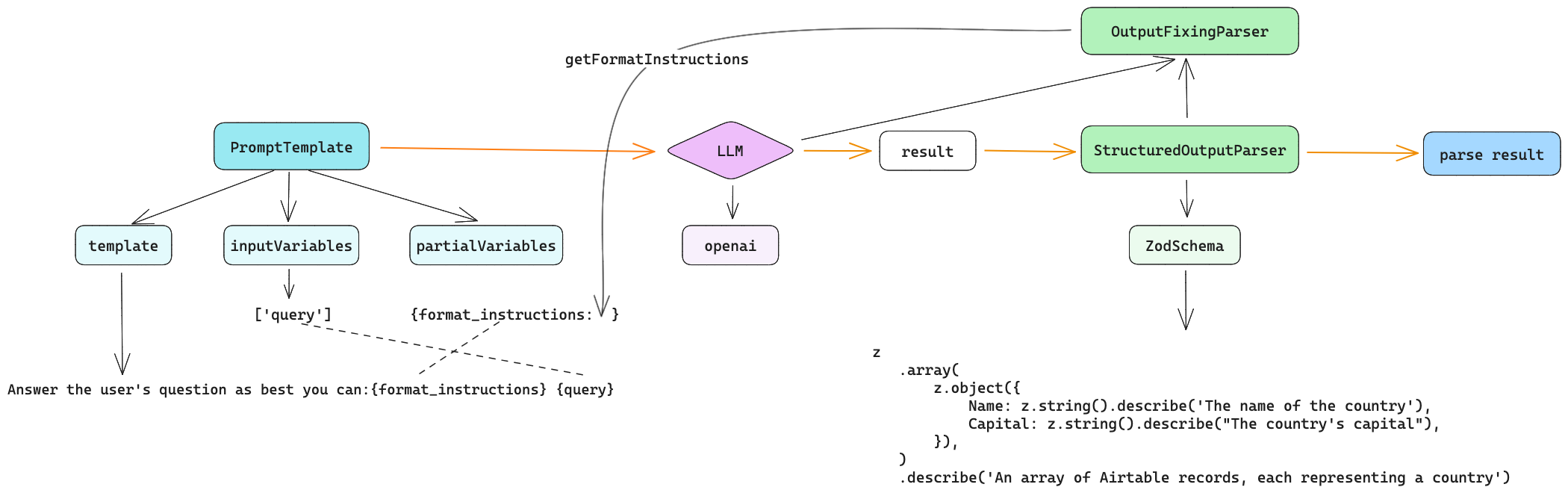
2、Retrieval
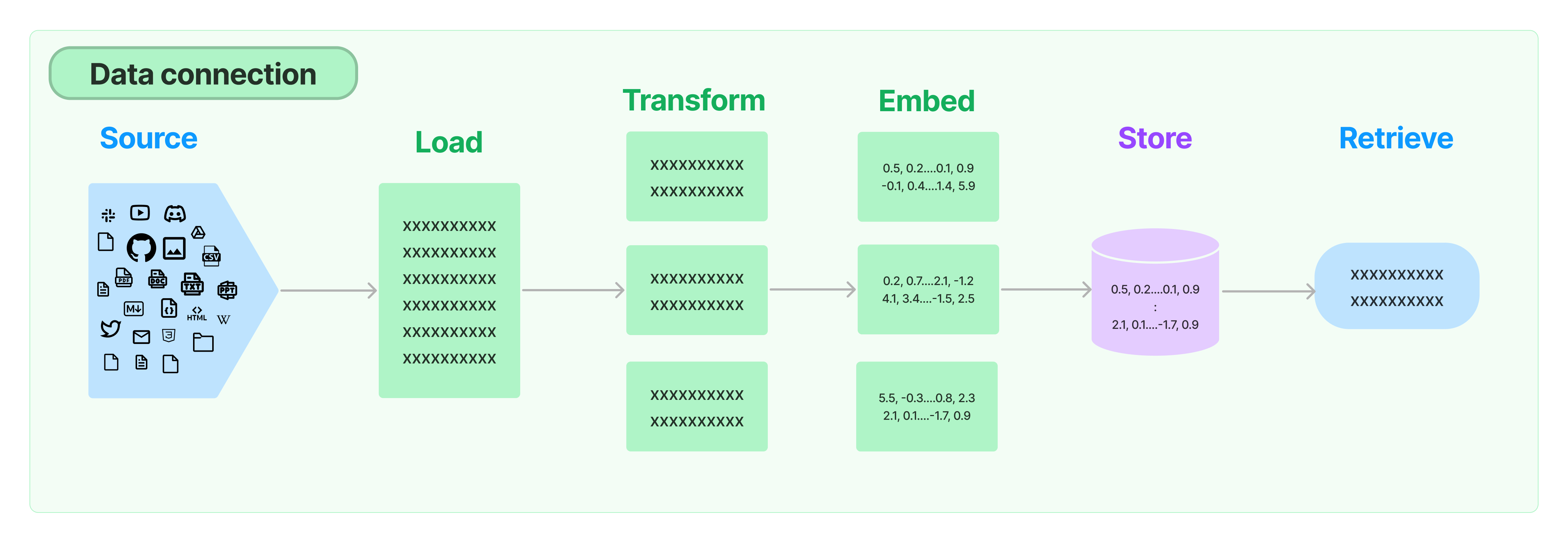
一些LLM应用通常需要特定的用户数据,这些数据不属于模型训练集的一部分。可以通过检索增强生成(RAG)的方式,检索外部数据,然后在执行生成步骤时将其传递给 LLM 。LangChain 提供了 RAG 应用程序的所有构建模块,包含以下几个关键模块:
2.1 Document loaders
Document loaders可以从各种数据源加载文档。LangChain 提供了许多不同的文档加载器以及与对应的第三方集成工具。下图中,黄色颜色代表Loaders对应的npm第三方依赖库。
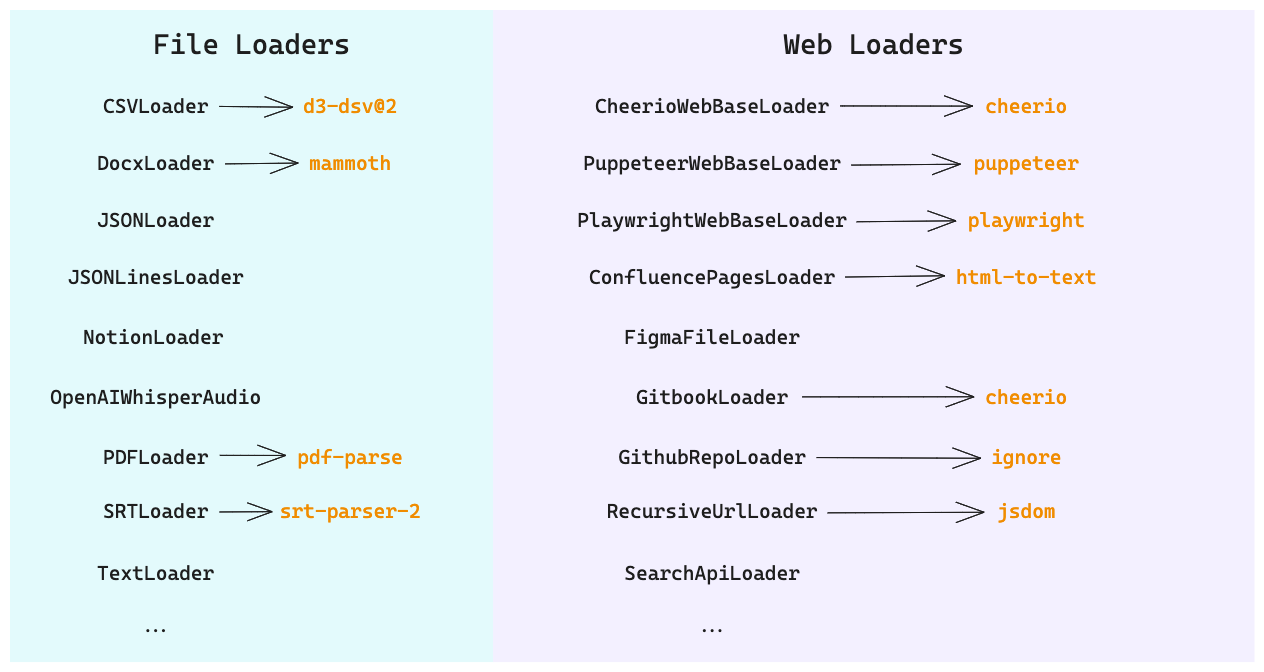
返回的文档对象格式如下:
interface Document {
pageContent: string;
metadata: Record<string, any>;
}
2.2 Document transformers
加载文档后,通常需要进行数据处理,比如:将长文档分割成更小的块、过滤不需要的HTML标签以及结构化处理等。LangChain提供了许多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档。
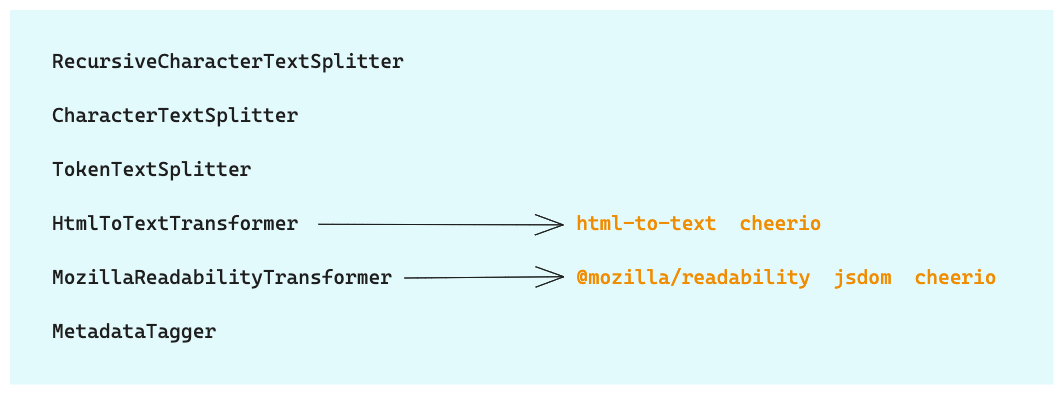
其中:
- RecursiveCharacterTextSplitter除了可以按指定分隔符进行分割外,还支持根据特定于语言的语法分割文本,比如:JavaScript、Python、Solidity 和 Rust 等流行语言,以及 Latex、HTML 和 Markdown。
- 当处理大量任意文档集合时,简单的文本分割可能会出现重叠文本的文档,CharacterTextSplitter可以用元数据标记文档,从而解决矛盾来源的信息等问题。
- 当提取 HTML 文档以供以后检索时,我们通常只对网页的实际内容而不是语义感兴趣。HtmlToTextTransformer和MozillaReadabilityTransformer都可以从文档中剥离HTML标签,从而使检索更加有效
- MetadataTagger转换器可以自动从文档中提取元数据,以便以后进行更有针对性的相似性搜索。
一个简单文本分割示例:
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
const text = `Hi.\n\nI'm Harrison.\n\nHow? Are? You?\nOkay then f f f f.
This is a weird text to write, but gotta test the splittingggg some how.\n\n
Bye!\n\n-H.`;
const splitter = new RecursiveCharacterTextSplitter({
separators: ["\n\n", "\n", " ", ""], //默认分隔符
chunkSize: 1000, //最终文档的最大大小(以字符数计),默认1000
chunkOverlap: 200, //块之间应该有多少重叠,默认200
});
const output = await splitter.createDocuments([text]);
2.3 Text embedding models
文本嵌入模型(Text embedding models)是用于创建文本数据的数值表示的模型。它可以将文本转换为向量表示,从而在向量空间中进行语义搜索和查找相似文本。LangChain嵌入模型提供了标准接口,可以与多个Language models提供商(详见附录一)进行集成。
一个OpenAI的嵌入示例:通常要结合文档(Document)和向量存储(Vector stores)一起使用。
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
/* Create instance */
const embeddings = new OpenAIEmbeddings();
/* Embed queries */
const res = await embeddings.embedQuery("Hello world");
/*
[
-0.004845875, 0.004899438, -0.016358767, -0.024475135, -0.017341806,
0.012571548, -0.019156644, 0.009036391, -0.010227379, -0.026945334,
0.022861943, 0.010321903, -0.023479493, -0.0066544134, 0.007977734,
... 1436 more items
]
*/
/* Embed documents */
const documentRes = await embeddings.embedDocuments(["Hello world", "Bye bye"]);
/*
[
[
-0.0047852774, 0.0048640342, -0.01645707, -0.024395779, -0.017263541,
0.012512918, -0.019191515, 0.009053908, -0.010213212, -0.026890801,
0.022883644, 0.010251015, -0.023589306, -0.006584088, 0.007989113,
... 1436 more items
],
[
-0.009446913, -0.013253193, 0.013174579, 0.0057552797, -0.038993083,
0.0077763423, -0.0260478, -0.0114384955, -0.0022683728, -0.016509168,
0.041797023, 0.01787183, 0.00552271, -0.0049789557, 0.018146982,
... 1436 more items
]
]
*/
2.4 Vector stores
Vector stores是用于存储和搜索嵌入式数据的一种技术,负责存储嵌入数据并执行向量搜索。它通过将文本或文档转换为嵌入向量,并在查询时嵌入非结构化查询,以检索与查询最相似的嵌入向量来实现。LangChain中提供了非常多的向量存储方案,以下指南可帮助您为您的用例选择正确的向量存储:
- 如果您正在寻找可以在 Node.js 应用程序内运行,无需任何其他服务器来支持,那么请选择HNSWLib、Faiss、LanceDB或CloseVector
- 如果您正在寻找可以在类似浏览器的环境内存中运行,那么请选择MemoryVectorStore或CloseVector
- 如果您来自 Python 并且正在寻找类似于 FAISS 的东西,请尝试HNSWLib或Faiss
- 如果您正在寻找可以在 Docker 容器中本地运行的开源全功能矢量数据库,那么请选择Chroma
- 如果您正在寻找一个提供低延迟、本地文档嵌入并支持边缘应用程序的开源矢量数据库,那么请选择Zep
- 如果您正在寻找可以在本地Docker 容器中运行或托管在云中的开源生产就绪矢量数据库,那么请选择Weaviate。
- 如果您已经在使用 Supabase,那么请查看Supabase矢量存储。
- 如果您正在寻找可用于生产的矢量存储,不需要自己托管,那么就选择Pinecone
- 如果您已经在使用 SingleStore,或者您发现自己需要分布式高性能数据库,那么您可能需要考虑SingleStore矢量存储。
- 如果您正在寻找在线 MPP(大规模并行处理)数据仓库服务,您可能需要考虑AnalyticDB矢量存储。
- 如果您正在寻找一个经济高效的矢量数据库,允许使用 SQL 运行矢量搜索,那么MyScale就是您的最佳选择。
- 如果您正在寻找可以从浏览器端和服务器端加载的矢量数据库,请查看CloseVector。它是一个旨在跨平台的矢量数据库。
示例:读取本地文档,创建MemoryVectorStore和检索
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { TextLoader } from "langchain/document_loaders/fs/text";
// Create docs with a loader
const loader = new TextLoader("src/document_loaders/example_data/example.txt");
const docs = await loader.load();
// Load the docs into the vector store
const vectorStore = await MemoryVectorStore.fromDocuments(
docs,
new OpenAIEmbeddings()
);
// Search for the most similar document
const resultOne = await vectorStore.similaritySearch("hello world", 1);
console.log(resultOne);
/*
[
Document {
pageContent: "Hello world",
metadata: { id: 2 }
}
]
*/
2.5 Retrievers
检索器(Retriever)是一个接口:根据非结构化查询返回文档。它比Vector Store更通用,创建Vector Store后,将其用作检索器的方法非常简单:
...
retriever = vectorStore.asRetriever()
此外,LangChain还提供了他类型的检索器,比如:
- ContextualCompressionRetriever:用给定查询的上下文来压缩它们,以便只返回相关信息,而不是立即按原样返回检索到的文档,同时还可以减少token数量。
- MultiQueryRetriever:从不同角度为给定的用户输入查询生成多个查询。
- ParentDocumentRetriever:在检索过程中,它首先获取小块,然后查找这些块的父 ID,并返回那些较大的文档。
- SelfQueryRetriever:一种能够查询自身的检索器。
- VespaRetriever:从Vespa.ai数据存储中检索文档。
针对不同的需求场景,可能需要对应的合适的检索器。以下是一个根据通过计算相似度分值检索的示例:
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { ScoreThresholdRetriever } from "langchain/retrievers/score_threshold";
const vectorStore = await MemoryVectorStore.fromTexts(
[
"Buildings are made out of brick",
"Buildings are made out of wood",
"Buildings are made out of stone",
"Buildings are made out of atoms",
"Buildings are made out of building materials",
"Cars are made out of metal",
"Cars are made out of plastic",
],
[{ id: 1 }, { id: 2 }, { id: 3 }, { id: 4 }, { id: 5 }],
new OpenAIEmbeddings()
);
const retriever = ScoreThresholdRetriever.fromVectorStore(vectorStore, {
minSimilarityScore: 0.9, // Finds results with at least this similarity score
maxK: 100, // The maximum K value to use. Use it based to your chunk size to make sure you don't run out of tokens
kIncrement: 2, // How much to increase K by each time. It'll fetch N results, then N + kIncrement, then N + kIncrement * 2, etc.
});
const result = await retriever.getRelevantDocuments(
"What are buildings made out of?"
);
console.log(result);
/*
[
Document {
pageContent: 'Buildings are made out of building materials',
metadata: { id: 5 }
},
Document {
pageContent: 'Buildings are made out of wood',
metadata: { id: 2 }
},
Document {
pageContent: 'Buildings are made out of brick',
metadata: { id: 1 }
},
Document {
pageContent: 'Buildings are made out of stone',
metadata: { id: 3 }
},
Document {
pageContent: 'Buildings are made out of atoms',
metadata: { id: 4 }
}
]
*/
一个完整的Retrieval案例:从指定URL地址(静态网站)中加载文档信息,进行分割生成嵌入信息并存储为向量,跟据用户的问题进行检索。(请使用公开信息,防止隐私数据泄漏)
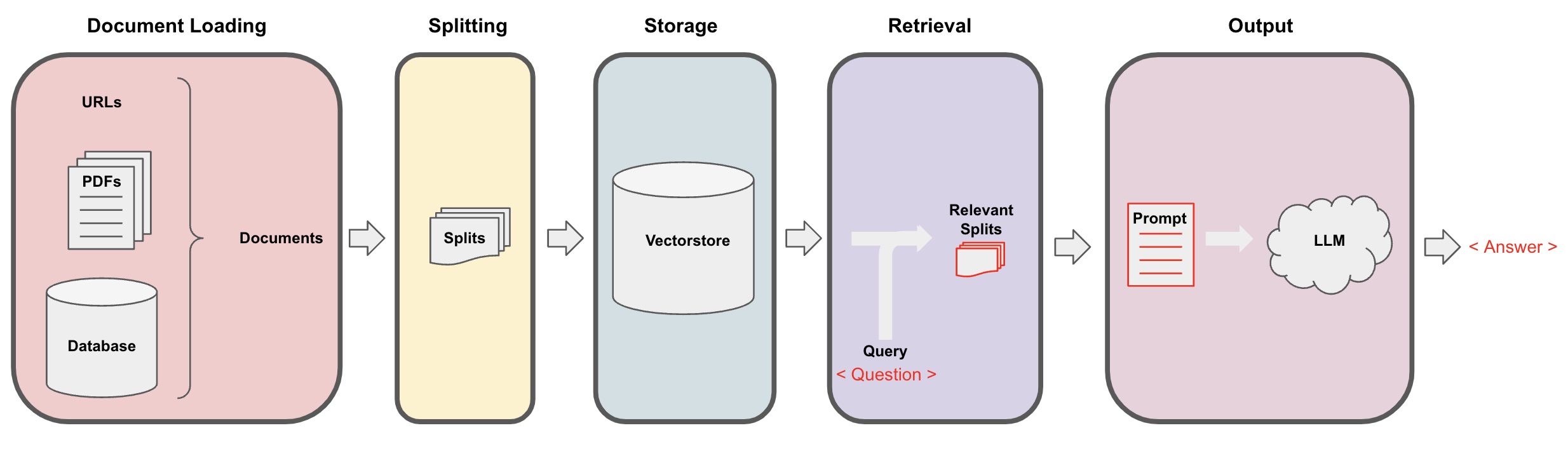
3、Chains
Chains是一种将多个组件组合在一起创建单一、连贯应用程序的方法。通过使用Chains,我们可以创建一个接受用户输入、使用PromptTemplate格式化输入并将格式化的响应传递给LLM的链。我们可以通过将多个链组合在一起或将链与其他组件组合来构建更复杂的链。LangChain中内置了很多不同类型的Chain:
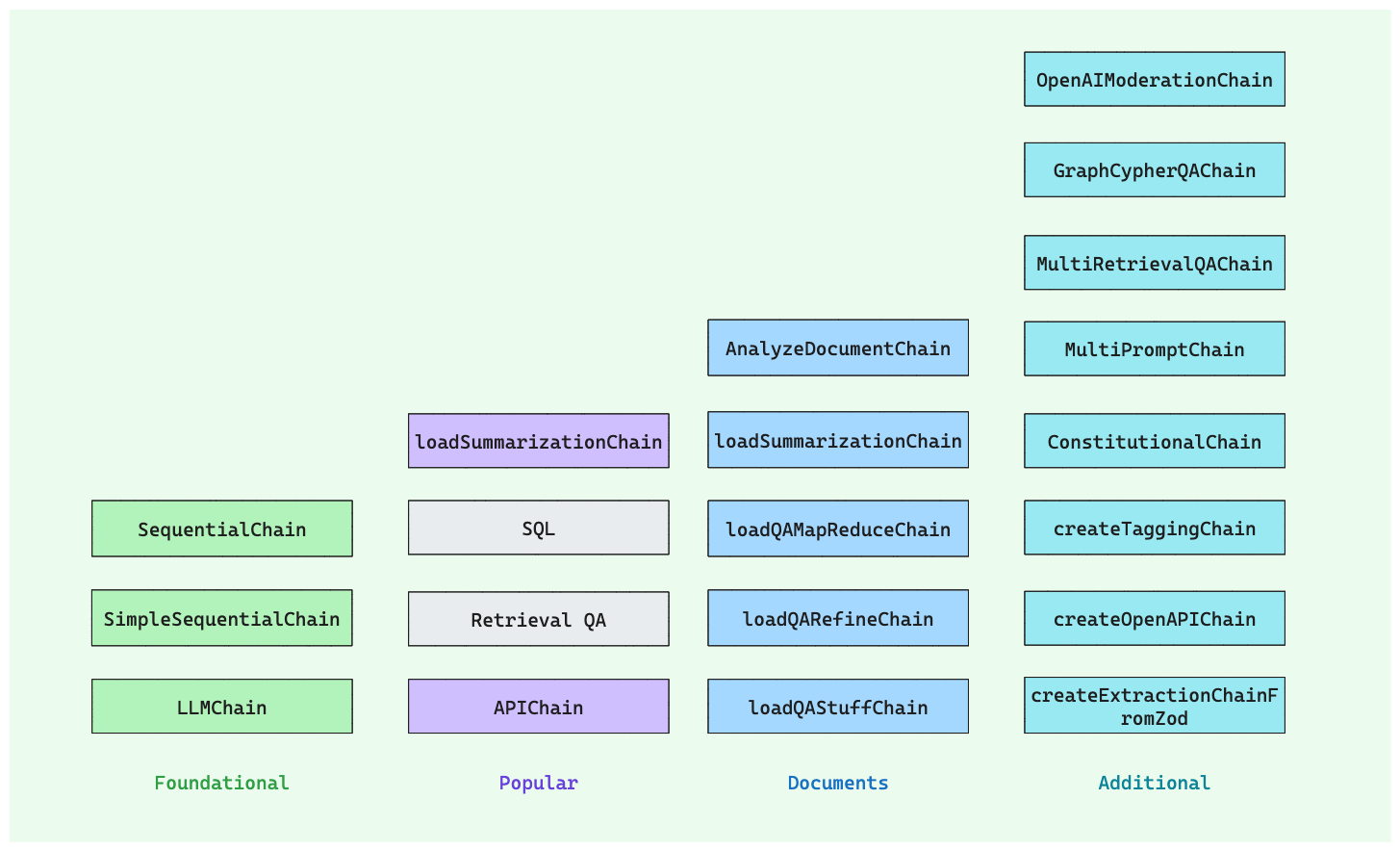
其中:
- LLMChain:最基本的链。它采用提示模板,根据用户输入对其进行格式化,然后返回LLM的响应。
- SimpleSequentialChain和SequentialChain:一个调用的输出用作另一个调用的输入,进行一系列调用。前者每个步骤都有一个单一的输入/输出,后者更通用,允许多个输入/输出。
- loadQAStuffChain、loadQARefineChain、loadQAMapReduceChain、loadSummarizationChain和AnalyzeDocumentChain这些是处理文档的核心链。它们对于总结文档、回答文档问题、从文档中提取信息等很有用。
- APIChain:允许使用 LLM 与 API 交互以检索相关信息。通过提供与所提供的 API 文档相关的问题来构建链。
- createOpenAPIChain:可以仅根据 OpenAPI 规范自动选择和调用 API。它将输入 OpenAPI 规范解析为 OpenAI 函数 API 可以处理的 JSON 模式。
- loadSummarizationChain:摘要链可用于汇总多个文档,生成摘要。
- createExtractionChainFromZod:从输入文本和所需信息的模式中提取结构化信息。
- MultiPromptChain:基于RouterChain,从多个prompt中选择合适的一个,比如定义多个老师的提示。
- MultiRetrievalQAChain:基于RouterChain,从多个检索器中动态选择。
以下是一个从【2020年美国国情咨文】中生成摘要的示例:
import { OpenAI } from "langchain/llms/openai";
import { loadSummarizationChain, AnalyzeDocumentChain } from "langchain/chains";
import * as fs from "fs";
// In this example, we use the `AnalyzeDocumentChain` to summarize a large text document.
const text = fs.readFileSync("state_of_the_union.txt", "utf8");
const model = new OpenAI({ temperature: 0 });
const combineDocsChain = loadSummarizationChain(model);
const chain = new AnalyzeDocumentChain({
combineDocumentsChain: combineDocsChain,
});
const res = await chain.call({
input_document: text,
});
console.log({ res });
/*
{
res: {
text: ' President Biden is taking action to protect Americans from the COVID-19 pandemic and Russian aggression, providing economic relief, investing in infrastructure, creating jobs, and fighting inflation.
He is also proposing measures to reduce the cost of prescription drugs, protect voting rights, and reform the immigration system. The speaker is advocating for increased economic security, police reform, and the Equality Act, as well as providing support for veterans and military families.
The US is making progress in the fight against COVID-19, and the speaker is encouraging Americans to come together and work towards a brighter future.'
}
}
*/
4、GPTs
Open AI最新发布会,发布了GPTs相关的功能:用户可以用自然语言的方式,来构建自己的GPT应用:简单的比如一个根据提示词生成的各种系统角色;或者通过自定义Action实现一些复杂的功能:比如调用第三方API、读取本地或网络文档等。在一定程度上可以不用通过LangChain等编码来实现增强检索等,但是LangChain的一些思路和实现还是值得学习和借鉴的,比如LangChain中可以使用本地化部署的LLM和向量存储等,来解决隐私数据泄漏问题。
参考文献:
https://js.langchain.com/docs/get_started/introduction
作者:京东科技 牛志伟
来源:京东云开发者社区 转载请注明来源







