
源自:控制与决策 作者:薛俊韬 马若寒 胡超芳
摘要
针对深度学习算法在多目标跟踪中的实时性问题, 提出一种基于MobileNet的多目标跟踪算法. 借助于MobileNet深度可分离卷积能够对深度网络模型进行压缩的原理, 将YOLOv3主干网络替换为MobileNet, 通过将标准卷积分解为深度卷积和逐点卷积, 保留多尺度预测部分, 以有效减少参数量. 对于检测得到的边框信息, 利用Deep-SORT算法进行跟踪. 实验结果表明, 所提出方法在跟踪效果基本不变的情况下可提升处理速度近50%.
关键词
深度学习 多目标跟踪 目标检测 YOLOv3 deep-SORT MobileNet
0 引言
多目标跟踪是计算机视觉领域的研究热点, 可应用于交通监测、安防等多个领域, 具有一定的应用价值和挑战性[1]. 检测方式可以分为检测跟踪和无检测跟踪两类, 前者需要检测目标后再进行跟踪; 后者需要在第1帧手动初始化目标, 然后进行跟踪. 在目标跟踪中, 涌现出许多具有良好性能的算法, 如SSD[2]、R-CNN[3-4]以及YOLO系列[5-7], 其中YOLOv3[7]算法在检测跟踪中体现出较强的优势.
由于深度学习的发展, 卷积神经网络模型逐渐替代了传统手工设计的特征, 提供了一种端到端的处理方法, 精度也大幅提高. 但CNN模型在不断提高精度的同时, 其网络深度和尺寸也在成倍增长, 需要GPU来进行加速, 使得基于深度学习的跟踪算法无法直接应用于移动设备, 导致难以符合实时性要求. 因此降低算法复杂度、提高实时性、简化和加速模型便成为亟待解决的问题. 文献[8-10]使用剪枝方法对神经网络进行网络压缩. 文献[11]提出从零开始训练低秩约束卷积神经网络模型的方法, 不仅速度得到提升, 而且在一些情况下模型性能也有所提高. 目前, 深度网络模型压缩方法分为两个方向: 一是对已经训练好的深度网络模型进行压缩得到小型化模型; 二是直接设计小型化模型进行训练, 如SqueezeNet[12]、ShuffleNet[13]、MobileNet[14]等.
在多目标跟踪方面, Zhang等[15]提出一种新型检测跟踪方法, 即将检测与轨迹联系起来, 形成长轨迹. Mahmoudi等[16]使用卷积神经网络代替手工标注进行特征提取, 以改善算法精度, 并提出一种新的2D在线环境分组方法, 具有较高的准确率和实时性. Xiang等[17]设计了一个卷积神经网络提取针对人的重识别, 并使用长期短期记忆网络(long short-term memory, LSTM)提取运动信息来编码目标的状态; 此外, 还设计了基于递归神经网络的贝叶斯过滤模块, 并将LSTM网络的隐藏状态作为输入, 执行递归预测和更新目标状态. 而Deep-SORT[18]多目标跟踪算法则在SORT[19]算法的基础上, 提取深度表观特征,使跟踪效果有了明显的提升.
本文针对算法的实时性问题, 结合深度学习目标检测、深度网络模型压缩以及多目标跟踪算法, 提出基于MobileNet的多目标跟踪算法, 在保证精度的前提下, 有效改善深度网络模型庞大以及计算复杂的问题, 提高了算法的执行速度.
1 YOLOv3目标检测算法
YOLOv3算法的基本思想是: 将输入图像分割为S×S 个单元格, 每个单元格用于检测中心点落在该网格内的目标, 并预测B 个边界框和置信度. 边界框用(x,y,w,h,c) 5个参数表达, 其中(x,y) 为目标中心相对于单元格左上角的相对坐标, 而w 和h 则分别是目标与整张图像的宽和高之比. 单元格还预测C 个类别的各类概率值. 因此, 每个单元格共预测B×(5+C) 个值. YOLOv3借鉴ResNet的理念, 采用YOLOv2的Darknet-19, 并创建一个新的特征提取网络Darknet-53[20]. YOLOv3采用类似FPN的上采样和特征融合机制, 使用不同的特征尺度进行预测. 考虑到其对小目标检测的良好效果, 本文采用该算法进行目标检测.
2 基于MobileNet的多目标跟踪算法
利用MobileNet将标准卷积分解为深度卷积和逐点卷积以减少参数量的特点, 替换YOLOv3目标检测算法的主干网络框架, 并保留多尺度预测, 形成基于MobileNet的目标检测算法, 再进一步结合Deep-SORT算法进行多目标跟踪.
2.1
MobileNet算法
MobileNet是Google为移动端和嵌入式设备提出的高效模型. 使用深度可分离卷积构建深度神经网络,并通过两个超参数, 从通道数量和特征图大小两个方面减少计算量. 分解过程如图 1所示.
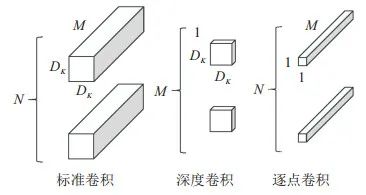
图 1 深度可分离卷积分解过程
假设输入的特征映射F尺寸为(DF,DF,M) , 采用的标准卷积K 为(DK,DK,M,N) , 则输出的映射G 尺寸为(DF,DF,N) . M 为输入通道数, N 为输出通道数, 对应的计算量为
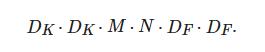
(1)
将标准卷积分解为深度卷积和逐点卷积, 深度卷积起滤波作用, 尺寸大小为(DK,DK,1,M) , 输出特征映射尺寸为(DF,DF,M) ; 逐点卷积用于通道转换, 尺寸大小为(1,1,M,N), 输出映射尺寸为(DF,DF,N) . 两者对应的计算量为
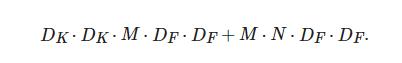
(2)
相比于标准卷积, 深度可分离卷积计算量减少, 即
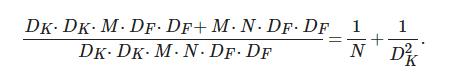
(3)
此外, MobileNet还引入了宽度乘子α 和分辨率乘子ρ 两个超参数, 分别用于改变通道数和特征图分辨率, 便于控制模型大小, 降低参数量.
2.2
基于MobileNet的目标检测模型
MobileNet网络基于深度可分离卷积, 除全连接层外, 所有层后跟有BatchNorm和ReLU, 最后使用softmax进行分类. MobileNet将深度卷积和逐点卷积计为单独的层, 共有28层.
针对实时性问题, 本文结合卷积神经网络模型压缩方法, 选用MobileNet与YOLOv3检测模型相结合, 用前者代替后者的网络框架, 同时保留YOLOv3的多尺度预测, 最终得到轻量级的检测模型.
YOLOv3中包括13×13、26×26和52×52三个尺度, 在MobileNet网络中找到对应13×13×1024、26×26×512和52×52×256的部分, 使用YOLOv3多尺度预测的方法进行融合, 替换后的网络结构如图 2所示.
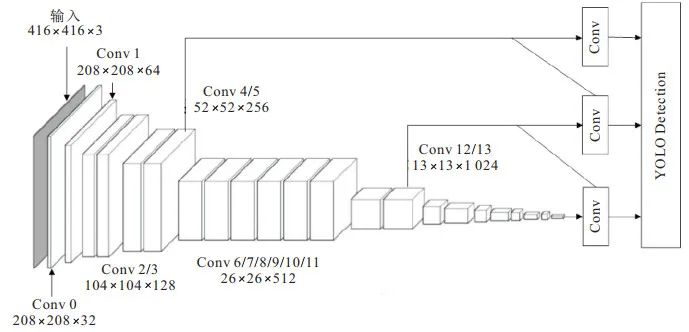
图 2 YOLOv3-MobileNet框架
2.3
多目标跟踪
由于Deep-SORT算法加入了深度表观特征, 并具有较高的准确度和实时性, 本文将基于MobileNet的目标检测算法与Deep-SORT相结合进行多目标跟踪, 主要分为以下部分:
1、目标检测. 首先对输入的视频进行目标检测, 得到目标的边框及特征信息, 并根据置信度和非极大值抑制进行边框过滤.
2、轨迹处理和状态估计. 运动状态估计中使用8个参数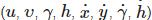 进行运动状态的描述, 其中(u,υ)为边框的中心坐标, γ为长宽比, h为高度, 这4个参数来源于目标检测部分, 其余4个参数表示对应图像坐标系中的速度信息.使用卡尔曼滤波器对运动状态进行预测.
进行运动状态的描述, 其中(u,υ)为边框的中心坐标, γ为长宽比, h为高度, 这4个参数来源于目标检测部分, 其余4个参数表示对应图像坐标系中的速度信息.使用卡尔曼滤波器对运动状态进行预测.
3、对跟踪器参数和特征集进行更新, 判断有无目标消失或者有无新目标出现. 对每个目标, 记录其上次检测结果和跟踪结果匹配后的帧数ak, 只要检测结果与跟踪结果正确关联, 就将该参数置为0. 如果ak超过了设置的最大阈值Amax, 则结束对该目标的跟踪.
4、检测结果与跟踪预测结果匹配. 区分已确认和未确认状态的跟踪器, 对已确认状态的跟踪器进行匹配指派. 其中指派问题使用了匈牙利算法, 并同时考虑运动信息的关联和目标外观信息的关联.
运动信息关联: 使用卡尔曼滤波器预测状态和新测量之间的马氏距离, 以此表达运动信息, 有
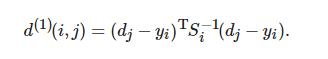
(4)
式(4)表示第j个检测结果与第ii条轨迹之间的运动匹配度. 其中: Si为卡尔曼滤波器当前时刻观测空间的协方差矩阵, yi为当前时刻的预测观测量, dj为第j个检测的状态(u,υ,γ,). 马氏距离通过测量远离平均轨道位置的标准偏差考虑状态估计的不确定性, 通过逆卡方分布的0.95分位点作为阈值t(1), 指标函数定义如下:
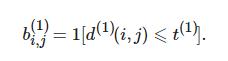
(5)
目标外观信息关联: 由于相机运动会使马氏距离度量方法失效, 引入第2种关联方法, 对每个跟踪目标构建一个库, 存储每个跟踪目标成功关联的最近100帧特征向量, 则第i个跟踪器与当前帧第j个检测结果之间的表观匹配度为
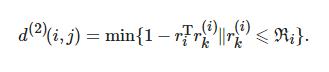
(6)
指标函数表示为
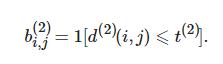
(7)
采用上述两种度量的线性加权作为最终度量, 有
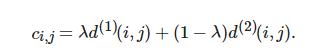
(8)
只有当ci,j位于两种度量阈值的交集内时, 才认为实现了正确的关联. 当指派完成后, 分类出未匹配的检测和跟踪器.
5) 对未确认状态的跟踪器、未匹配的跟踪器和未匹配的检测进行IOU匹配, 再次使用匈牙利算法进行指派.
6) 对于匹配的跟踪器进行参数更新, 删除再次未匹配的跟踪器, 未匹配的检测初始化为新目标.
算法整体流程如图 3所示.
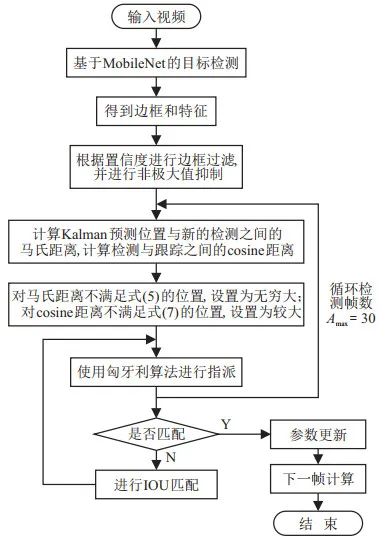
图 3 多目标跟踪算法流程
3 实验结果
本文算法使用keras实现, 并利用PASCAL VOC 2007和VOC 2012数据集进行训练. 作为视觉分类检测的基准测试, PASCAL VOC数据集包含20类物体, 如人、动物、交通工具、家具等, 每张图片均有标注.本文使用VOC 2007 trainval数据集和VOC 2012 trainval数据集、共16 551张图片进行训练, 训练环境为Google Colab云平台. 所使用的操作系统为Ubuntu18.04.1, GPU为Tesla K80. 其他测试均在Windows 8.1下进行, CPU为Intel(R) Core(TM) i5-5200U, 无GPU.
在目标检测评价中, 常用的评价指标为mAP(mean average precision), 表示对目标类的AP值取平均, 本文采用mAP、单张图片检测时间及模型大小等指标对目标检测模型进行评估. 对于多目标跟踪算法, 由于很难使用单一评分评估多目标跟踪性能, 采用MOT Challenge评价标准.
3.1
目标检测算法对比实验
表 1为YOLOv3目标检测算法、基于MobileNet的目标检测算法和其他检测算法实验对比结果.
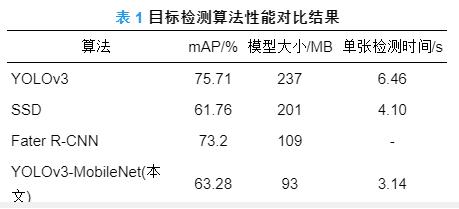
表 1 目标检测算法性能对比结果
本文选取比较流行的单阶段检测算法和两阶段检测算法进行对比实验. 由表 1可见, 基于MobileNet的目标检测算法模型是YOLOv3算法模型的1/3, 并且相比SSD和Fater R-CNN, 模型最小; 单张图片检测时间相比YOLOv3模型提高了2倍; 在精度方面, 本文检测算法相比YOLOv3模型下降约12.4 %, 但相比SSD提高1.5 %. 总体而言, 虽然本文检测算法在检测精度上有所降低, 但可以满足检测跟踪的实际需求, 并且在模型大小和单张检测时间上具有优势. 精度降低的原因是由于YOLOv3的网络结构中使用了残差网络, 并且网络层数更深, 而MobileNet网络结构仅使用深度可分离卷积, 没有使用残差结构, 在网络深度方面也比YOLOv3更浅, 因此造成本文检测算法在mAP值上与YOLOv3差距较大. 虽然本文检测算法在一定程度上牺牲了精度, 但实现了模型的小型化和速度上的提升.
3.2
多目标跟踪算法对比实验
在MOT基准数据库提供的序列集上评估跟踪性能, 以MOT Challenge标准对多目标跟踪算法进行评价, 具体评价指标如表 2所示, 各指标含义如下:
表 2 评价指标对比
MOTA(↑): 多目标跟踪准确度;
MOTP(↑): 多目标跟踪精度;
MT(↑): 目标跟踪轨迹占真实长度80 %以上的轨迹数目;
ML(↓): 目标跟踪丢失轨迹占真实长度至多20 %的轨迹数目;
IDs(↓): 目标ID发生变化的次数;
FP(↓): 误报总数;
FN(↓): 未命中目标的总数;
FPS(↑): 帧频率.
对于带有(↑)的评价指标, 分数越高表示效果越好; 对于带有(↓)的评价指标, 结果相反.
由表 2可见: 本文算法的MOTP值与YOLOv3-Deep-SORT算法相差不大, 但均高于表中其他算法; 被跟踪的轨迹比例(MT)相比YOLOv3-Deep-SORT算法有所上升, 跟丢轨迹占比(ML)有所下降, 均优于TC_ODAL和RMOT算法; ID变换次数低于表中前4个算法(即TC_ODAL、RMOT、SORT、MDP), 但相比YOLOv3-Deep-SORT算法有所上升; 帧频率提高为该算法的3倍, 检测跟踪时间提高显著. 本文算法虽然在跟踪准确度、ID变换次数和误报总数上不及YOLOv3-Deep-SORT算法, 但其他跟踪指标均优于该算法, 并且本文算法相比于TC_ODAL、RMOT和SORT等算法优势明显. 为进一步表现本文算法的优越性, 以ID标号为3的目标为例, 给出如图 4所示的部分跟踪结果, 且跟踪框上带有数字ID标识. 由图 4可见, 该算法在第200帧、260帧、320帧均能连续跟踪, 跟踪效果良好.

图 4 跟踪结果
3.3
无人机人流监控实验
以某城市交通路口人流监控为例, 将本文算法应用于无人机, 利用其高空独特视角, 对十字路口行人进行统计, 实时监测人流密度以及人流密度变化情况, 以配合地面警力巡查, 对各类警情及交通情况进行预警, 辅助警力调度, 实现对城市环境下的安全监控. 此类监管系统的关键是要具有良好的实时性, 因此降低网络参数量, 提高实时性显得十分重要.
本文以无人机数据集进行实验, 选取第76、133和182帧, 如图 5所示. 由图 5可见, 本文算法可有效检测和跟踪大部分行人, 且实时性与之前检测跟踪实验结果具有相同数量级, 但对于相互遮挡和全身信息不全的行人检测跟踪效果相对较差.

图 5 无人机数据集跟踪结果
4 结论
本文在YOLOv3和Deep-SORT算法的基础上, 针对实时性问题, 使用轻量级网络MobileNet代替原有网络结构对检测模型进行压缩. 实验结果表明, 尽管改进算法由于更浅的网络结构和未使用残差网络等因素导致精度下降, 但实时性提高显著, 实现了精度和速度间的折衷, 达到了快速有效跟踪的目的.

关注我们了解更多信息










