
作者:京东科技 孙亮
微电平台
微电平台是集电销、企业微信等于一体的综合智能SCRM SAAS化系统,涵盖多渠道管理、全客户生命周期管理、私域营销运营等主要功能,目前已经有60+京东各业务线入驻,专注于为业务提供职场外包式的一站式客户管理及一体化私域运营服务。
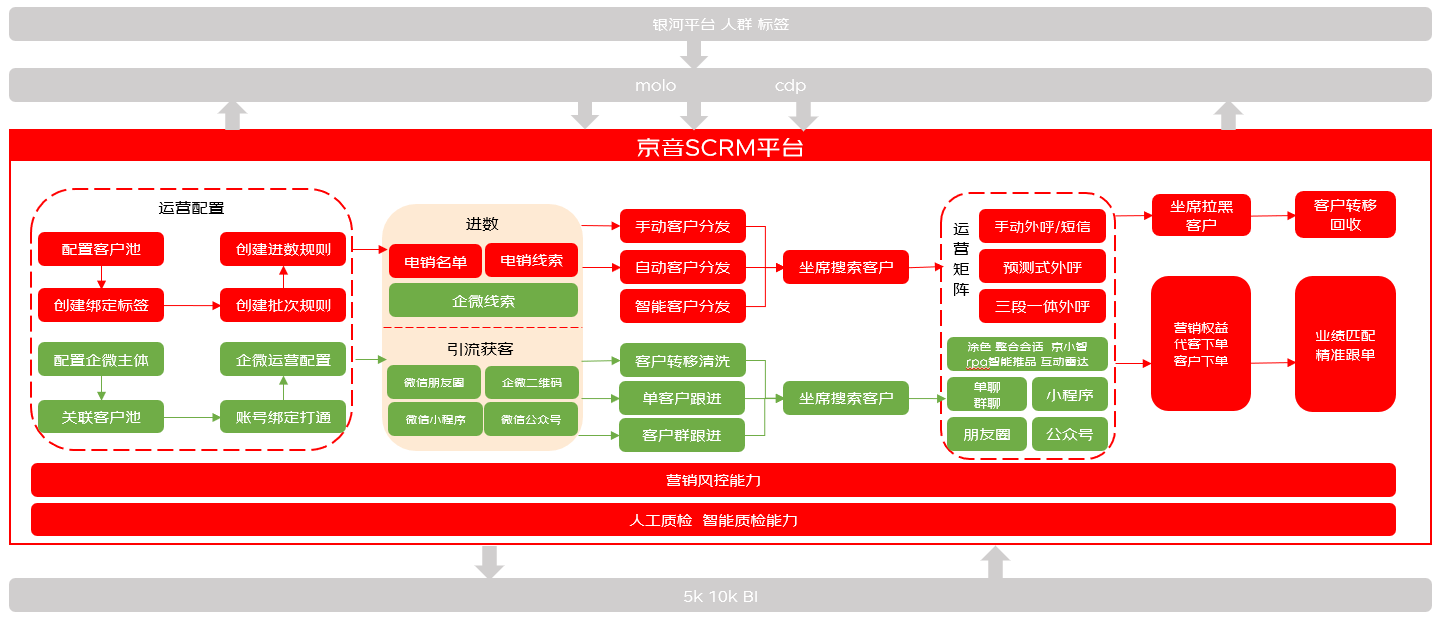
导读
本文介绍电销系统在遇到【客户名单离线打标】问题时,从排查、反复验证到最终解决问题并额外提升50%吞吐的过程,适合所有服务端研发同学,提供生产环遇到一些复杂问题时排查思路及解决方案,正确使用京东内部例如sgm、jmq、jsf等工具抓到问题根因并彻底解决,用技术为业务发展保驾护航~
下面开始介绍电销系统实际生产环境遇到的离线拒绝营销打标流程吞吐问题。
案例背景
1、概述
每日凌晨18点会使用80台机器为电销系统上亿客户名单进行拒绝营销打标,平均95万名单/分钟,拒绝营销jsf服务总tps约2万**,****tp99在100110ms,若夜间没有完成标记加工操作,会导致白天职场无法正常作业,并且存在客户骚扰隐患、降低职场运营效率的问题,因外部接口依赖数量较多**打标程序只能凌晨启动和结束。
2、复杂度
面向业务提供千人千面的配置功能,底层基于规则引擎设计实现,调用链路中包含众多外部接口,例如金融刷单标记、风控标记、人群画像标记、商城风控标记、商城实名标记等,包含的维度多、复杂度较高。
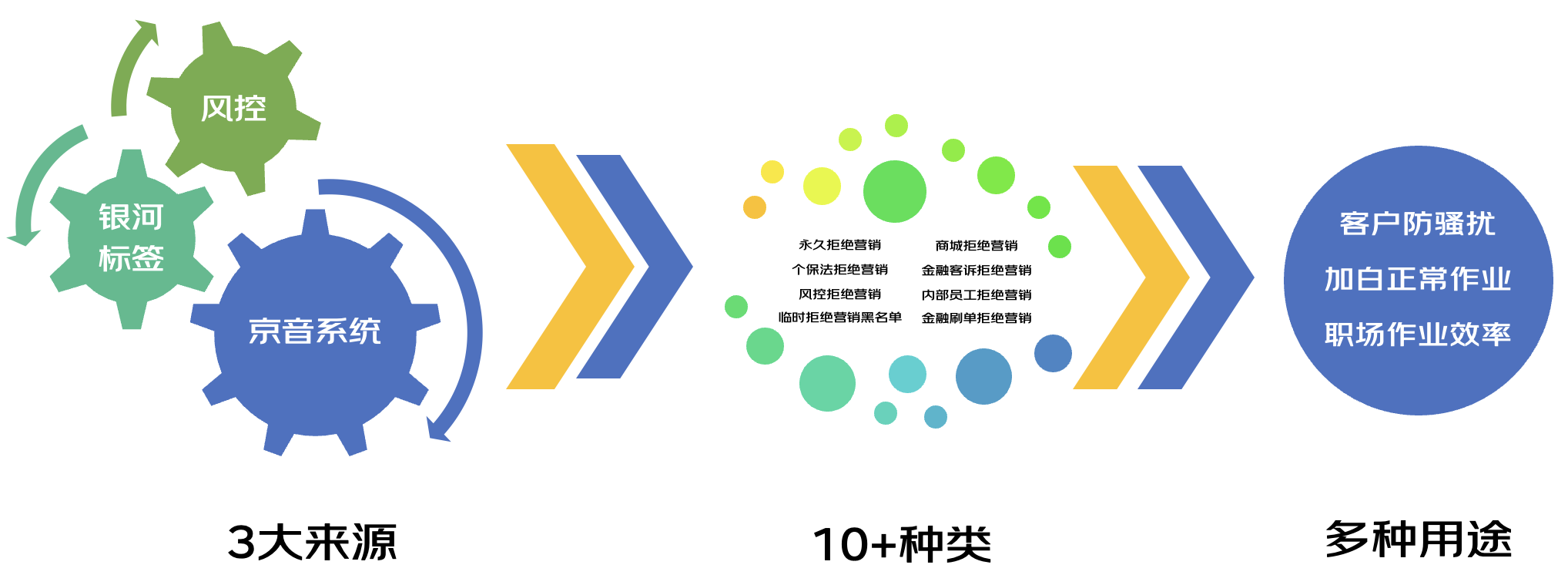
3、问题
2023年2月24日早上通过监控发现拒绝营销打标没有执行完成,表现为jmq消费端tp99过高、进而降低了打标程序吞吐,通过临时扩容、下掉“问题机器**”**(上帝视角:其实是程序导致的问题机器)提高吞吐,加速完成拒绝营销打标。
但,为什么会频繁有机器问题?为什么机器有问题会降低40%吞吐?后续如何避免此类情况?
带着上述问题,下面开启问题根因定位及解决之旅~
抓出幕后黑手
1、为什么几台机器出问题就会导致吞吐急剧下降?
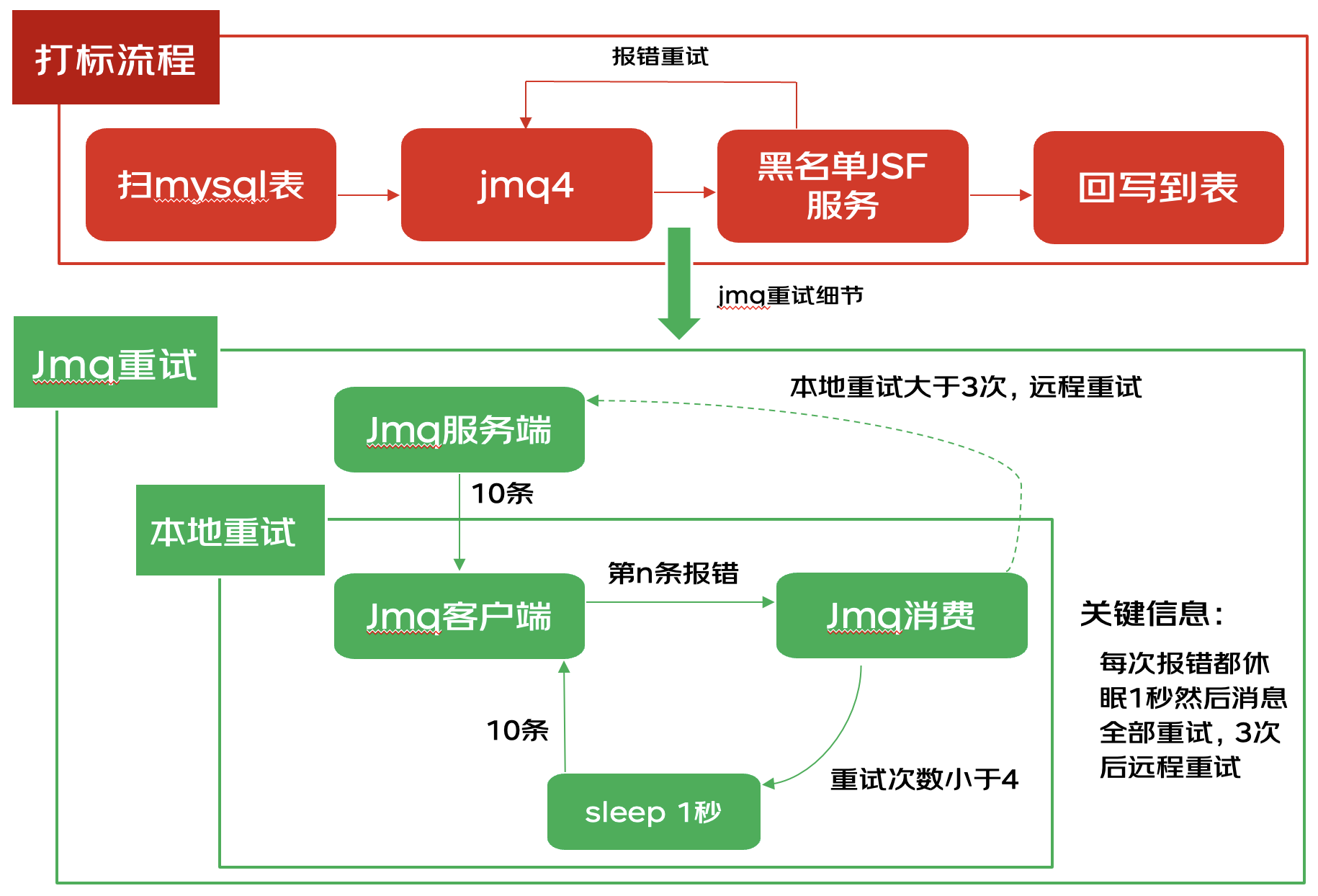
如上图所示,每有一条消息消费报错(在本案例中是打到“问题机器”上),会本地尝试sleep并重新消费拉下来的所有消息(本案例中jmq的batchSize=10),即每次报错产生的总耗时至少会增加一千毫秒,一共80台机器,jsf使用默认负载均衡算法,服务请求打到4台问题机器的概率是5%,jmq一次拉下来10条消息,只要有一条消息命中“问题机器”就会极大降低吞吐。
综上所述,少量机器有问题吞吐就会急剧降低的原因是jsf随机负载均衡算法下每个实例的命中率相同以及报错后jmq consumer重试时默认休眠1秒的机制导致。
解决:当然consumer不报错是完全可以规避问题,那如果保证不了不报错,可以通过:
1)修改jmq的重试次数、重试延迟时间来尽可能的减少影响
<jmq:consumer id="cusAttributionMarkConsumer" transport="jmqTransport">
<jmq:listener topic="${jmq.topic}" listener="jmqListener" retryDelay="10" maxRetryDelay="20" maxRetrys="1"/>
</jmq:consumer>2)修改jsf负载均衡算法
配置样例:
<jsf:consumer loadbalance="shortestresponse"/>原理图:
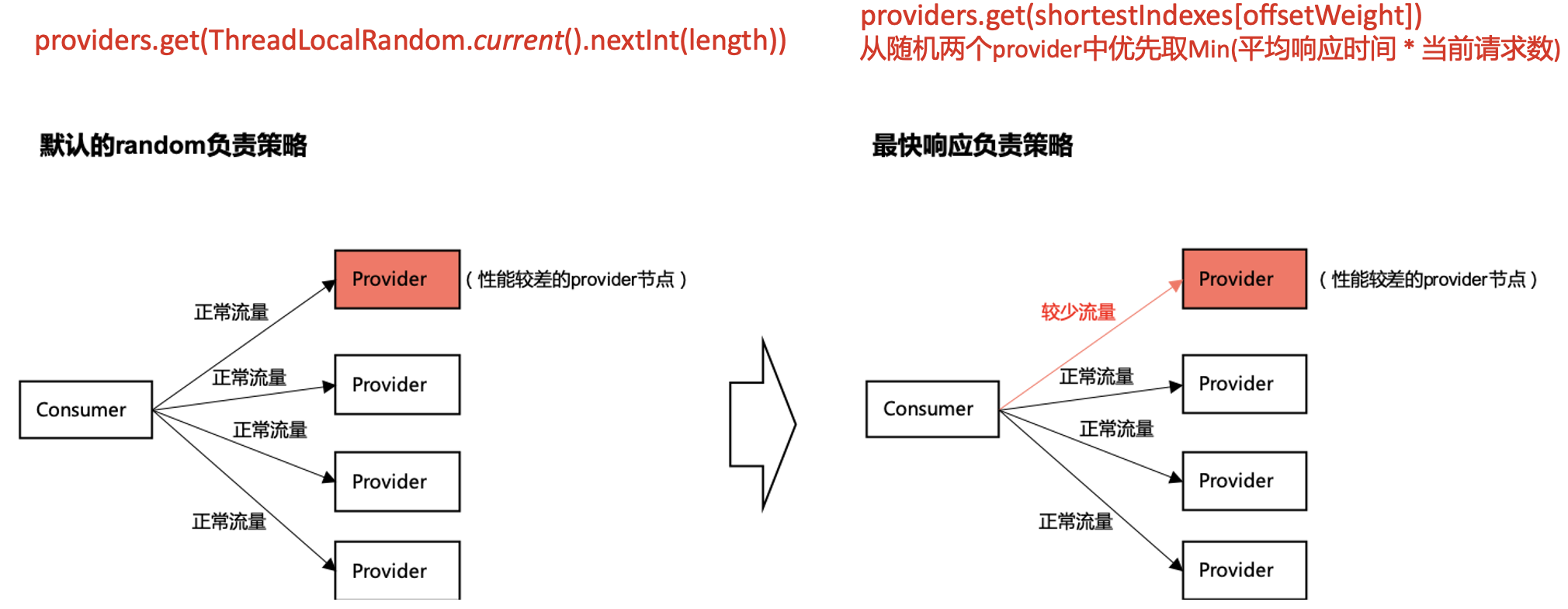
上图中的consumer图是从jsf wiki里摘取,上面的红字是看jsf代码提取的关键信息,总而言之就是:默认的random是完全随机算法,最快响应时间是基于服务请求表现进行负载均衡,所以使用最快响应算法可以很大程度上规避此类问题,类似于熔断的作用(本次解决过程中也使用了jsf的实例熔断、预热能力,具体看jsf wiki,在此不过多介绍)。
2、如何判定是实例问题、找出有问题的实例ip?
通过监控观察,耗时高的现象只存在于4台机器上,第一反应确实是以为机器问题,但结合之前(1月份有过类似现象)的情况,觉得此事必有蹊跷。
下图是第一反应认为是机器问题的日志(对应sgm监控这台机器耗时也是连续高),下掉此类机器确实可以临时解决问题:
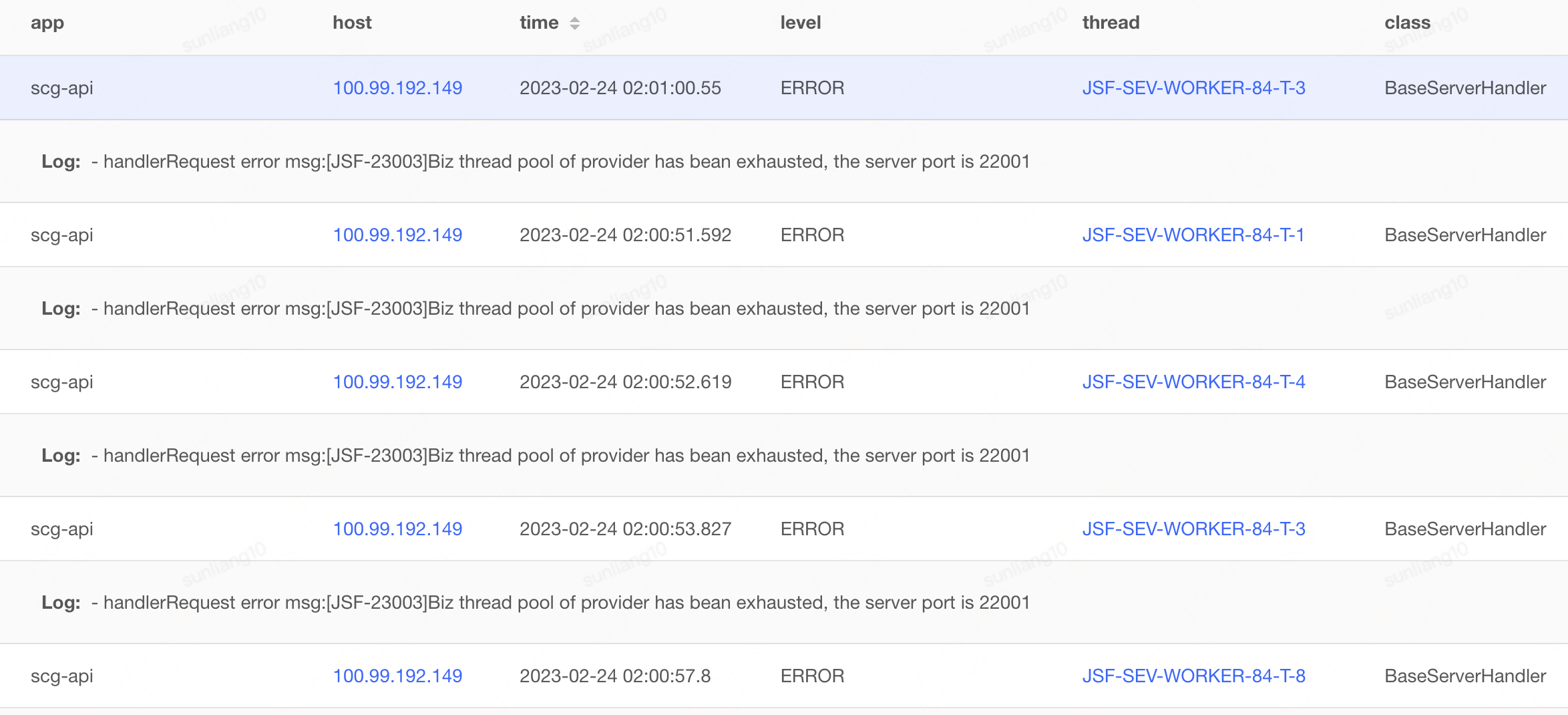
综上所述,当时间段内耗时高或失败的都是某个ip,此时可以判定该ip对应的实例有问题(例如网络、硬件等),如果是大量ip存在类似现象,判定不是机器本身的问题,本案例涉及到的问题不是机器本身问题而是程序导致的现象,继续往下看揭晓答案。
3、是什么导致机器频繁假死、成为故障机器?
通过上述分析可以得知,问题机器报错为jsf线程池打满,机器出问题期间tps几乎为0,期间有请求过来就会报jsf线程池(非业务线程池)打满,此时有两种可能,一是jsf线程池有问题,二是jsf线程池的线程一直被占用着,抱着信任中间件的思路,选择可能性二继续排查。
通过行云进行如下操作:
1)dump内存对象
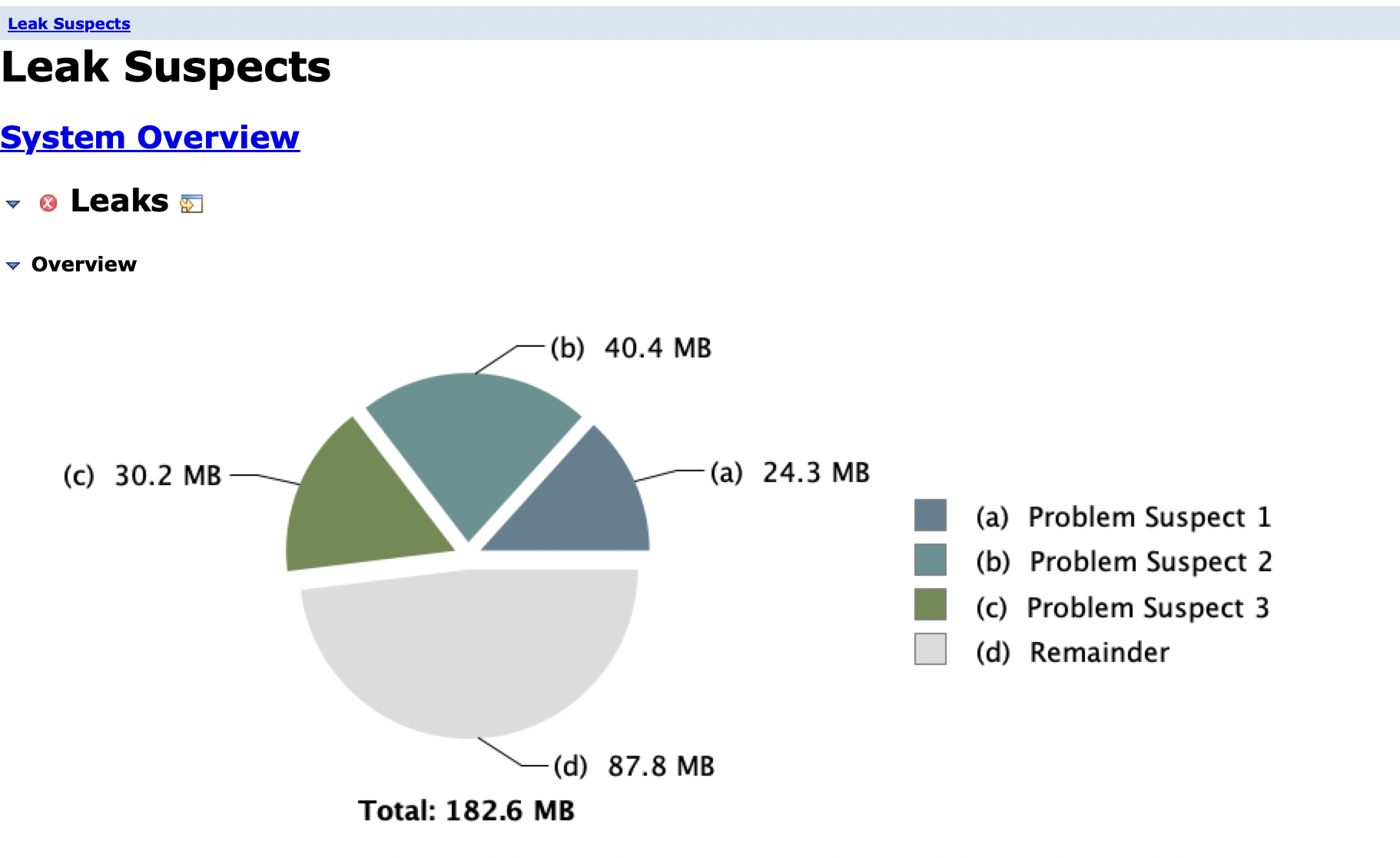
无明显问题,内存占用也不大,符合监控上的少量gc现象,继续排查堆栈
2)jstack堆栈
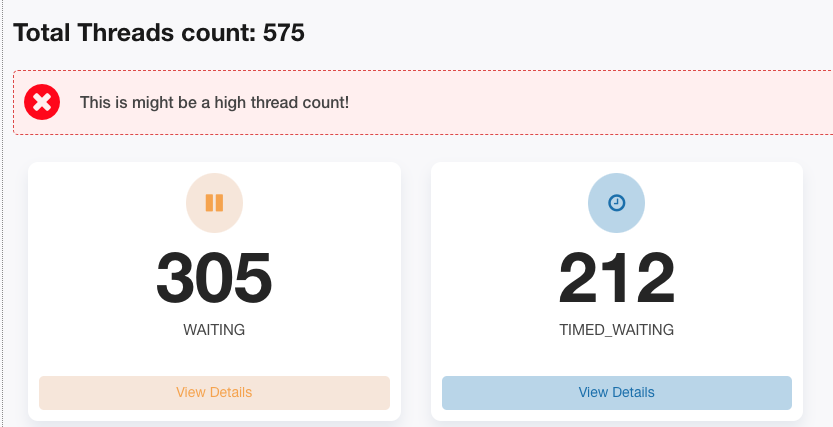
从此来看与问题机器表象一致了,基本得出结论:所有jsf线程都在waiting,所以有流量进来就会报jsf线程池满错误,并且与机器cpu、内存都很低现象相符,继续看详细栈信息,抽取两个比较有代表的jsf线程。
线程编号JSF-BZ-22000-92-T-200:
stackTrace: java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000007280021f8> (a java.util.concurrent.FutureTask) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.FutureTask.awaitDone(FutureTask.java:429) at java.util.concurrent.FutureTask.get(FutureTask.java:191) at com.jd.jr.scg.service.common.crowd.UserCrowdHitResult.isHit(UserCrowdHitResult.java:36) at com.jd.jr.scg.service.impl.BlacklistTempNewServiceImpl.callTimes(BlacklistTempNewServiceImpl.java:409) at com.jd.jr.scg.service.impl.BlacklistTempNewServiceImpl.hit(BlacklistTempNewServiceImpl.java:168)
线程编号JSF-BZ-22000-92-T-199:
stackTrace: java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000007286c9a68> (a java.util.concurrent.FutureTask) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.FutureTask.awaitDone(FutureTask.java:429) at java.util.concurrent.FutureTask.get(FutureTask.java:191) at com.jd.jr.scg.service.biz.BlacklistBiz.isBlacklist(BlacklistBiz.java:337)
推断:线程编号JSF-BZ-22000-92-T-200在UserCrowdHitResult的36行等待,线程编号JSF-BZ-22000-92-T-199在BlacklistBiz的337行等待,查到这,基本能推断出问题原因是线程等待,造成问题的类似代码场景是1)main线程让线程池A去执行一个任务X;2)任务X中又让同一个线程池去执行另一个任务,当第二步获取不到线程时就会一直等,然后第一步又会一直等第二步执行完成,就是造成线程互相等待的假死现象。
小结:查到这基本可以确认问题,但因代码维护人离职以及程序错综复杂,此时为验证结论先修改业务线程池A线程数:50->200(此处是为了验证没有线程等待现象时的吞吐表现),再进行验证,结论是tps会有小范围抖动,但不会出现tps到0或是大幅降低的现象。
单机tps300~500,流量正常了,即未产生线程等待问题时可以正常提供服务,如图:
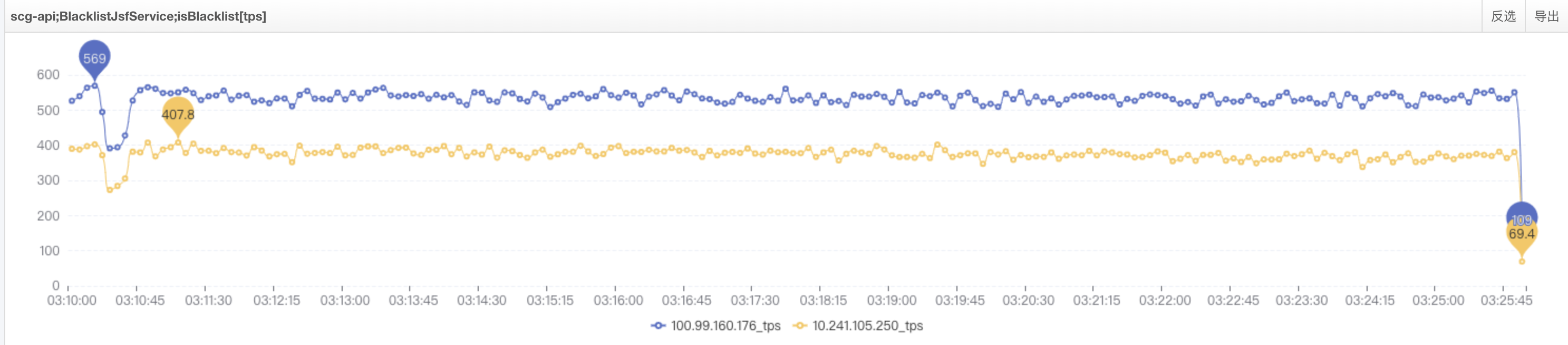
印证推断:通过堆栈定位到具体代码,代码逻辑如下:
BlacklistBiz->【线程池A】blacklistTempNewService.hit blacklistTempNewService.hit->callTimes callTimes->userCrowdServiceClient.isHit->【线程池A】crowdIdServiceRpc.groupFacadeHit
小结:BlacklistBiz作为主线程通过线程池A执行了blacklistTempNewService.hit任务,然后blacklistTempNewService.hit中又使用线程池A执行了crowdIdServiceRpc.groupFacadeHit造成了线程等待、假死现象,与上述推断一致,至此,问题已完成定位。
解决:办法很简单,额外新增一个线程池避免线程池嵌套使用。
4、意外收获,发现一个影响拒绝营销服务性能的问题点
查看堆栈信息时发现存在大量waiting to lock的信息:
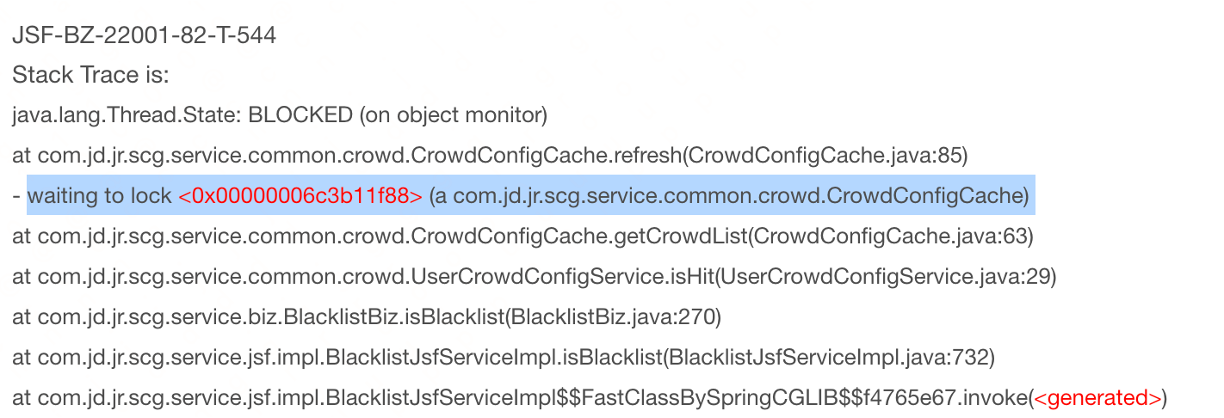
问题:通过上述堆栈进而排查代码发现一个服务链路中的3个方法使用了同一把锁,性能不降低都怪了 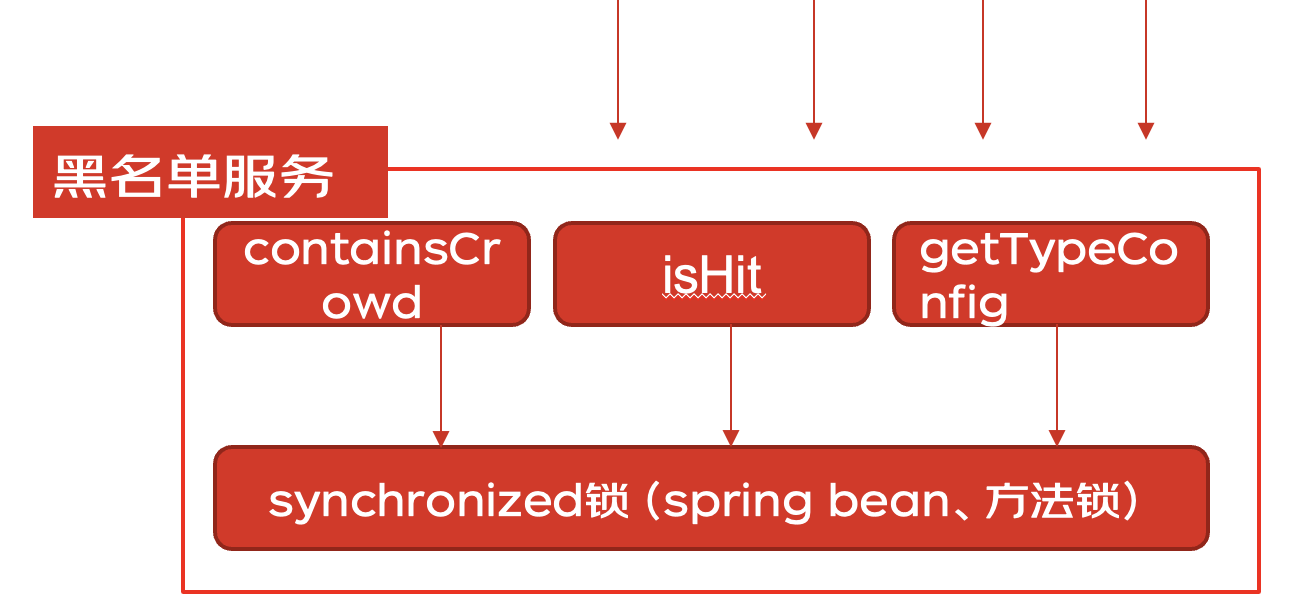 解决:通过引入caffeine本地缓存替换掉原来使用同步锁维护的手写本地缓存。
解决:通过引入caffeine本地缓存替换掉原来使用同步锁维护的手写本地缓存。
5、额外收获,你知道jsf线程池满的时候报RpcException客户端不会进行重试吗?
这个让我挺意外的,之前看jsf代码以及和jsf架构师交流得到的信息是:所有RpcException都会进行重试,重试的时候通过负载均衡算法重新找provider进行调用,但在实际验证过程中发现若服务端报:handlerRequest error msg:[JSF-23003]Biz thread pool of provider has bean exhausted, the server port is 22001,客户端不会发起重试,此结论最终与jsf架构师达成一致,所以此类场景想要重试,需要在客户端程序中想办法,实现比较简单,这里不贴样例了。
事件回顾
 解决问题后对以前的现象和类似问题做了进一步挖掘,梳理出了如上图的整个链路(问题代码同学早已不在、大可忽略问题人,此处从上帝视角复盘整个事件),通过2月24号的问题,不但彻底解决了问题,还对影响性能的因素做了优化,最终效果有:
解决问题后对以前的现象和类似问题做了进一步挖掘,梳理出了如上图的整个链路(问题代码同学早已不在、大可忽略问题人,此处从上帝视角复盘整个事件),通过2月24号的问题,不但彻底解决了问题,还对影响性能的因素做了优化,最终效果有:
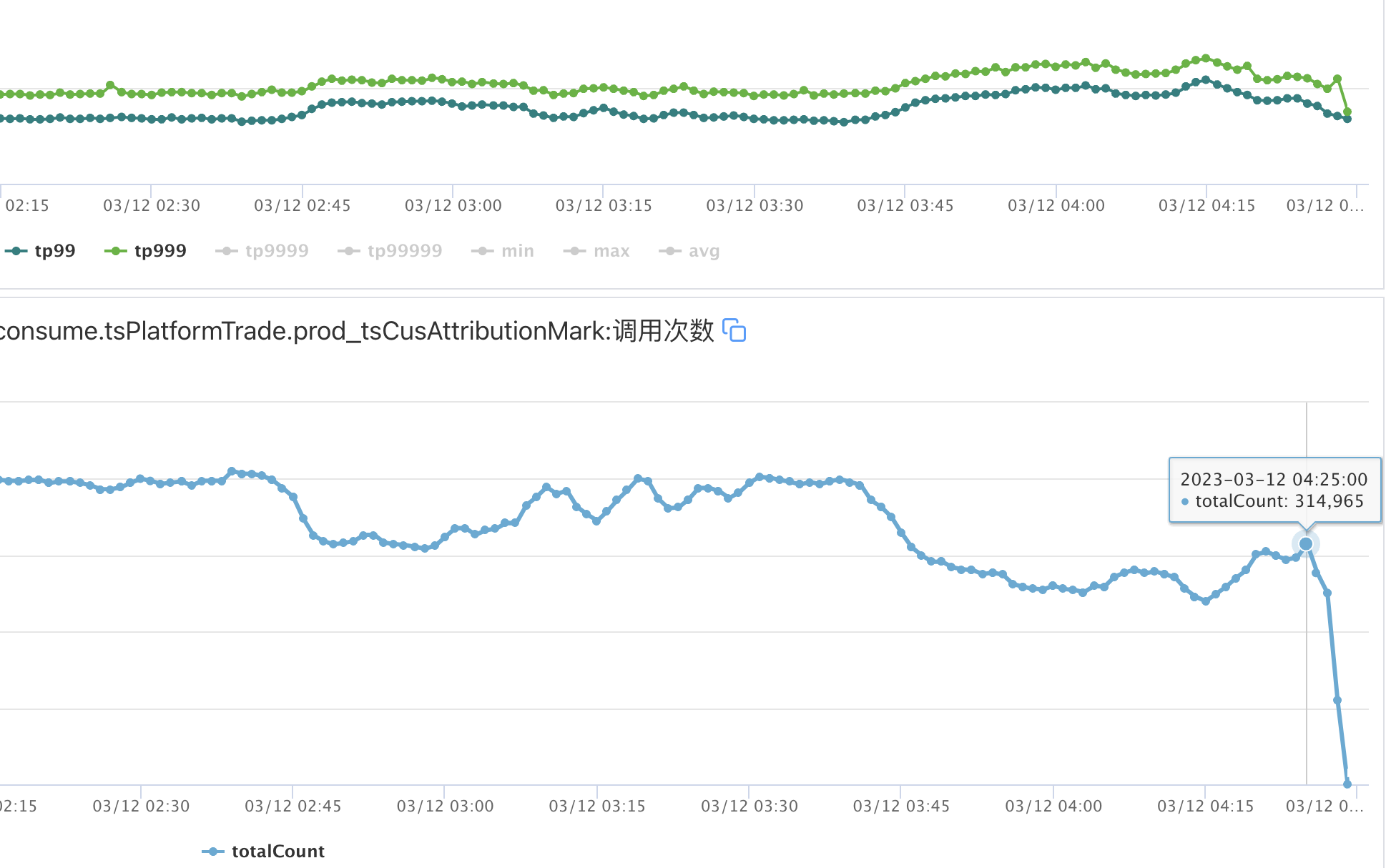
1、解决拒绝营销jsf服务线程等待安全隐患、去掉同步锁提升吞吐,tps从2万提升至3万的情况下,tp99从100ms降低至65ms;
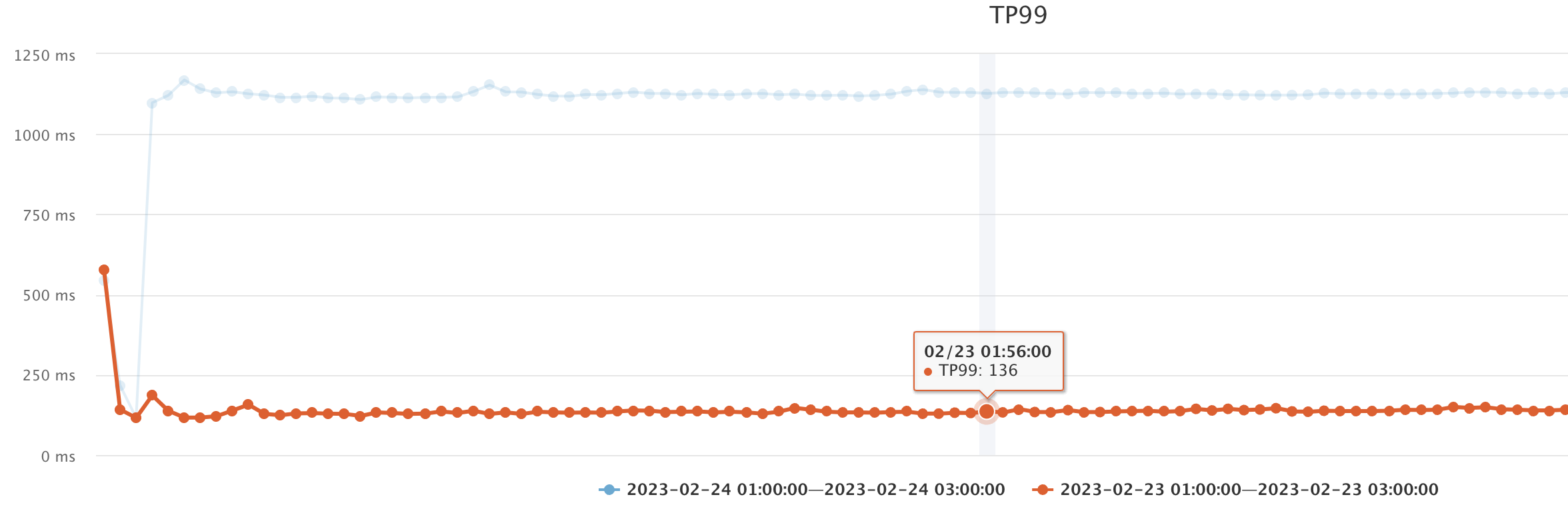
2、jmq重试等待及延迟时间调优,规避重试时吞吐大幅降低:tp99从1100ms降低至300ms;
3、jsf负载均衡算法调优,规避机器故障时仍然大量请求打到机器上,效果是服务相对稳定;
最终从8点多执行完提前至5点前完成,整体时间缩减了57%,并且即使机器出现“问题”也不会大幅降低整体吞吐,收益比较明显。
优化后的运行图如下:
写在最后
微电平台虽说不在黄金链路,但场景复杂度(业务复杂度、rpa等机器人用户复杂度)以及流量量级使我们经常面临各种挑战,好在我们都解决了,这里共勉一句话:“在前进的路上总会有各种意想不到的情况,但是,都会拨云见日”。
后面的路,继续努力奔跑,祝每位努力的研发同学都能成长为靠谱的架构师,加油~



