
一、背景
在日常项目中,经常能遇到多维度、多指标自由组合分析的OLAP系统建设场景,这类需求往往具有分析关系复杂、开发周期长和数据量大等特点,需要研发投入比较大的精力进行建设。
针对OLAP的场景,目前开源界大部分项目都是针对存储层的实现,如ClickHouse、Doris等OLAP数据库。很少针对应用层进行统一建模实现的。据调研,Mondrian是一个面向应用的OLAP引擎,但其面向OLAP特有的MDX语言使用起来非常复杂,需要投入较大的学习成本,不利于日常项目快速开发。因此,本文旨在通过统一的OLAP建模实现通用的OLAP诊断框架,目的是通过配置化的方式快速实现新的分析需求,节约研发成本,缩短交付周期、提升研发效率。
二、架构设计
2.1 总体架构
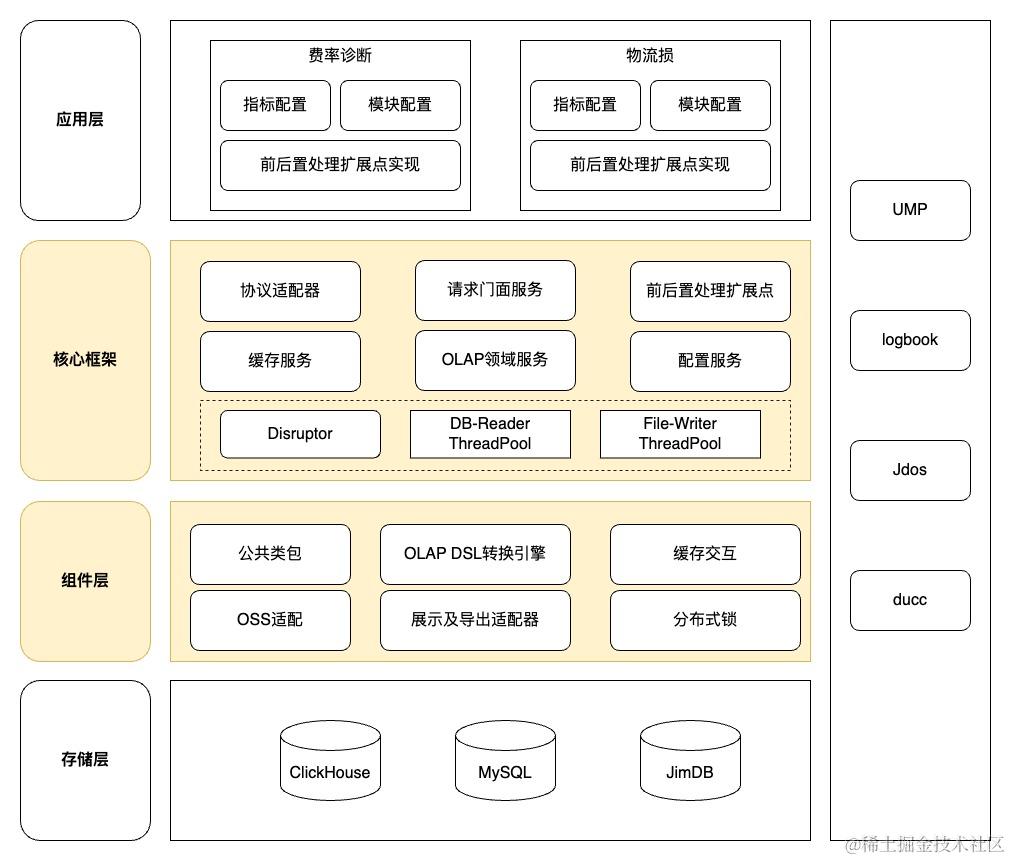
上图着色部分是框架部分,应用层通过集成本框架,只需要编写配置文件以及针对特殊场景下实现前后置扩展点,就能够快速构建一个OLAP分析类的应用。另外、考虑到底层OLAP存储一般采用列式存储模式,在同前端指定交互协议时,建议摒弃在OLTP领域常用的大对象模式,而是采用按需按列查询的模式进行传参和返回,最大化利用列式存储的特性,提升查询性能。
2.2 容器及组件视角
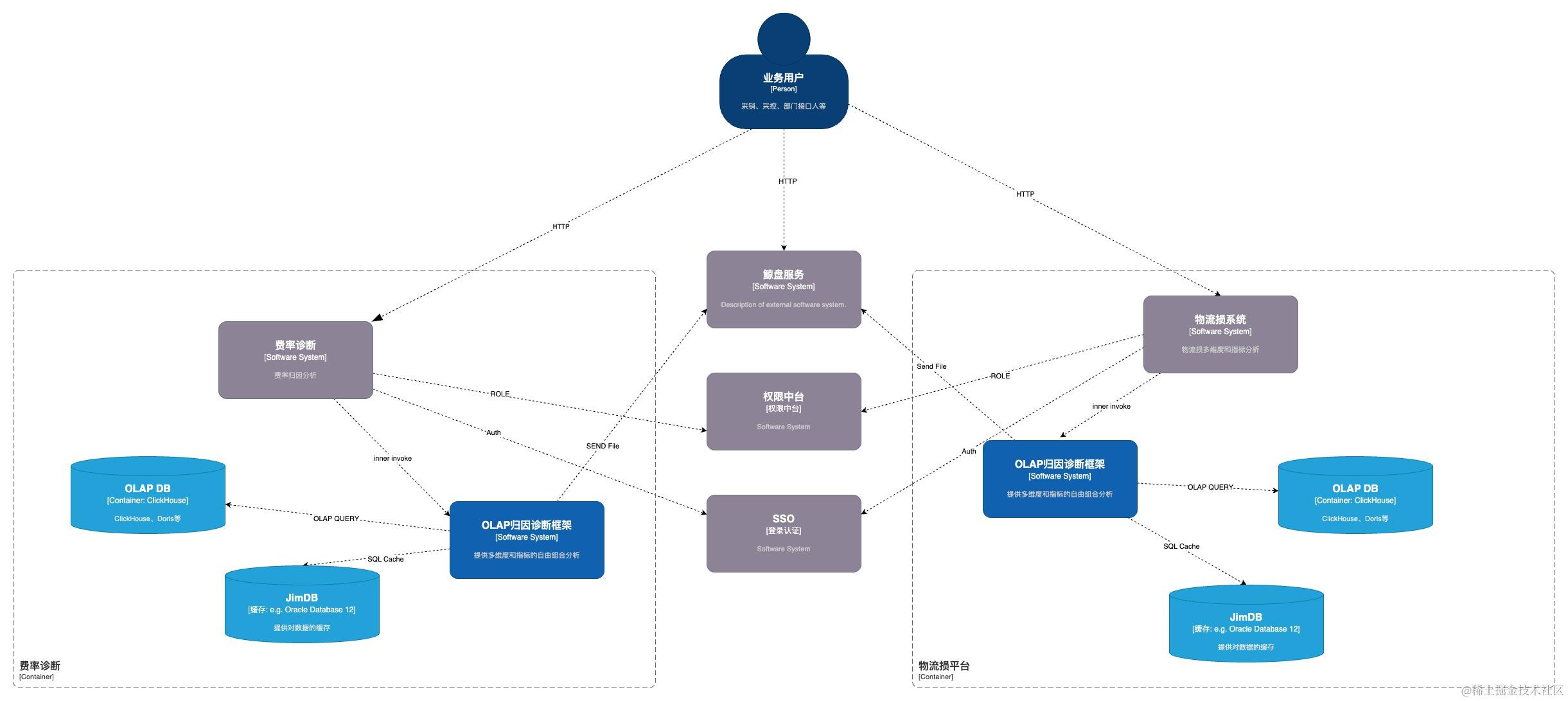
2.2.1 容器视角
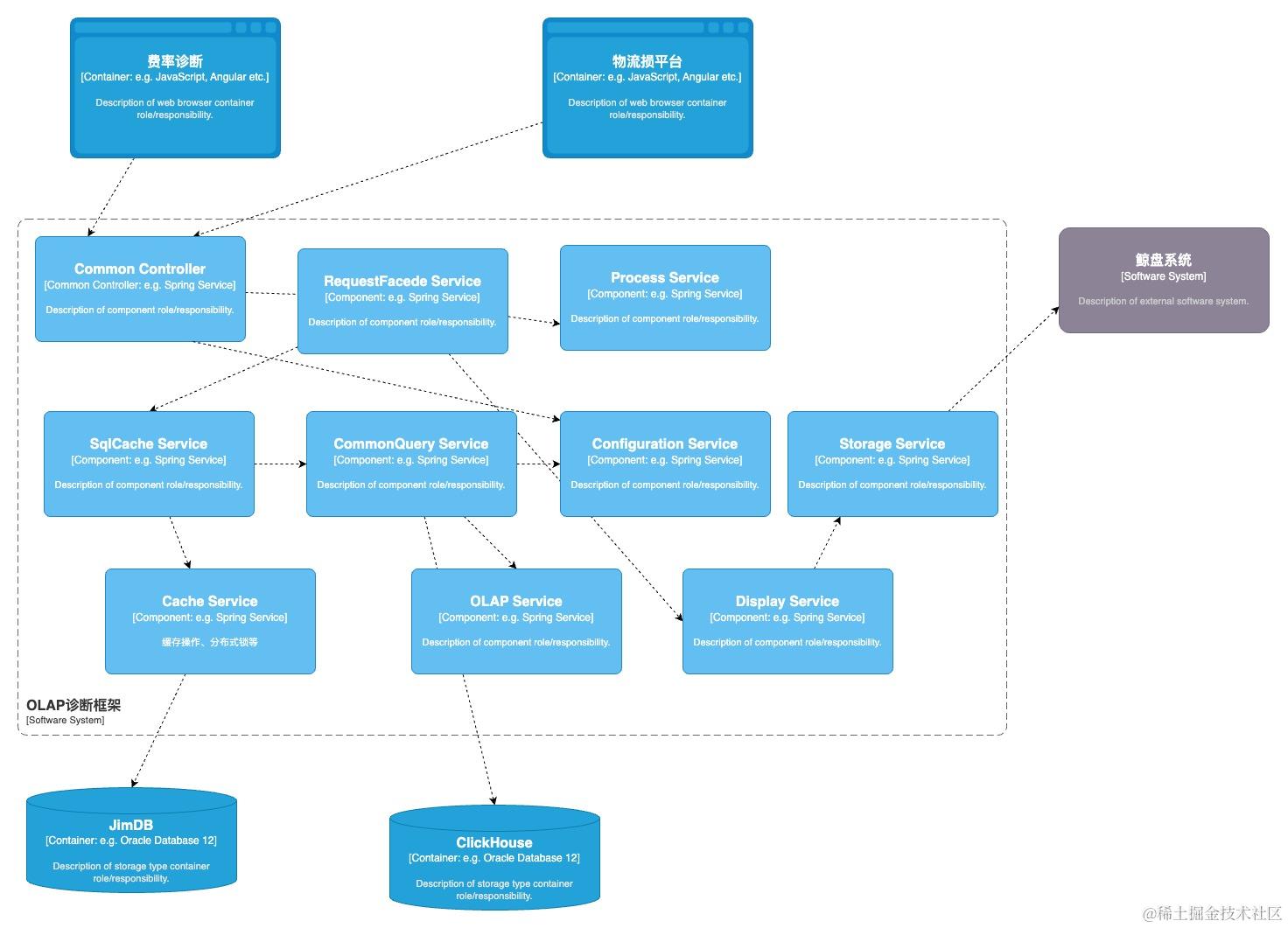
2.2.2 组件视角
三、详细设计
3.1 Runtime
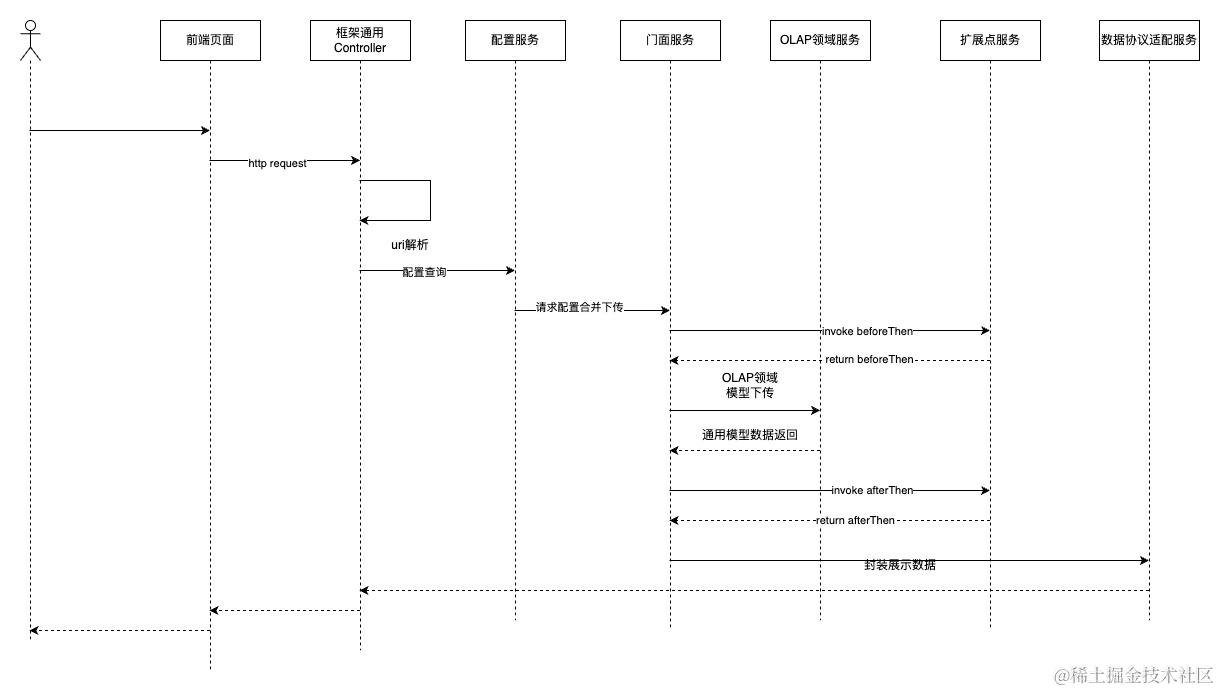
框架会组合前端请求参数和后端配置项,通过门面服务区分请求类型(表格、图表和文件导出),将最终的OLAP领域模型下传到OLAP领域服务,由OLAP领域服务将领域模型翻译为底层OLAP数据库可以执行的SQL,并将结果统一按照特定格式返回,通过数据协议适配服务,根据请求的类型返回数据给前端。
3.2 核心领域模型
3.2.1 何为OLAP
联机分析处理(英语:Online analytical processing),简称OLAP,是计算机技术中快速解决多维分析问题(MDA)的一种方法。OLAP由四个基本的分析操作组成:上卷(roll-up)、钻取(drill-down)、切片(slicing)和切块(dicing)。
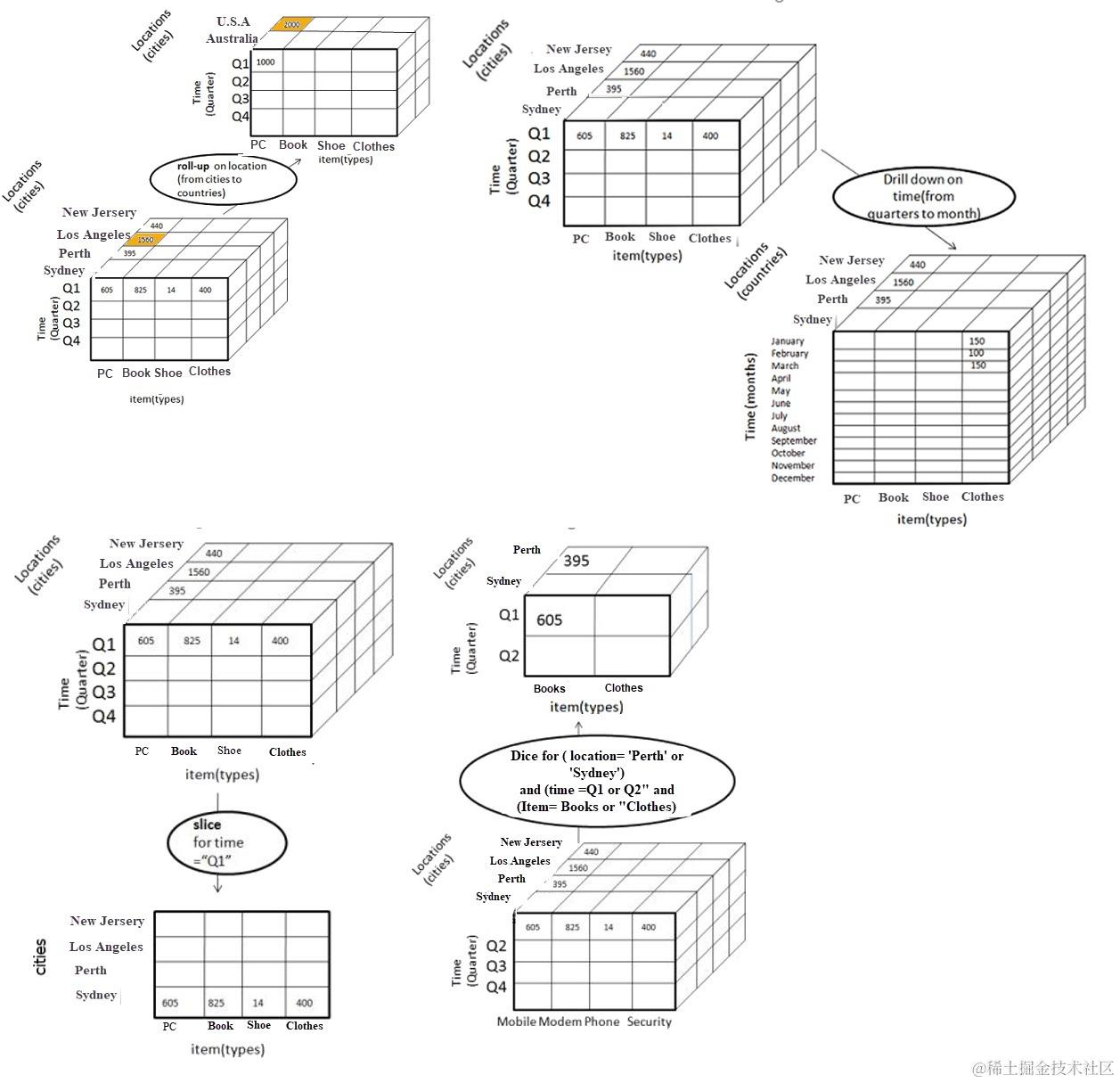
3.2.2 聚合SQL的OLAP抽象
上述OLAP的操作,均可通过聚合查询的SQL实现对应。一个标准的聚合查询SQL包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY以及分页的LIMIT OFFSET。通过对聚合SQL的抽象,我们可以将一个普通的聚合查询提取出维度、指标、模型、一级过滤条件、二级过滤条件、分页和排序关键实体,如下图是一个普通的聚合SQL同关键实体的映射关系:

因此,聚合查询可以抽象如下:
SELECT 维度,
指标
FROM 模型
WHERE 一级过滤器
GROUP BY 维度
HAVING 二级过滤器
ORDER BY 排序
LIMIT 排序3.2.3 领域建模
经过上面的抽象,框架方面,可以划分为核心OLAP域以及面向前端及配置的交互域,并提取出领域模型:
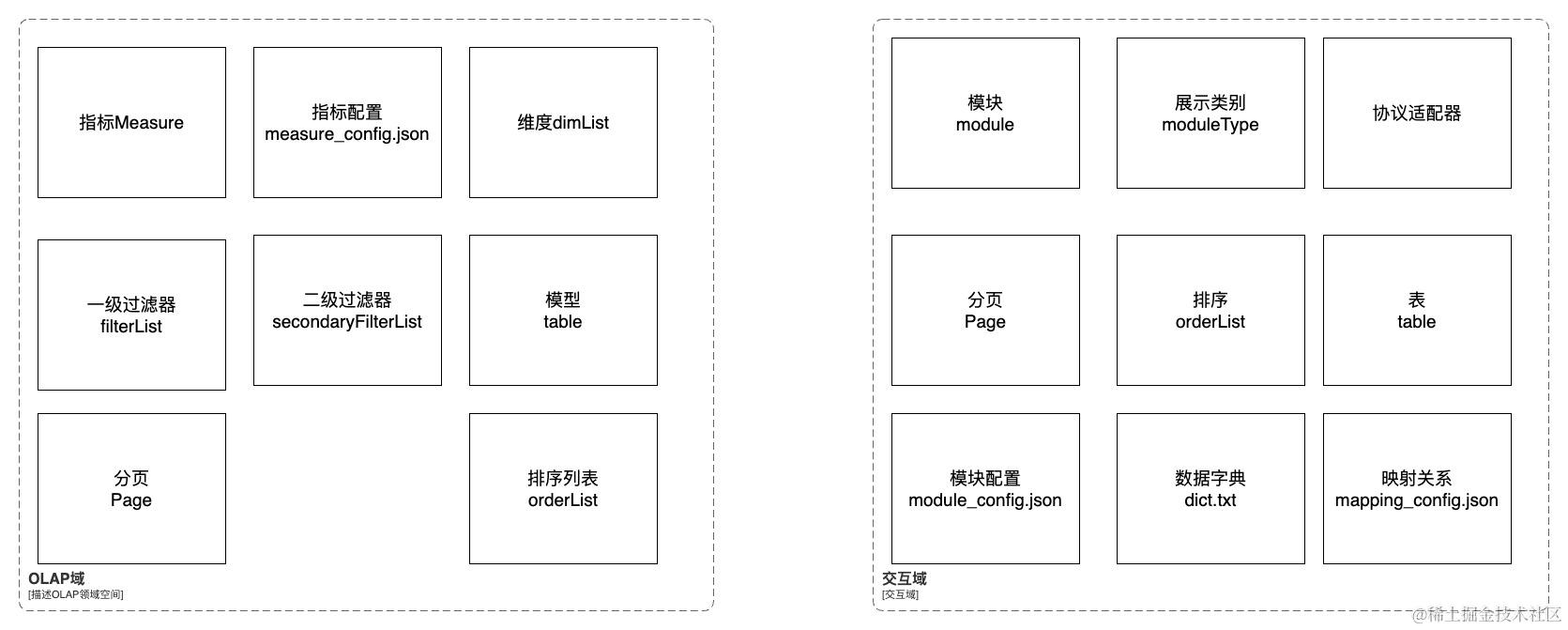

3.3 元数据配置
框架核心提供可配置的元数据,核心包括两类:一类是将所有的计算指标的指标配置文件,另一类是uri和模块映射关系文件。
3.3.1 指标元数据
{
"cbj_amount": {
"expression": "sum(cbj_amount)",
"name": "cbj_amount",
"desc": "损失分布-仓报价金额"
},
"sale_qtty": {
"expression": "sum(sale_qtty)",
"name": "sale_qtty",
"desc": "销量"
},
"loss_amount": {
"expression": "sum(loss_amount)",
"name": "loss_amount",
"desc": "损额"
}
}3.3.2 模块元数据
3.3.2.1 表格配置

{
"list-overall-lossCategory": {
"moduleName": "整体诊断结果-损失类别",
"tableName": "logis_loss_reason_nume_denom_month_dis",
"measureList": ["dakuru_loss_ratio","dakuru_loss_ratio_yoy_chg","dakuru_loss_ratio_mom_chg","peisongru_loss_ratio","peisongru_loss_ratio_yoy_chg","peisongru_loss_ratio_mom_chg","shouhouru_loss_ratio","shouhouru_loss_ratio_yoy_chg","shouhouru_loss_ratio_mom_chg","dakupyk_loss_ratio","dakupyk_loss_ratio_yoy_chg","dakupyk_loss_ratio_mom_chg","bjkpyk_loss_ratio","bjkpyk_loss_ratio_yoy_chg","bjkpyk_loss_ratio_mom_chg"],
"displayType": "table",
"page": {
"pageNo": 1,
"pageSize": 1
}
}
}3.3.2.2 图表配置
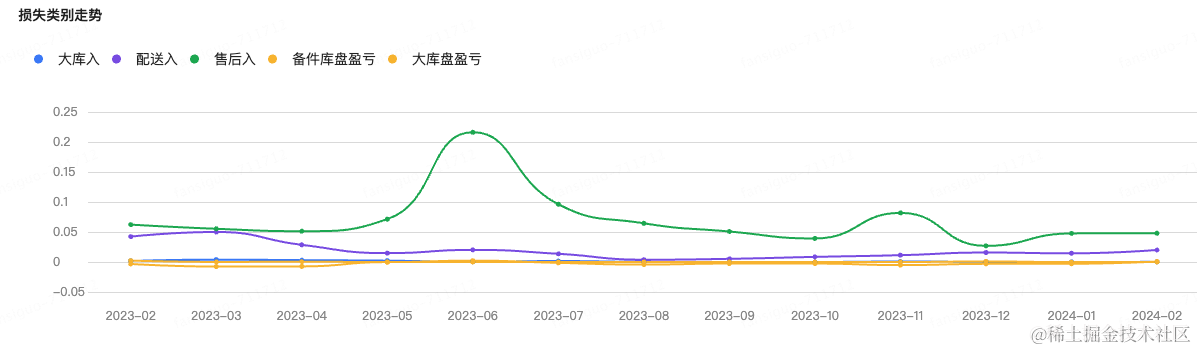
{
"chart-lossType-trend-lossRatio": {
"moduleName": "损失类别走势-损率",
"tableName": "logis_loss_reason_nume_denom_month_dis",
"dimList": ["mt"],
"measureList": ["dakuru_loss_ratio","peisongru_loss_ratio","shouhouru_loss_ratio","bjkpyk_loss_ratio","dakupyk_loss_ratio"],
"displayType": "chart",
"page": {
"pageNo": 1,
"pageSize": 13
},
"chart": {
"categoryName": "损失类别走势",
"categoryKey": "mt",
"seriesList": [
{
"key":"大库入",
"value": "dakuru_loss_ratio"
},
{
"key": "配送入",
"value": "peisongru_loss_ratio"
},
{
"key": "售后入",
"value": "shouhouru_loss_ratio"
},
{
"key": "备件库盘盈亏",
"value": "bjkpyk_loss_ratio"
},
{
"key": "大库盘盈亏",
"value": "dakupyk_loss_ratio"
}
]
}
}
}3.3.2.3 导出配置
{
"export-lossType-trend": {
"moduleName": "损失类别-损失类别走势-导出",
"tableName": "logis_loss_reason_nume_denom_month_dis",
"dimList": ["mt","loss_reason1"],
"measureList": ["distribute_loss_ratio", "loss_amount","loss_qtty"],
"filterList": [
{
"lossReason1": {
"expr": "is not null",
"value": ""
}
}
],
"headList": ["mt","loss_reason1","distribute_loss_ratio","loss_amount","loss_qtty"],
"fileName": "损失类别走势信息",
"displayType": "file",
"page": {
"pageNo": 1,
"pageSize": 1000,
"orderList": [
{
"orderField": "mt",
"orderType": "DESC"
},
{
"orderField": "loss_reason1",
"orderType": "DESC"
}
]
}
}
}四、系统集成
<dependency>
<groupId>com.jd.netsim</groupId>
<artifactId>triage-framework-core</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>通过引入maven包,新增配置文件以及实现对应的扩展点,可快速实现集成。
五、总结
本文详细介绍了一个通用OLAP框架的架构和详细设计,并分析了领域建模过程,通过引入SDK及指定配置文件的形式,后端研发可以快速实现一个OLAP应用的接口。后续可以将配置进行可视化,通过同藏经阁配置平台结合,实现产品和运营自己定制指标和页面的能力。限于篇幅,有一些重要细节点未在本文说明,读者如有兴趣进一步了解,也可以直接联系作者一起讨论。
作者:京东零售 樊思国
来源:京东云开发者社区





