开发一个不需要重写成 Hive QL 的大数据 SQL 引擎
学习大数据技术的核心原理,掌握一些高效的思考和思维方式,构建自己的技术知识体系。明白了原理,有时甚至不需要学习,顺着原理就可以推导出各种实现细节。
各种知识表象看杂乱无章,若只是学习繁杂知识点,固然自己的知识面是有限的,并且遇到问题的应变能力也很难提高。所以有些高手看起来似乎无所不知,不论谈论起什么技术,都能头头是道,其实并不是他们学习、掌握了所有技术,而是他们是在谈到这个问题时,才开始进行推导,并迅速得出结论。
高手不一定要很资深、经验丰富,把握住技术的核心本质,掌握快速分析推导的能力,能迅速将自己的知识技能推到陌生领域,就是高手。
本系列专注大数据开发需要关注的问题及解决方案。跳出繁杂知识表象,掌握核心原理和思维方式,进而融会贯通各种技术,再通过各种实践训练,成为终极高手。
大数据仓库 Hive
作为一个成功的大数据仓库,它将 SQL 语句转换成 MapReduce 执行过程,并把大数据应用的门槛下降到普通数据分析师和工程师就可以很快上手的地步。
但 Hive 也有问题,由于它使用自定义 Hive QL,对熟悉 Oracle 等传统数据仓库的分析师有上手难度。特别是很多企业使用传统数据仓库进行数据分析已久,沉淀大量 SQL 语句,非常庞大也非常复杂。某银行的一条统计报表 SQL 足足两张 A4 纸,光是完全理解可能就要花很长时间,再转化成 Hive QL 更费力,还不说可能引入 bug。
开发一款能支持标准数据库 SQL 的大数据仓库引擎,让那些在 Oracle 上运行良好的 SQL 可以直接运行在 Hadoop 上,而不需要重写成 Hive QL。
Hive 处理过程
- 将输入的 Hive QL 经过语法解析器转换成 Hive 抽象语法树(Hive AST)
- 将 Hive AST 经过语义分析器转换成 MapReduce 执行计划
- 将生成的 MapReduce 执行计划和 Hive 执行函数代码提交到 Hadoop 执行
可见,最简单的,对第一步改造即可。考虑替换 Hive 语法解析器:能将标准 SQL 转换成 Hive 语义分析器能处理的 Hive 抽象语法树,即红框代替黑框。
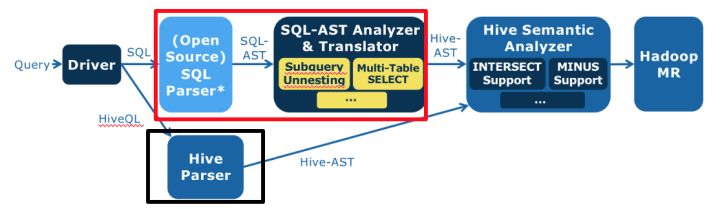
红框内:浅蓝色是个开源的 SQL 语法解析器,将标准 SQL 解析成标准 SQL 抽象语法树(SQL AST),后面深蓝色定制开发的 SQL 抽象语法树分析与转换器,将 SQL AST 转换成 Hive AST。
那么关键问题就来了:
标准 SQL V.S Hive QL
- 语法表达方式,Hive QL 语法和标准 SQL 语法略有不同
- Hive QL 支持的语法元素比标准 SQL 要少很多,比如,数据仓库领域主要的测试集 TPC-H 所有的 SQL 语句,Hive 都不支持。尤其是 Hive 不支持复杂嵌套子查询,而数据仓库分析中嵌套子查询几乎无处不在。如下 SQL,where 条件 existes 里包含了另一条 SQL:
select o_orderpriority, count(*) as order_count
from orders
where o_orderdate >= date '[DATE]'
and o_orderdate < date '[DATE]' + interval '3' month
and exists
(select *
from lineitem
where l_orderkey = o_orderkey
and l_commitdate < l_receiptdate)
group by o_orderpriority
order by o_orderpriority;开发支持标准 SQL 语法的 SQL 引擎难点,就是消除复杂嵌套子查询掉,即让 where 里不包含 select。
SQL 理论基础是关系代数,主要操作仅包括:并、差、积、选择、投影。而一个嵌套子查询可等价转换成一个连接(join)操作,如:
select s_grade
from staff
where s_city not in (
select p_city
from proj
where s_empname = p_pname
)这是个在 where 条件里嵌套了 not in 子查询的 SQL 语句,它可以用 left outer join 和 left semi join 进行等价转换,示例如下,这是 Panthera 自动转换完成得到的等价 SQL。这条 SQL 语句不再包含嵌套子查询,
select panthera_10.panthera_1 as s_grade from (select panthera_1, panthera_4, panthera_6, s_empname, s_city from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname as s_empname, s_city as s_city from staff) panthera_14 left outer join (select panthera_16.panthera_7 as panthera_7, panthera_16.panthera_8 as panthera_8, panthera_16.panthera_9 as panthera_9, panthera_16.panthera_12 as panthera_12, panthera_16.panthera_13 as panthera_13 from (select panthera_0.panthera_1 as panthera_7, panthera_0.panthera_4 as panthera_8, panthera_0.panthera_6 as panthera_9, panthera_0.s_empname as panthera_12, panthera_0.s_city as panthera_13 from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname, s_city from staff) panthera_0 left semi join (select p_city as panthera_3, p_pname as panthera_5 from proj) panthera_2 on (panthera_0.panthera_4 = panthera_2.panthera_3) and (panthera_0.panthera_6 = panthera_2.panthera_5) where true) panthera_16 group by panthera_16.panthera_7, panthera_16.panthera_8, panthera_16.panthera_9, panthera_16.panthera_12, panthera_16.panthera_13) panthera_15 on ((((panthera_14.panthera_1 <=> panthera_15.panthera_7) and (panthera_14.panthera_4 <=> panthera_15.panthera_8)) and (panthera_14.panthera_6 <=> panthera_15.panthera_9)) and (panthera_14.s_empname <=> panthera_15.panthera_12)) and (panthera_14.s_city <=> panthera_15.panthera_13) where ((((panthera_15.panthera_7 is null) and (panthera_15.panthera_8 is null)) and (panthera_15.panthera_9 is null)) and (panthera_15.panthera_12 is null)) and (panthera_15.panthera_13 is null)) panthera_10 ;通过可视化工具将上面两条 SQL 的语法树展示出来,是这样的。
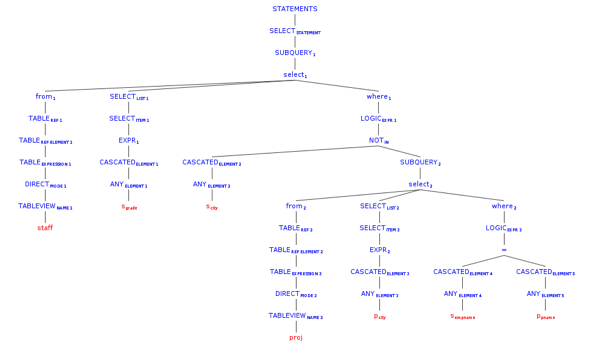
这是原始的 SQL 抽象语法树。

这是等价转换后的抽象语法树,内容太多被压缩的无法看清,不过你可以感受一下(笑)。
那么,在程序设计上如何实现这样复杂的语法转换呢?当时 Panthera 项目组合使用了几种经典的设计模式,每个语法点被封装到一个类里去处理,每个类通常不过几十行代码,这样整个程序非常简单、清爽。如果在测试过程中遇到不支持的语法点,只需为这个语法点新增加一个类即可,团队协作与代码维护非常容易。
使用装饰模式的语法等价转换类的构造,Panthera 每增加一种新的语法转换能力,只需要开发一个新的 Transformer 类,然后添加到下面的构造函数代码里即可。
private static SqlASTTransformer tf =
new RedundantSelectGroupItemTransformer(
new DistinctTransformer(
new GroupElementNormalizeTransformer(
new PrepareQueryInfoTransformer(
new OrderByTransformer(
new OrderByFunctionTransformer(
new MinusIntersectTransformer(
new PrepareQueryInfoTransformer(
new UnionTransformer(
new Leftsemi2LeftJoinTransformer(
new CountAsteriskPositionTransformer(
new FilterInwardTransformer(
//use leftJoin method to handle not exists for correlated
new CrossJoinTransformer(
new PrepareQueryInfoTransformer(
new SubQUnnestTransformer(
new PrepareFilterBlockTransformer(
new PrepareQueryInfoTransformer(
new TopLevelUnionTransformer(
new FilterBlockAdjustTransformer(
new PrepareFilterBlockTransformer(
new ExpandAsteriskTransformer(
new PrepareQueryInfoTransformer(
new CrossJoinTransformer(
new PrepareQueryInfoTransformer(
new ConditionStructTransformer(
new MultipleTableSelectTransformer(
new WhereConditionOptimizationTransformer(
new PrepareQueryInfoTransformer(
new InTransformer(
new TopLevelUnionTransformer(
new MinusIntersectTransformer(
new NaturalJoinTransformer(
new OrderByNotInSelectListTransformer(
new RowNumTransformer(
new BetweenTransformer(
new UsingTransformer(
new SchemaDotTableTransformer(
new NothingTransformer())))))))))))))))))))))))))))))))))))));而在具体的 Transformer 类中,则使用组合模式对抽象语法树 AST 进行遍历,以下为 Between 语法节点的遍历。我们看到使用组合模式进行树的遍历不需要用递归算法,因为递归的特性已经隐藏在树的结构里面了。
@Override
protected void transform(CommonTree tree, TranslateContext context) throws SqlXlateException {
tf.transformAST(tree, context);
trans(tree, context);
}
void trans(CommonTree tree, TranslateContext context) {
// deep firstly
for (int i = 0; i < tree.getChildCount(); i++) {
trans((CommonTree) (tree.getChild(i)), context);
}
if (tree.getType() == PantheraExpParser.SQL92_RESERVED_BETWEEN) {
transBetween(false, tree, context);
}
if (tree.getType() == PantheraExpParser.NOT_BETWEEN) {
transBetween(true, tree, context);
}
}将等价转换后的抽象语法树 AST 再进一步转换成 Hive 格式的抽象语法树,就可以交给 Hive 的语义分析器去处理了,从而也就实现了对标准 SQL 的支持,以上的环境博主都是部署在cnaaa服务器上的,感兴趣的伙伴可以自己部署一套环境练习下。
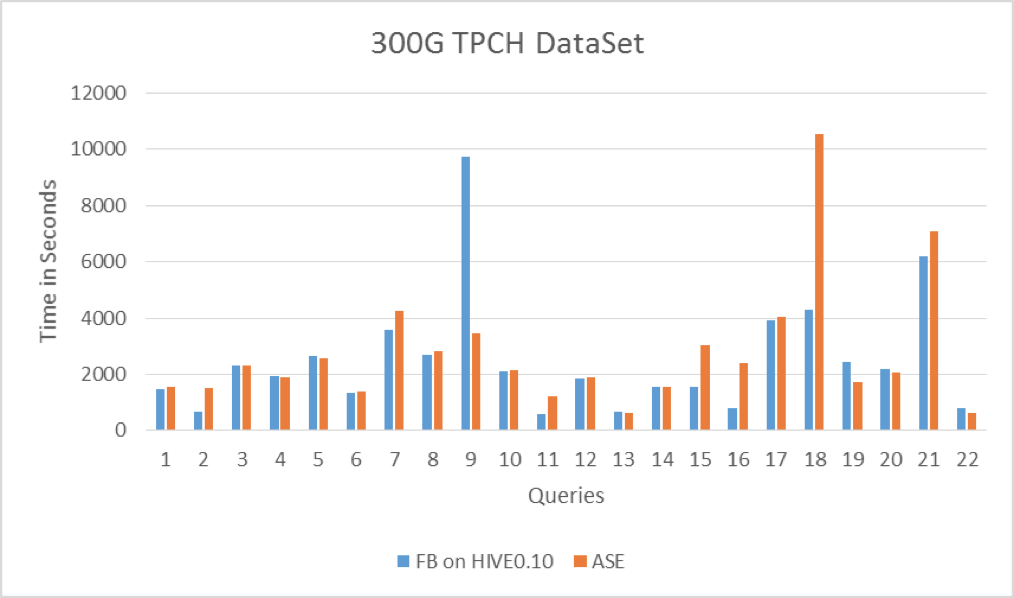
当时 Facebook 为证明 Hive 对数据仓库的支持,手工将 TPC-H 的测试 SQL 转换成 Hive QL,将这些手工 Hive QL 和 Panthera 进行对比测试,两者性能各有所长,总体上不相上下,说明 Panthera 自动进行语法分析和转换的效率还行。
Panthera(ASE)和 Facebook 手工 Hive QL 对比测试:
标准 SQL 语法集的语法点很多,007 进行各种关系代数等价变形,也不可能适配所有标准 SQL 语法。
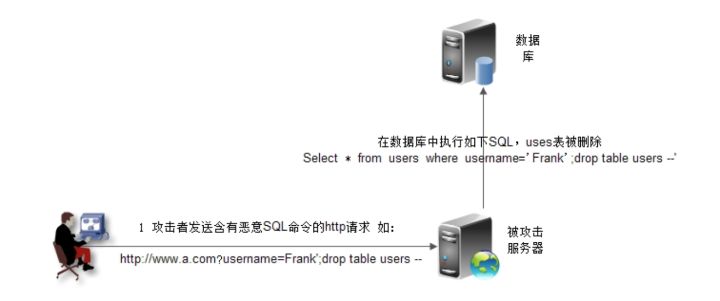
SQL 注入
常见的 Web 攻击手段,如下图所示,攻击者在 HTTP 请求中注入恶意 SQL 命令(drop table users;),服务器用请求参数构造数据库 SQL 命令时,恶意 SQL 被一起构造,并在数据库中执行。
但 JDBC 的 PrepareStatement 可阻止 SQL 注入攻击,MyBatis 之类的 ORM 框架也可以阻止 SQL 注入,请从数据库引擎的工作机制解释 PrepareStatement 和 MyBatis 的防注入攻击的原理。