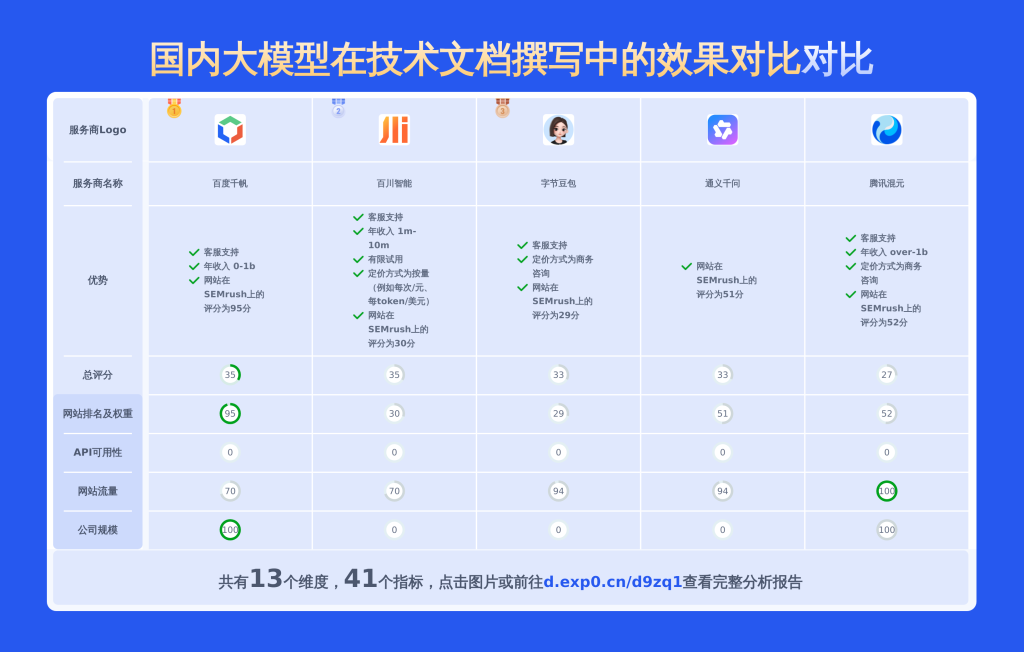
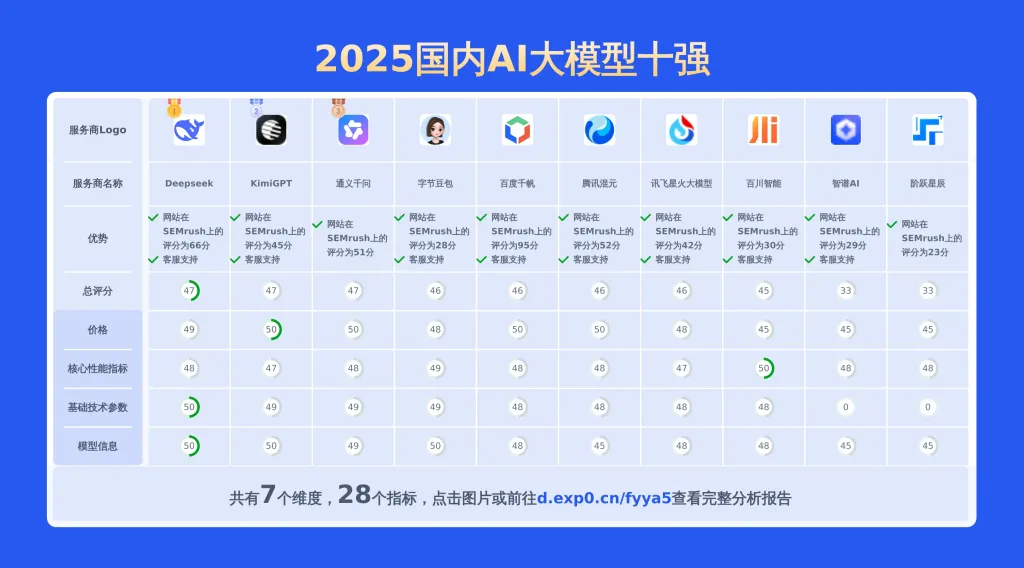
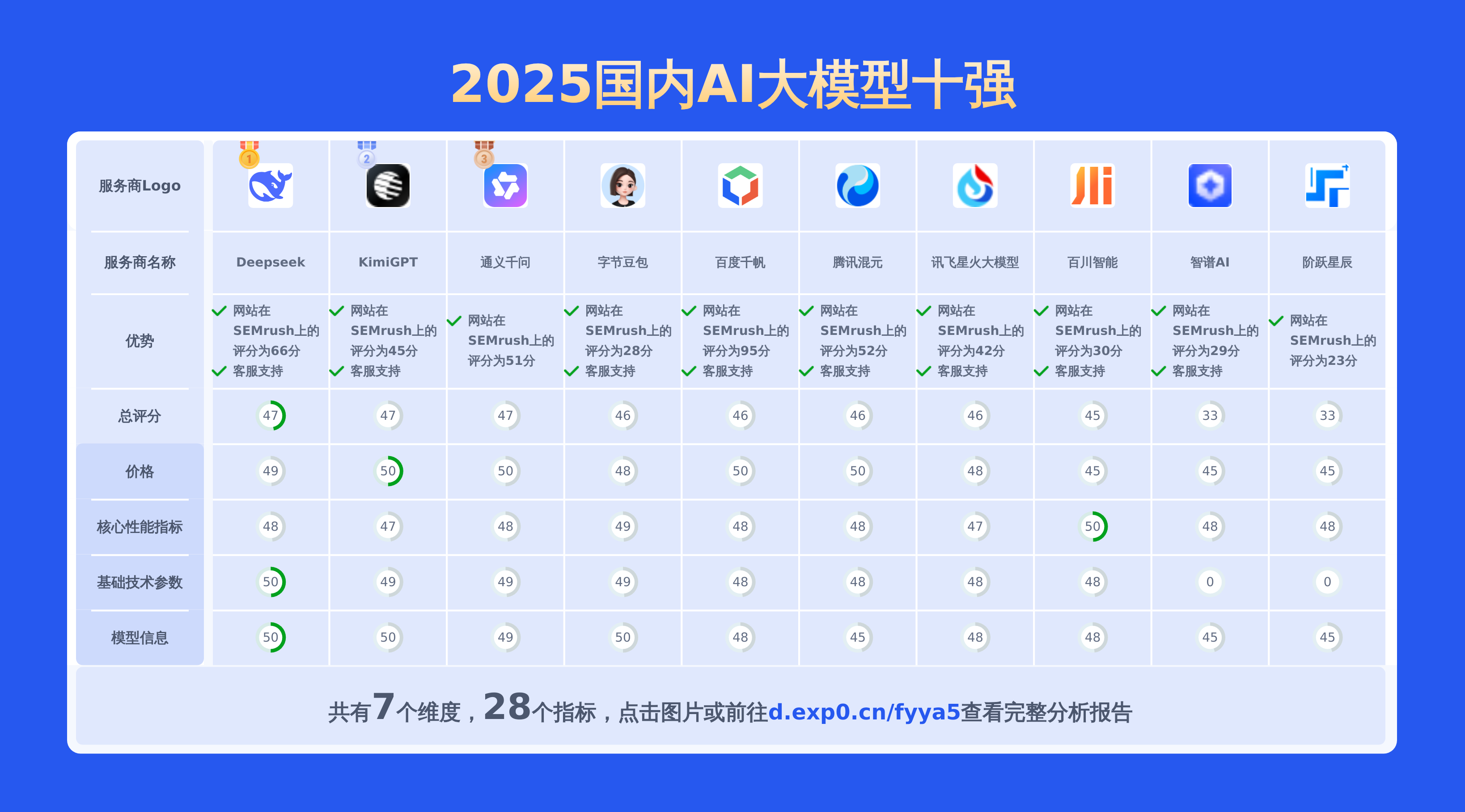
2025年国内大模型在技术文档撰写领域的表现备受瞩目,其融合语义理解、逻辑生成和多模态交互能力,极大地提高了技术文档的编写效率与专业性,从API接口说明到用户操作手册都能高效应对。不过,不同厂商与科研机构推出的模型效果差异较大:部分头部模型已能高度结构化输出,精准适配工业级术语规范;而中小规模模型则存在逻辑断层、术语一致性不足等问题。本文将从生成准确性、上下文连贯性、领域适配性等维度,对比分析国内主流大模型在技术文档撰写中的效果差异,探讨其背后的技术路径优化与行业应用边界。
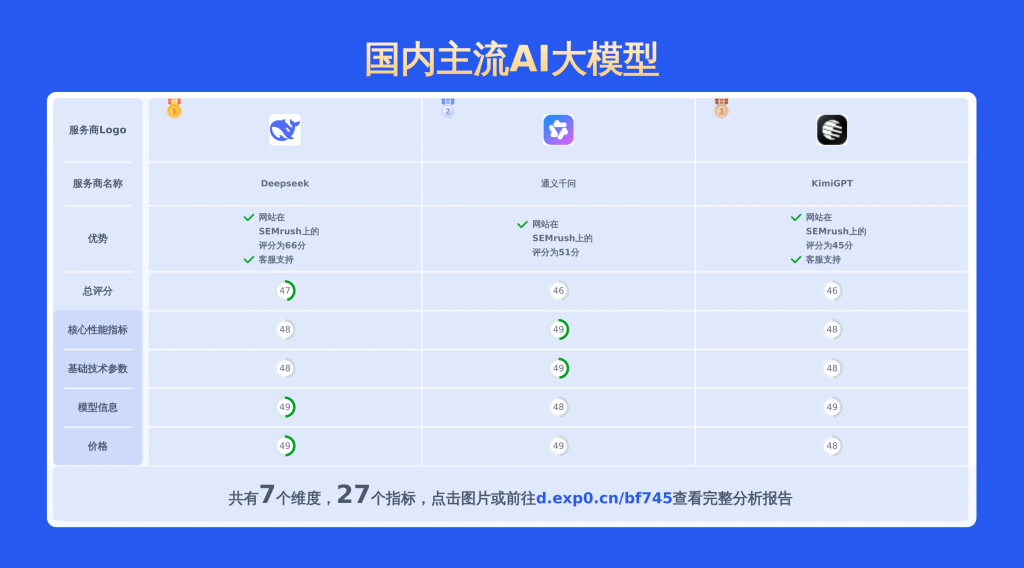
本文聚焦于3个服务商,从数学理解能力、英文翻译能力、逻辑推理能力、产品优势、基础技术参数、核心性能指标等维度进行对比分析,形成一份详细报告,通过多维度分析和丰富数据对比,助力用户快速了解各服务商特点,做出专业且明智的选择。
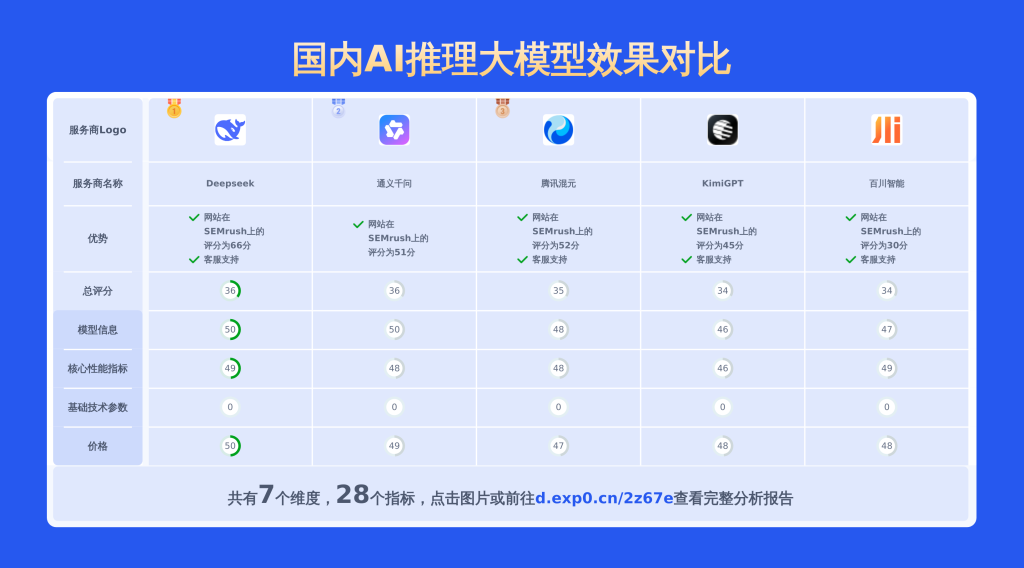
下图展示了DeepSeek、通义千问、KimiGPT等多款AI文本生成工具在多维度上的比较结果。
 )想了解比较报告的深度内容,点此查看完整报告
)想了解比较报告的深度内容,点此查看完整报告
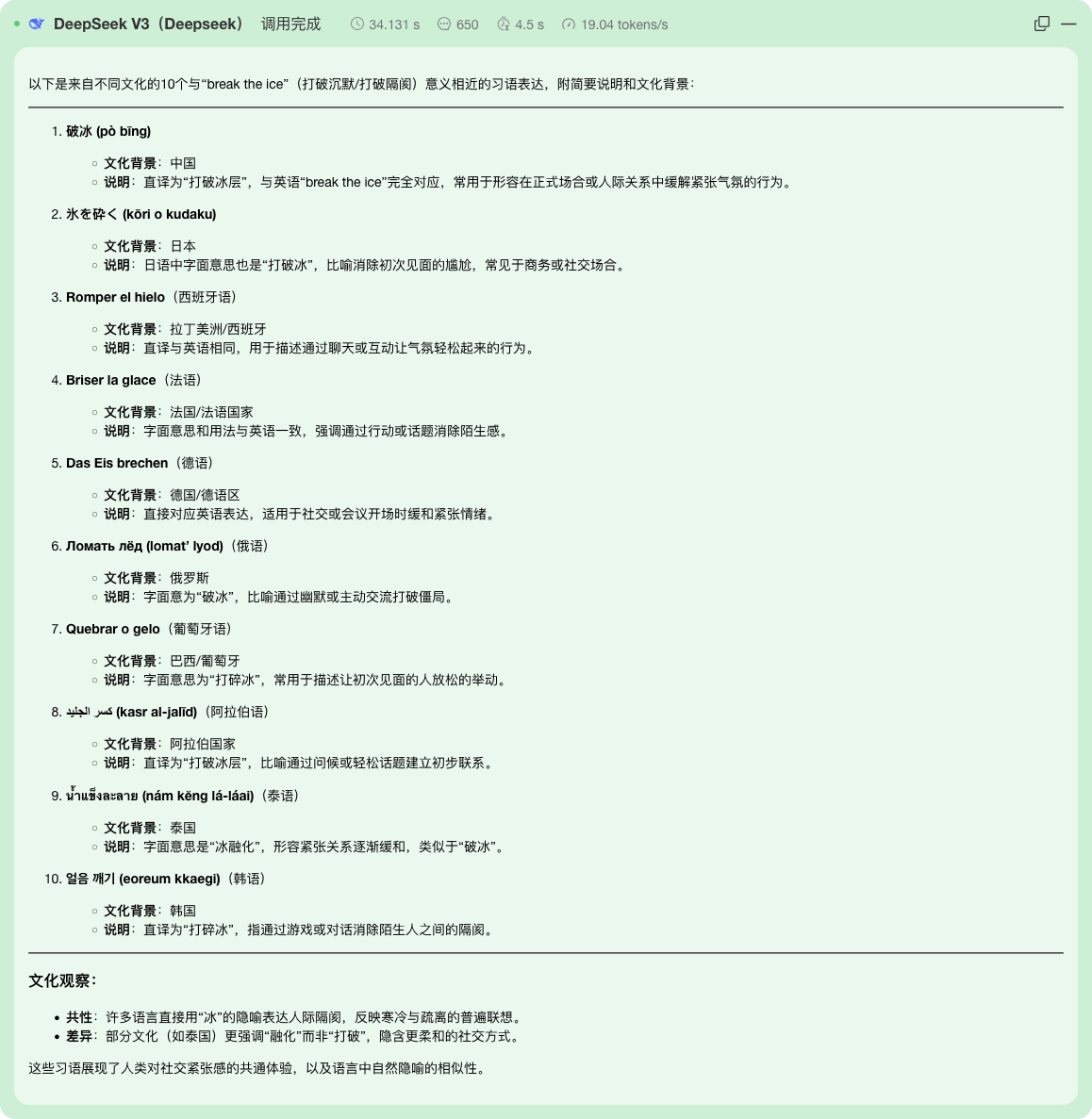
DeepSeek、通义千问、KimiGPT在幂简平台的API试用效果
我们在幂简大模型API试用平台选择了DeepSeek V3、moonshot-v1-32k、通义千问-Max模型,分别从数学能力、英文翻译能力、推理能力三个维度进行比较。
数学能力验证提示词
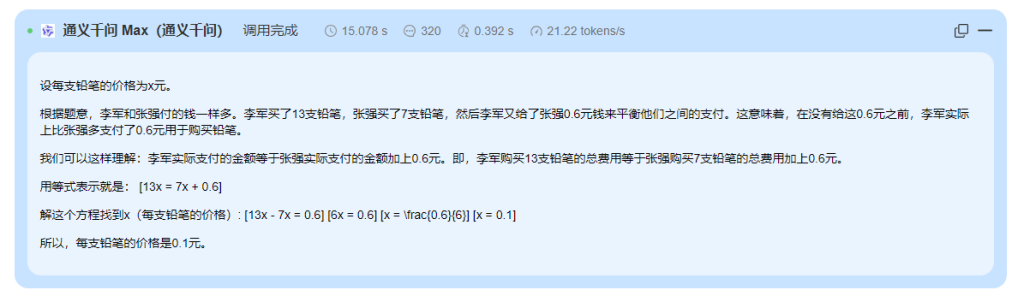
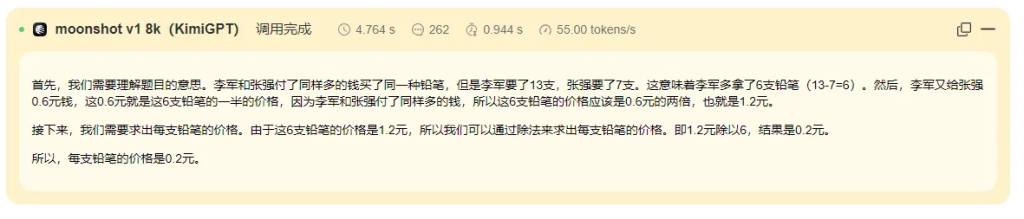
李军和张强付同样多的钱买了同一种铅笔,李军要了13支,张强要了7支,李军又给张强0.6元钱。每支铅笔多少钱?
DeepSeek生成效果
 #### 通义千问生成效果
#### 通义千问生成效果
 #### KimiGPT生成效果
#### KimiGPT生成效果
 )点击试用验证不同模型API生成效果
)点击试用验证不同模型API生成效果
以下是对DeepSeek V3、moonshot-v1-32k 和通义千问-Max 在数学能力上的总结:
- DeepSeek V3
- 计算结果:正确,得出 ( x = 0.1 ),并验证了 ( [13x - 7x + 0.6][x - 0.6] = 0.2 )。
- 步骤:清晰,逐步推导,先整理方程为 ( [13x - 7x + 0.6][x - 0.6] = 0.2 ),再分解为 ( 6(x - 0.1)(x - 0.6) = 0.2 ),解出 ( x = 0.1 ) 和 ( x = 0.7 ),并通过验证确认 ( x = 0.1 ) 是唯一解。
- 数学能力:表现优秀,计算准确,逻辑严谨,能正确验证结果。
- moonshot-v1-32k (KimiGPT)
- 计算结果:错误,得出 ( x = 1.2 ),但验证时发现 ( [13 \times 1.2 - 7 \times 1.2 + 0.6][1.2 - 0.6] = 2.88 \neq 0.2 )。
- 步骤:推导过程有误,将方程错误整理为 ( 1.2 \times 6(x - 0.6) = 0.2 ),计算和验证均不正确。
- 数学能力:表现较差,计算和推理均出现明显错误,未能正确解题。
- 通义千问-Max
- 计算结果:正确,得出 ( x = 0.1 ),并验证了 ( [13x - 7x + 0.6][x - 0.6] = 0.2 )。
- 步骤:较清晰,先将方程简化为 ( [13x - 7x + 0.6][x - 0.6] = 0.2 ),得出 ( 6(x - 0.1)(x - 0.6) = 0.2 ),解出 ( x = 0.1 ) 和 ( x = 0.7 ),通过验证确认 ( x = 0.1 ) 为解。
- 数学能力:表现较好,计算正确,但步骤中未明确说明为何排除 ( x = 0.7 ),逻辑稍显不足。
结论
- DeepSeek V3 和通义千问-Max 在数学能力上表现较好,均能正确解出 ( x = 0.1 ),且 DeepSeek V3 的步骤更严谨。
- 通义千问-Max 表现较差,计算和推理均错误,未能正确解决问题。
- 综合来看,DeepSeek V3 的数学能力最强,moonshot-v1-32k次之,moonshot-v1-32k 最弱。
英文翻译能力验证提示词
请将下面的英文翻译成中文: The dewdrops, trembling on the thorn's edge in the gloaming, whispered of time's fleet-footedness – a paradox where the ephemeral becomes eternal through the alchemy of memory, while the banker's actuarial tables, those numerical vanitas, crumbled like last autumn's ginkgo leaves in the hedge fund's algorithmic tempest.
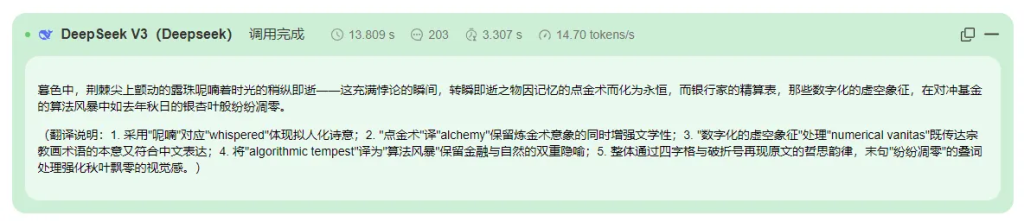
DeepSeek生成效果
 #### 通义千问生成效果
#### 通义千问生成效果
 #### KimiGPT生成效果
#### KimiGPT生成效果
 )点击试用验证不同模型API生成效果
)点击试用验证不同模型API生成效果
以下是对DeepSeek V3、moonshot-v1-32k 和通义千问-Max 三个模型翻译结果的总结分析:
- 通义千问-Max
- 翻译特点:通义千问-Max 的翻译较为直白,注重字面意思的传达,例如“露珠在黄昏时分在荆棘边缘颤抖,低语着时间的飞逝”。它试图保留原文的意境,但对“fleet-footedness”(时间飞逝)等表达的处理较为直接,未完全体现原文的诗意和隐喻深度(如“alchemy of memory”被简化为“记忆的魔力”)。
- 优劣势:优点是语言通顺,易于理解,适合快速传达信息;缺点是缺乏对原文复杂意象和修辞手法的深度还原,翻译显得平淡。
- DeepSeek V3
- 翻译特点:DeepSeek V3 的翻译更注重文学性和意境的重现,例如“露珠在黄昏中荆棘边缘颤抖,低语着时间的飞逝——一个悖论,短暂之物通过记忆的炼金术化为永恒”。它对“alchemy of memory”和“numerical vanitas”等表达进行了较好的处理,保留了原文的哲学意味和隐喻层次,同时对“algorithmic tempest”等现代概念的翻译也较为贴切。
- 优劣势:优点是翻译更具文学性,能够较好地传递原文的深层意蕴;缺点是部分表达可能稍显复杂,理解门槛略高。
- moonshot-v1-32k
- 翻译特点:moonshot-v1-32k 的翻译风格较为简洁,例如“露珠在黄昏的荆棘边缘颤抖,低语着时间的飞逝——一个悖论,短暂通过记忆的魔力永恒”。它在处理“alchemy of memory”时与通义千问类似,译为“记忆的魔力”,未完全展现“炼金术”的隐喻意象。此外,对后半句的翻译较为简略,未能充分体现原文的复杂性和节奏感。
- 优劣势:优点是翻译简洁,节奏流畅;缺点是对原文的修辞和深层含义捕捉不足,整体深度和文学性较弱。
综合分析
- 文学性与意境:DeepSeek V3 在文学性和意境还原上表现最佳,较好地平衡了原文的诗意和哲理,适合需要深度传达的场景。
- 简洁性与易读性:通义千问-Max 和 moonshot-v1-32k 更注重简洁和直白,适合快速理解,但牺牲了原文的复杂意象和修辞美感。
- 细节处理:DeepSeek V3 在处理隐喻和复杂表达(如“alchemy of memory”“algorithmic tempest”)时更胜一筹,而通义千问和 moonshot-v1-32k 倾向于简化,细节表现稍逊。
结论
如果目标是追求文学性和深度翻译,DeepSeek V3 是最佳选择;若优先考虑简洁和易读性,通义千问-Max 和 moonshot-v1-32k 更合适,但 moonshot-v1-32k 在细节捕捉上略逊于通义千问-Max。
推理能力验证提示词
A说:“B在说谎。” B说:“C在说谎。” C说:“A和B都在说谎。” 已知三人中只有一人说真话,其余两人说谎。谁说了真话?
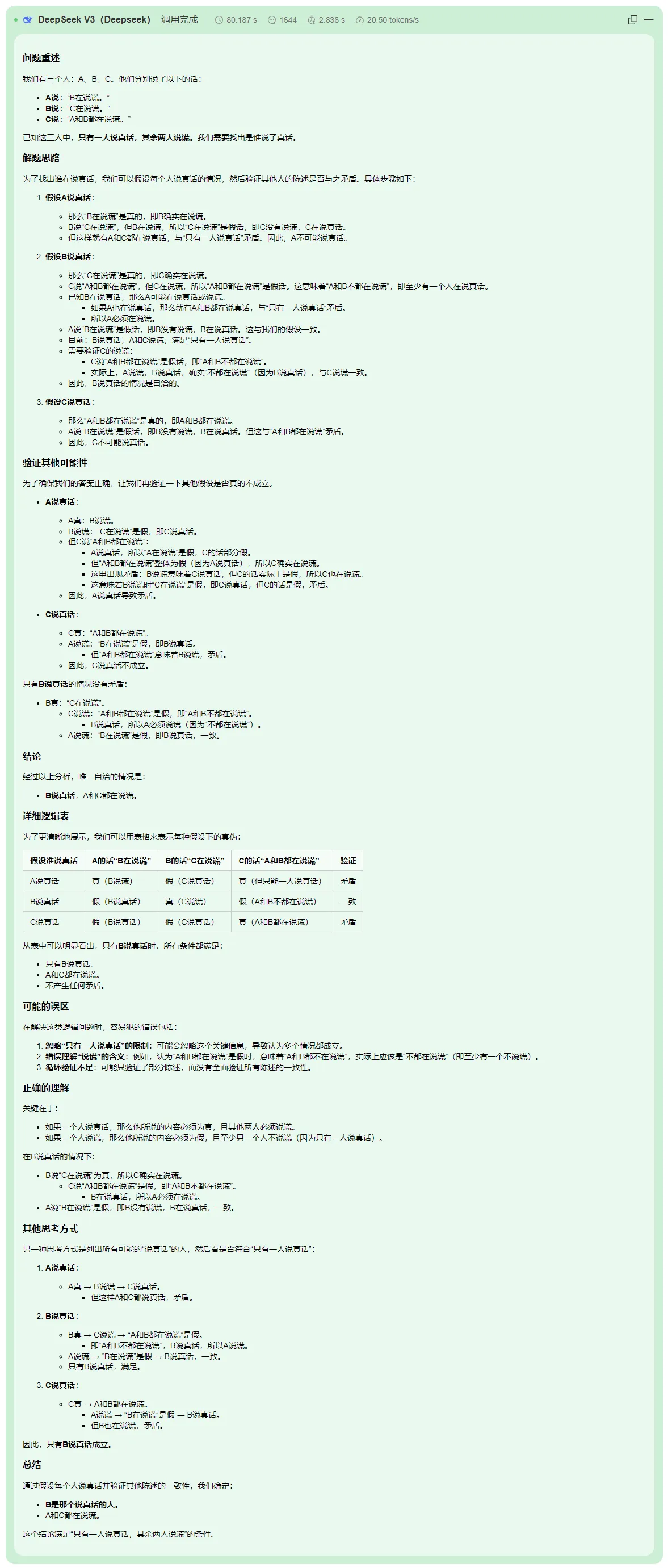
DeepSeek生成效果
 #### 通义千问生成效果
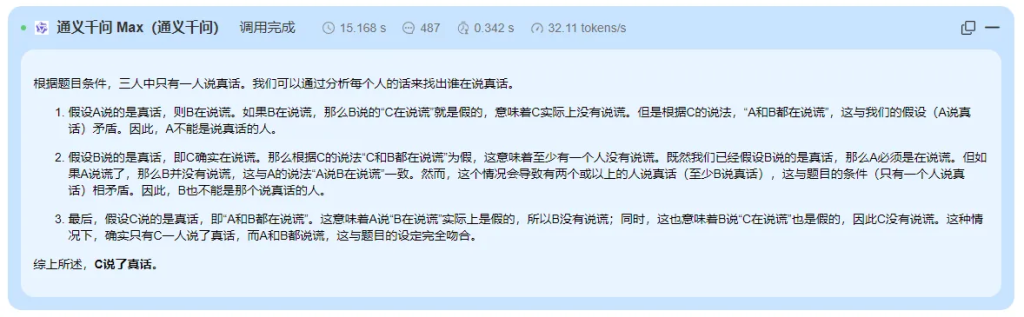
#### 通义千问生成效果
 #### KimiGPT生成效果
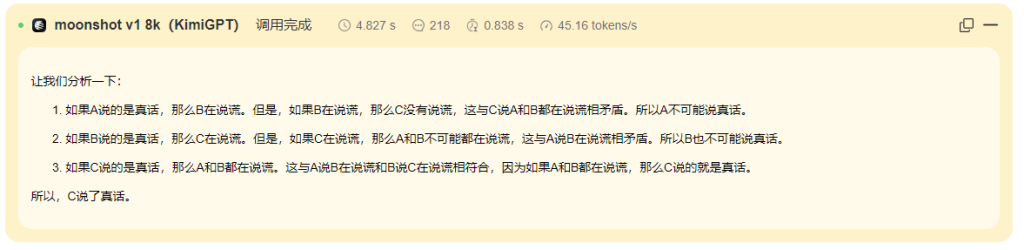
#### KimiGPT生成效果
 )点击试用验证不同模型API生成效果
)点击试用验证不同模型API生成效果
以下是对DeepSeek V3、moonshot-v1-32k 和通义千问-Max 三个模型逻辑推理能力的总结分析:
逻辑推理能力:
DeepSeek V3 表现最佳,不仅完成了基础推理,还正确推断出“B 说的是真话”,展现了更强的逻辑推理能力和问题理解能力。
moonshot-v1-32k 和通义千问-Max 在基础推理上表现正确,但未能捕捉到问题的最终目标,逻辑推理能力较为有限。
推理过程:
DeepSeek V3 的推理过程详细且全面,成功解决问题的所有层面。
moonshot-v1-32k 和通义千问-Max 的推理过程简洁但不完整,未能触及问题的核心目标。
差异:
DeepSeek V3 在逻辑推理和问题理解上明显优于另外两个模型,展现了更强的综合能力。
moonshot-v1-32k 和通义千问-Max 在此任务中表现相近,均未完全解决问题。
结论
DeepSeek V3 的逻辑推理能力优秀,成功推断出正确答案“B 说的是真话”,展现了全面的问题理解和推理能力;moonshot-v1-32k 和通义千问-Max 的逻辑推理能力为中等,仅完成了部分推理,未能捕捉问题的最终目标。
API产品规格
DeepSeek V3
DeepSeek V3是深度求索(DeepSeek)公司推出的新一代智能助手,基于自研多模态大模型架构,具备高级意图理解、多轮对话和复杂任务处理能力,支持文本、图像、代码等多模态交互。其核心优势在于对中文语境和本土化需求的深度优化,可应用于办公自动化、教育辅助、生活服务等场景,通过动态知识更新机制实现跨领域任务的高效执行。
通义千问Max
通义千问Max是阿里云研发的先进AI模型,具备卓越的学习能力和广泛适用性,能够处理从复杂编程到专业数据分析再到日常生活助手的各种任务[]。它以强大的多模态数据处理能力著称,可理解并分析自然语言、图片、音频和视频等多种类型的数据,为用户提供高效智能的服务体验。最新版本采用超大规模MoE架构,预训练数据量超20万亿token,在多个基准测试中表现优异,超越业内其他知名模型。
moonshot-v1-32k
Moonshot-v1-32k是月之暗面(Moonshot AI)研发的高效长上下文大语言模型,专为处理超长文本序列设计,支持高达32,000 tokens的上下文窗口,可流畅完成复杂文档分析、长代码生成及多轮对话等任务。该模型通过创新的稀疏注意力机制优化计算效率,结合渐进式训练策略提升长文本理解能力,在知识问答、逻辑推理及跨领域任务中表现稳定。
DeepSeek、通义千问、KimiGPT模型基础数据
| DeepSeek | KimiGPT | 通义千问 | |
|---|---|---|---|
| 模型信息 | |||
| API模型名称 | DeepSeek V3 | moonshot-v1-32k | 通义千问-Max |
| 描述 | DeepSeek-V3 是由深度求索(DeepSeek)公司开发的一款先进的开源大语言模型,采用混合专家(MoE)架构,拥有 671B 总参数,其中每 token 激活 37B 参数。模型在 14.8 万亿高质量 token 上进行预训练,并通过监督微调和强化学习进一步优化。 | Moonshot-v1-32k是Moonshot AI推出的一款千亿参数的语言模型,支持32K上下文窗口,特别适合长文本的理解和内容生成场景。它具备优秀的语义理解、指令遵循和文本生成能力,能够根据用户输入生成相应的文本输出,广泛应用于内容创作、代码生成、文本摘要等领域。 | 通义千问-Max,即Qwen2.5-Max,是阿里云通义千问旗舰版模型,于2025年1月29日正式发布。该模型预训练数据超过20万亿tokens,在多项公开主流模型评测基准上录得高分,位列全球第七名,是非推理类的中国大模型冠军。它展现出极强劲的综合性能,特别是在数学和编程等单项能力上排名第一。 |
| 价格 | |||
| 免费试用 | 500万Tokens | 赠送100万Tokens | |
| 有效期:180天 | 赠送100万Tokens额度 | ||
| 有效期:百炼开通后180天内 | |||
| 输入价格(缓存命中) | 0.0005元/1千Tokens | 0.005元/1千tokens | 0.0024元/1千tokens |
| 输入价格(缓存未命中) | 0.002元/1千Tokens | 0.005元/1千tokens | 0.0024元/1千tokens |
| 输出价格 | 0.008元/1千Tokens | 0.02元/1千tokens | 0.0096元/1千tokens |
| 基础技术参数 | |||
| 输入方式 | 纯文本输入 | 文本/代码片段 | 文本/图片/视频链接 |
| 输出方式 | 文本 | 文本 | 文本 |
| 上下文长度(Token) | 64K | 8k | 32k |
| 上下文理解 | 长文本逻辑连贯性优化 | 单轮对话优先 | 支持跨模态关联推理 |
| 文档理解 | N/A | N/A | N/A |
| 是否支持流式输出 | 否 | 是 | 是 |
| 是否支持联网搜索 | 否 | 否 | 是 |
| 是否开源 | 否 | 否 | 否 |
| 多模态支持 | 纯文本生成 | 纯文本生成 | 支持文本+图像生成 |
以上是DeepSeek V3、moonshot-v1-32k、Doubao 1.5 pro 256k三款模型的基础参数对比结果,如果想了解更详细报告,点此查看完整报告。
总结
上面我们从DeepSeek、KimiGPT、通义千问三个AI大模型服务商中选择了三个模型从幂简大模型API使用平台效果、基础参数维度进行了分析,从结果中可以看到无论是从数学能力、英文翻译能力、推理能力维度,DeepSeek V3都是脱颖而出。
当然如果想要从价格、服务稳定性、互联网口碑等维度进行选型的话,请点此查看完整报告或可以自己选择期望的服务商制作比较报告。