
1 前言
众所周知,Spring可以帮我们管理我们需要的bean。在我们需要用到这些bean的时候,可以很方便的获取到它,然后进行一系列的操作。比如,我们定义一个bean MyTestBean。
public class MyTestBean {
private String testStr = "testStr";
public String getTestStr() {
return testStr;
}
public void setTestStr(String testStr) {
this.testStr = testStr;
}然后xml配置一下
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd">
<bean id = "myTestBean" class="bean.MyTestBean"/>
</beans>编写一下测试代码,测试一下,就会看到测试通过的结果。
public class BeanFactoryTest {
@Test
public void testSimpleLoad() {
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("beanFactoryTest.xml"));
MyTestBean bean = (MyTestBean)bf.getBean("myTestBean");
assert "testStr".equals(bean.getTestStr());
}
}直接使用BeanFactory作为容器对于Spring来说不常见,这里只是用来测试,以便可以更快更好地分析Spring内部原理。其涉及到的一些组件,贯穿整个Spring容器当中,对于我们了解其他Spring容器也有很大的帮助。限于篇幅,这里只介绍该容器创建的部分,即对于new XmlBeanFactory(new ClassPathResource(“beanFactoryTest.xml”)),Spring都干了些什么。
2 Spring容器创建原理
2.1 整体实现流程
首先我们大致了解一下Spring容器创建的整体过程。
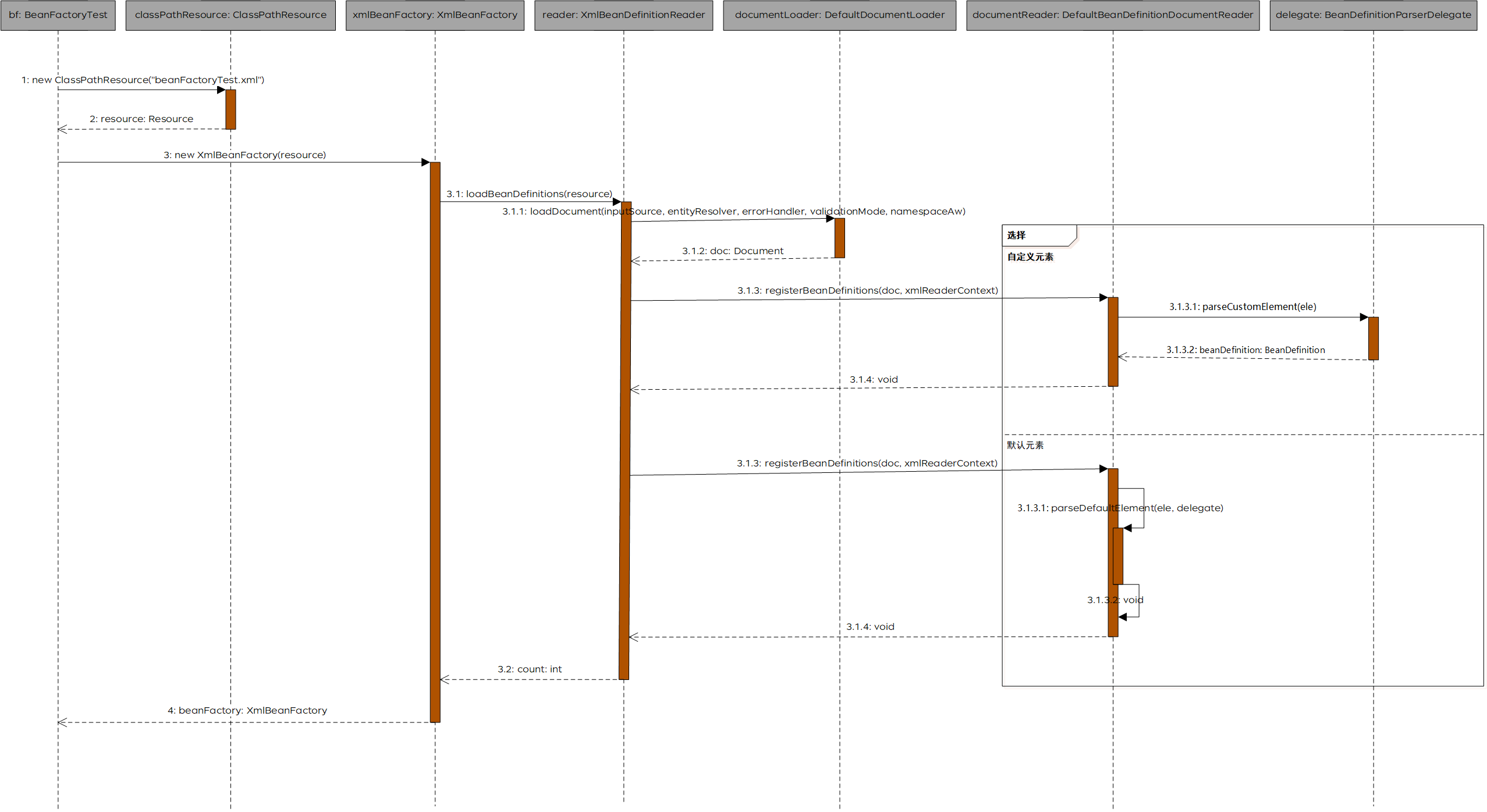
整体时序图
可以看到,该Spring容器创建大致分为以下几部分:
- 资源的封装,以Resource封装配置文件
- 加载BeanDefinition
- 解析配置文件,获取Document
- 解析及注册BeanDefinition
- 标签的解析,分为默认标签和自定义标签的解析
下面我们就以这样的顺序对各个部分从代码实现上进行具体分析。
2.2 核心类介绍
在进行具体创建逻辑之前,我们先对Spring容器创建的核心类进行介绍,以便我们更好地掌握它的实现过程。
2.2.1 DefaultListableBeanFactory
XmlBeanFactory继承自DefaultListableBeanFactory,而DefaultListableBeanFactory是整个bean加载的核心部分,是Spring注册及加载bean的默认实现。XmlBeanFactory与DefaultListableBeanFactory的不同之处在于,XmlBeanFactory使用了自定义的XML读取器XmlBeanDefinitionReader,实现了个性化的BeanDefinitionReader读取。
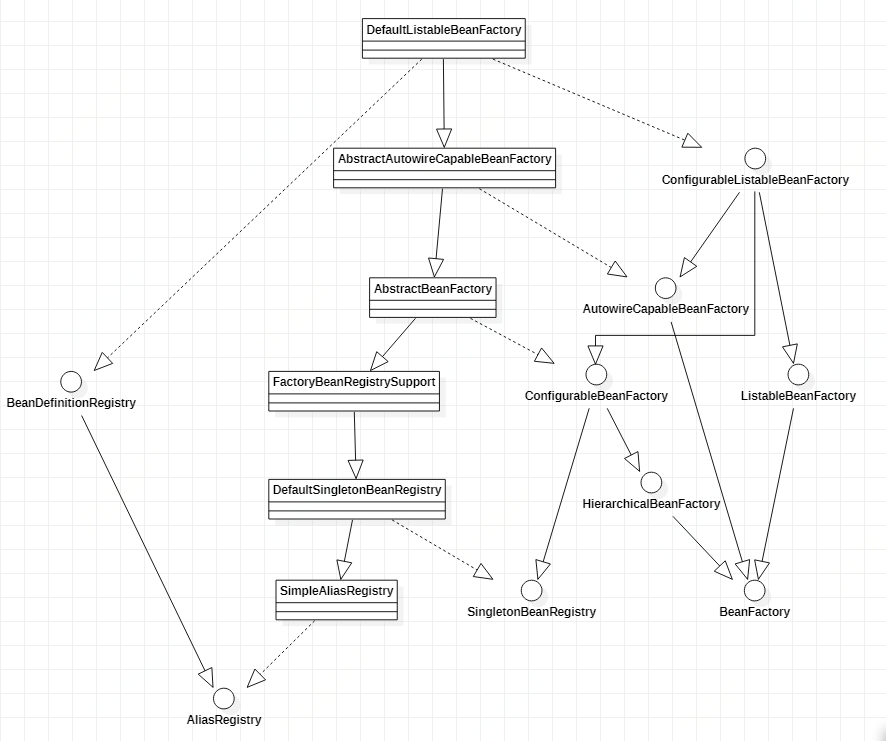
容器加载相关类图
2.2.2 XmlBeanDefinitionReader
XmlBeanDefinitionReader用于资源文件读取、解析及Bean注册。读取Xml配置文件的流程大致为,首先使用ResourceLoader将资源文件路径转换为对应的Resource文件,然后将Resource文件转换为Document文件,最后对Document及Element进行解析。
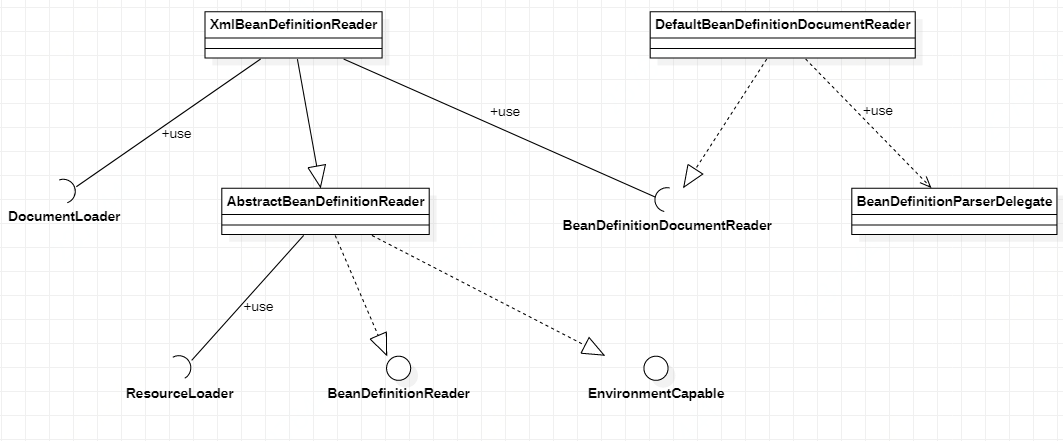
配置文件读取相关类图
2.2.3 BeanDefinition
在Spring中,BeanDefinition是配置文件元素标签在容器中的内部表示形式,包含了元素的所有信息。Spring将配置文件中的转换为BeanDefinition,并将这些BeanDefinition注册到BeanDefinitionRegistry中。BeanDefinitionRegistry以map形式保存,后续操作直接从BeanDefinitionRegistry中读取配置信息。
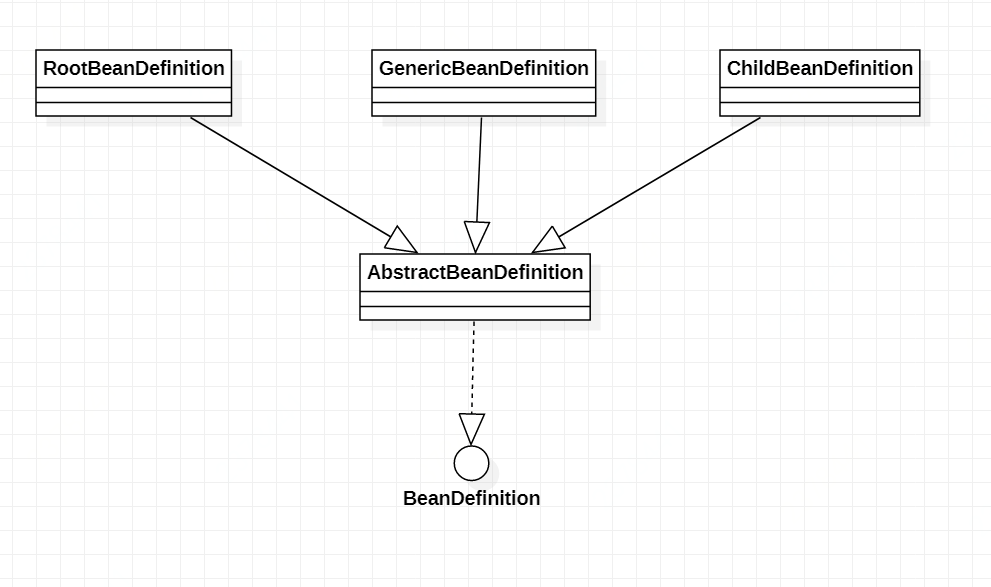
BeanDefinition及其实现类
2.3 配置文件的封装
在Java中不同的资源都要抽象成URL,然后使用不同类型的URLStreamHandler处理不同的URL表示的资源。但是,Spring对其内部使用到的资源实现了自己的抽象结构:Resource接口封装底层资源。主要原因有3点:
- URL没有默认定义相对Classpath或ServletContext等资源的handler
- URL没有提供基本的方法,例如检查当前资源是否存在是否可读等
- 自定义URL handler需要了解URL实现机制
对不同来源的资源文件都有相应的Resource实现:文件(FileSystemResource)、Classpath资源(ClassPathResource)、URL资源(UrlResource)、InputStream资源(InputStreamResource)、Byte数组(ByteArrayResource)等。
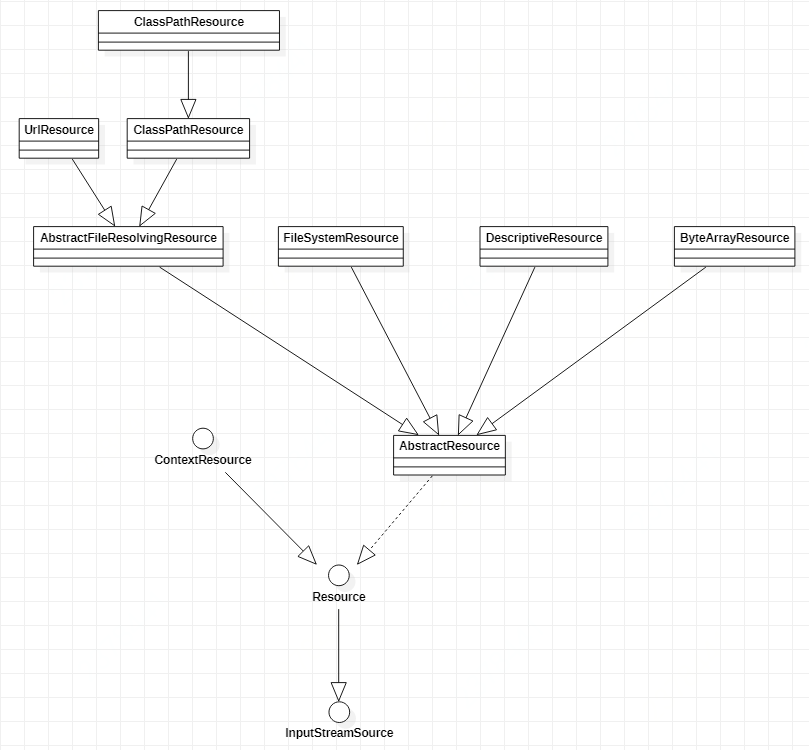
资源文件处理相关类图
2.4 加载BeanDefinition
下面我们就从代码层次看看整个容器究竟是怎么实现的。观察测试代码,我们可以将XmlBeanFactory的构造方法作为切入点进行分析。
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
// 加载BeanDefinition
this.reader.loadBeanDefinitions(resource);
}主要做了两件事,一是调用父类的构造方法,二是加载BeanDefinition。
首先我们先进入父类构造方法,最终进到AbstractAutowireCapableBeanFactory构造方法中。
public AbstractAutowireCapableBeanFactory() {
super();
// 忽略BeanNameAware、BeanFactoryAware和BeanClassLoaderAware接口的自动装配功能
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
}主要是ignoreDependencyInterface方法,它的主要功能是忽略给定接口的自动装配功能。实现上很简单,就是把这些Class加入到ignoredDependencyInterfaces集合中,ignoredDependencyInterfaces是Set>类型。
再看加载Bean的方法,执行的是XmlBeanDefinitionReader类的loadBeanDefinitions方法。进入方法,可以看到主要就是做了两件事,一是构造InputSource,这个类全路径名是org.xml.sax.InputSource,这步的目的就是通过SAX读取XML文件事先准备一下InputSource对象。而真正的加载Bean的逻辑在doLoadBeanDefinitions方法中。
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
InputStream inputStream = encodedResource.getResource().getInputStream();
// 构建InputSource,用于解析XML
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 实际加载BeanDefinition的执行逻辑
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}doLoadBeanDefinitions方法首先加载XML文件,得到Document对象,然后根据Document对象注册Bean。我们首先看下得到Document对象的过程。
2.5 获取Document
获取Document,首先通过getValidationModeForResource获取XML验证模式,然后解析得到Document对象。
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
// 首先获取XML验证模式,然后SAX方式解析得到Document
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}常用的XML验证模式有两种:DTD和XSD,实际使用哪种验证模式在getValidationModeForResource中进行了解析。这个方法判断是DTD验证还是XSD验证,仅仅是判断一下XML是否包含DOCTYPE字符串。
而解析得到Document的方法很简单,就是通过SAX解析XML文档的套路。这里不再赘述。
2.6 解析及注册BeanDefinition
当把文件转换为Document后,接下来的提取及注册bean就是我们的重头戏了。调用了以下方法。
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
// 注册BeanDefinition
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}在这个方法中很好地应用了单一职责原则,将逻辑处理委托给单一的类进行处理,而这个逻辑处理类就是BeanDefinitionDocumentReader。BeanDefinitionDocumentReader是一个接口,实例化的工作在createBeanDefinitionDocumentReader()中完成,真正的类型是DefaultBeanDefinitionDocumentReader。而它的registerBeanDefinitions方法很简单,仅仅是先根据Document获取了root,实际注册在doRegisterBeanDefinitions方法中。
protected void doRegisterBeanDefinitions(Element root) {
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// 如果环境变量不包含指定profile,则流程结束
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
return;
}
}
}
preProcessXml(root);
// 解析BeanDefinition
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
}注册过程首先对profile进行处理,如果是环境变量定义的则进行处理,否则不进行处理。然后就是解析bean。这里调用了preProcessXml(root)和postProcessXml(root)两个方法,但是发现这两个方法是空方法。这里应用了模板方法模式。如果继承自DefaultBeanDefinitionDocumentReader的子类需要在Bean解析前后做一些处理的话,只需要重写这两个方法即可。
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
// 根元素是默认命名空间
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
// 如果元素是默认命名空间,则按默认方式解析元素
parseDefaultElement(ele, delegate);
}
else {
// 如果这个元素是自定义命名空间,则按自定义方式解析元素
delegate.parseCustomElement(ele);
}
}
}
}
else {
// 如果根元素是自定义命名空间,则按自定义方式解析元素
delegate.parseCustomElement(root);
}
}而解析bean需要判断元素是否是默认命名空间,如果是则调用parseDefaultElement(ele, delegate)方法,不是则调用delegate.parseCustomElement(ele)方法。判断是否是默认命名空间,调用isDefaultNamespace方法,元素或者节点的命名空间与Spring中固定的命名空间http://www.springframework.org/schema/beans进行对比,一致则认为是默认的,否则就认为是自定义的。
2.7 默认标签的解析
默认标签的解析逻辑一目了然,分别对4种不同标签(import、alias、bean和beans)做了不同的处理。
2.7.1 bean标签的解析及注册
对bean标签的解析是通过processBeanDefinition(ele, delegate)方法进行的。大致逻辑总结如下:
- 首先委托BeanDefinitionDelegate类的parseBeanDefinitionElement方法进行元素解析,返回BeanDefinitionHolder类型的实例bdHolder,经过这个方法后,bdHolder实例已经包含我们配置文件中配置的各种属性了,例如class、name、id、alias等属性。
- 如果bdHolder不为空,若存在默认标签的子节点下再有自定义属性,还需要再次对自定义标签进行解析。
- 解析后,对bdHolder进行注册。注册操作委托给了BeanDefinitionReaderUtils的registerBeanDefinition方法。
- 发出响应事件,通知相关监听器,这个bean已经加载完了。
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 解析元素信息,用bdHolder封装
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
// 如果标签下有自定义属性,则对自定义属性进行解析
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
// 对bdHolder进行注册
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
// 发送注册事件给监听器.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}1)元素解析及信息提取
首先我们从元素解析及信息提取开始:delegate.parseBeanDefinitionElement(ele)。进入BeanDefinitionParserDelegate类parseBeanDefinitionElement方法,主要完成如下内容:
- 提取元素的id和name属性
- 解析其他所有属性,封装到GenericBeanDefinition类型的实例中,对应this.parseBeanDefinitionElement(ele, beanName, containingBean)方法
- 如果bean没有指定beanName,则使用默认规则为此Bean生成beanName
- 将获取到的信息封装到BeanDefinitionHolder实例中
beanName取值策略是,首先取id,如果没有指定id则取name[0](因为name可以指定多个),如果name也没有指定,则采取自动生成方式生成。
最终bean元素的所有属性和子元素信息都保存到GenericBeanDefinition中了。至此就完成了XML文档到GenericBeanDefinition的转换。
2)默认标签中自定义标签元素的解析
如果这个bean使用的是默认的标签配置,但是其中的子元素却使用了自定义配置,这时这部分内容就起作用了。入口是delegate.decorateBeanDefinitionIfRequired(ele, bdHolder)方法。它分别对元素的所有属性和子元素进行了decorateIfRequired方法的调用。decorateIfRequired方法会判断,如果是自定义节点,则找出自定义类型所对应的NamespaceHandler并进行进一步解析。
public BeanDefinitionHolder decorateIfRequired(
Node node, BeanDefinitionHolder originalDef, BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(node);
if (!isDefaultNamespace(namespaceUri)) {
// 如果元素是自定义元素,则根据命名空间找到对应的命名空间处理器
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler != null) {
// 自定义命名空间处理器处理bdHolder
return handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
}
}
return originalDef;
}3)BeanDefinition的注册
BeanDefinition注册分为通过beanName注册BeanDefinition和注册别名两部分。进入BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, this.getReaderContext().getRegistry())方法内部,如下
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
String beanName = definitionHolder.getBeanName();
// 通过beanName注册BeanDefinition
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
// 注册别名
registry.registerAlias(beanName, alias);
}
}
}通过beanName注册BeanDefinition主要进行了4个步骤:
- 对AbstractBeanDefinition的校验,主要是对于AbstractBeanDefinition的methodOverrides属性的
- 对于beanName已经注册的情况的处理,如果已经设置了不允许bean的覆盖,会抛出异常,否则进行覆盖
- 加入Map缓存,beanName为key,BeanDefinition为value
- 清除之前留下的对应beanName的缓存
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) {
if (beanDefinition instanceof AbstractBeanDefinition) {
// 对AbstractBeanDefinition的校验
((AbstractBeanDefinition) beanDefinition).validate();
}
BeanDefinition oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
// 如果beanName已经注册,并且设置了不允许bean覆盖,会抛出异常
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
// 将beanDefinition存到Map,beanName为key
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
synchronized (this.beanDefinitionMap) {
// 将beanDefinition存到Map,beanName为key
this.beanDefinitionMap.put(beanName, beanDefinition);
}
}
else {
// 将beanDefinition存到Map,beanName为key
this.beanDefinitionMap.put(beanName, beanDefinition);
}
}
if (oldBeanDefinition != null || containsSingleton(beanName)) {
// 清除之前留下的对应beanName的缓存
resetBeanDefinition(beanName);
}
}注册别名的原理相对简单,分为4个步骤:
- alias和beanName相同情况处理,此时会删除原有的alias
- alias覆盖处理,若aliasName已经使用了并已经指向了另一个beanName,且设置了别名不能覆盖,则会抛出异常
- alias循环检查,如果出现了别名循环的情况,则抛出异常
- 注册alias
public void registerAlias(String name, String alias) {
if (alias.equals(name)) {
this.aliasMap.remove(alias);
} else {
String registeredName = (String)this.aliasMap.get(alias);
if (registeredName != null) {
if (registeredName.equals(name)) {
return;
}
// 若aliasName已经使用了并已经指向了另一个beanName,且设置了别名不能覆盖,则会抛出异常
if (!this.allowAliasOverriding()) {
throw new IllegalStateException("Cannot register alias '" + alias + "' for name '" + name + "': It is already registered for name '" + registeredName + "'.");
}
}
// alias循环检查
this.checkForAliasCircle(name, alias);
// alias注册
this.aliasMap.put(alias, name);
}
}4)通知监听器解析及注册完成
通过代码this.getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder))完成此功能。这里的实现只是为了扩展,当需要对注册BeanDefinition事件进行监听时可以通过注册监听器的方式并将处理逻辑写入监听器中,目前Spring没有对此事件进行任何处理。
2.7.2 alias标签的解析
对alias标签的解析是通过processAliasRegistration(ele)方法处理的。
protected void processAliasRegistration(Element ele) {
String name = ele.getAttribute(NAME_ATTRIBUTE);
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
boolean valid = true;
if (!StringUtils.hasText(name)) {
valid = false;
}
if (!StringUtils.hasText(alias)) {
valid = false;
}
if (valid) {
// alias标签解析
getReaderContext().getRegistry().registerAlias(name, alias);
// 通知监听器
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
}
}进入方法内部可以看到,this.getReaderContext().getRegistry().registerAlias(name, alias)方法实现了alias标签的解析,而这个方法实际就是前面注册别名的那个方法。this.getReaderContext().fireAliasRegistered(name, alias, this.extractSource(ele))这个方法用于在别名注册后通知监听器做相应的处理,这里的实现只是为了扩展,目前Spring没有对此事件进行任何处理。
2.7.3 import标签的解析
对import标签的解析,Spring大致分为以下步骤:
- 获取import标签的resource属性配置的路径
- 解析路径中的系统属性,格式如“${user.dir}”,对应方法this.getReaderContext().getEnvironment().resolveRequiredPlaceholders(location)
- 判断resource属性配置的路径是绝对路径还是相对路径
- 如果是绝对路径,则调用bean的解析过程进行解析
- 如果是相对路径则计算出绝对路径后进行解析
- 通知监听器,解析完成
不管是绝对路径下import标签的解析还是相对路径下import标签的解析,通过跟踪代码发现,最后都会调到XmlBeanDefinitionReader类的loadBeanDefinitions方法,而这个方法在加载bean部分已经了解了。
2.7.4 嵌入式beans标签的解析
该标签解析调用的是DefaultBeanDefinitionDocumentReader的doRegisterBeanDefinitions方法,而这个方法已经在解析及注册BeanDefinitions部分了解了。嵌入式beans标签和非嵌入式beans标签的解析过程其实是一样的。
2.8 自定义标签的解析
自定义标签非常有用,我们熟知的标签就是采用自定义标签的原理实现的。下面来探究一下自定义标签的解析原理。
前面提到过解析自定义标签的入口,查看以下具体实现:
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
String namespaceUri = this.getNamespaceURI(ele);
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
return null;
} else {
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
}这里传入的containingBd为null。可以看到自定义标签解析的思路特别简单。无非是根据标签元素获取对应的命名空间,根据命名空间解析对应的处理器,然后根据用户自定义的处理器进行解析。
2.8.1 解析自定义标签处理器
通过元素可以获取它的命名空间,有了命名空间就可以进行NamespaceHandler提取了。在readerContext初始化的时候其属性namespaceHandlerResolver被初始化为DefaultNamespaceHandlerResolver的实例。所以调用resolve方法实际调用的是DefaultNamespaceHandlerResolver的方法。
public NamespaceHandler resolve(String namespaceUri) {
// 获取命名空间到处理器的映射关系
Map<String, Object> handlerMappings = getHandlerMappings();
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
}
else {
String className = (String) handlerOrClassName;
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
// 实例化命名空间处理器
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
namespaceHandler.init();
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}
}
private Map<String, Object> getHandlerMappings() {
if (this.handlerMappings == null) {
synchronized (this) {
if (this.handlerMappings == null) {
// 加载配置文件META-INF/spring.handlers
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
Map<String, Object> handlerMappings = new ConcurrentHashMap<String, Object>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
this.handlerMappings = handlerMappings;
}
}
}
return this.handlerMappings;
}可以看到自定义标签处理器的解析流程,首先通过this.getHandlerMappings()方法解析配置文件获取命名空间到处理器的映射关系,Map保存。然后实例化该命名空间处理器,调用init()初始化方法。而定义的this.handlerMappingsLocation变量在调用构造方法的时候代码写死了,是META-INF/spring.handlers。这个配置文件是用户自己去编写的,定义命名空间到处理器类的映射。命名空间处理器类的实现也是需要用户去实现,用户可以继承NamespaceHandlerSupport抽象类实现一下init()抽象方法。
2.8.2 标签解析
我们已经得到了由哪个标签处理器进行处理,接下来标签解析由handler.parse(ele, new ParserContext(this.readerContext, this, containingBd))去实现。
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 获取元素解析器,进行解析
return findParserForElement(element, parserContext).parse(element, parserContext);
}
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
// 根据节点名称获取parser
String localName = parserContext.getDelegate().getLocalName(element);
BeanDefinitionParser parser = this.parsers.get(localName);
return parser;
}在父类NamespaceHandlerSupport中可以看到,解析功能首先找到解析器,然后进行解析。查找解析器首先获取节点名称,然后通过Map parsers获取对应节点的解析器。而这个Map的赋值一般在用户实现的命名空间处理器init()方法中调用。
而自定义标签的解析任务由parse方法完成。可以看到,首先通过parseInternal方法将标签元素转换成了BeanDefinition,然后解析id和name属性并用BeanDefinitionHolder封装元素信息,接着进行BeanDefinition的注册,最后通知监听器。
public final BeanDefinition parse(Element element, ParserContext parserContext) {
// 解析元素
AbstractBeanDefinition definition = this.parseInternal(element, parserContext);
if (definition != null && !parserContext.isNested()) {
// 解析id
String id = this.resolveId(element, definition, parserContext);
String[] aliases = null;
if (this.shouldParseNameAsAliases()) {
// 解析name
String name = element.getAttribute("name");
if (StringUtils.hasLength(name)) {
aliases = StringUtils.trimArrayElements(StringUtils.commaDelimitedListToStringArray(name));
}
}
// holder封装元素信息
BeanDefinitionHolder holder = new BeanDefinitionHolder(definition, id, aliases);
// 注册
this.registerBeanDefinition(holder, parserContext.getRegistry());
if (this.shouldFireEvents()) {
BeanComponentDefinition componentDefinition = new BeanComponentDefinition(holder);
this.postProcessComponentDefinition(componentDefinition);
// 通知监听器
parserContext.registerComponent(componentDefinition);
}
}
return definition;
}对于后面三步前面都介绍过了,只需看下parseInternal方法逻辑。
protected final AbstractBeanDefinition parseInternal(Element element, ParserContext parserContext) {
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();
// 解析parentName
String parentName = this.getParentName(element);
if (parentName != null) {
builder.getRawBeanDefinition().setParentName(parentName);
}
// 解析beanClass
Class<?> beanClass = this.getBeanClass(element);
if (beanClass != null) {
builder.getRawBeanDefinition().setBeanClass(beanClass);
} else {
String beanClassName = this.getBeanClassName(element);
if (beanClassName != null) {
builder.getRawBeanDefinition().setBeanClassName(beanClassName);
}
}
// 解析source
builder.getRawBeanDefinition().setSource(parserContext.extractSource(element));
if (parserContext.isNested()) {
builder.setScope(parserContext.getContainingBeanDefinition().getScope());
}
// 解析lazyInit
if (parserContext.isDefaultLazyInit()) {
builder.setLazyInit(true);
}
this.doParse(element, parserContext, builder);
return builder.getBeanDefinition();
}
protected void doParse(Element element, ParserContext parserContext, BeanDefinitionBuilder builder) {
this.doParse(element, builder);
}
protected void doParse(Element element, BeanDefinitionBuilder builder) {
}可以看到,parseInternal方法实际就是先解析parentName、beanClass、source、scope和lazyInit,以BeanDefinition封装。然后调用doParse方法,这个方法也是用户自定义解析器需要实现的方法。最后返回这个BeanDefinition。
3 总结
至此,我们一步一步地分析了Spring容器创建基本原理的所有内容。没想到短短一句new XmlBeanFactory(new ClassPathResource(“beanFactoryTest.xml”)),Spring做了这么多事:配置文件的封装、Document获取和解析及注册BeanDefinition等。解析及注册BeanDefinition对默认标签和自定义标签进行不同的处理。对于默认标签,又分别对bean标签、alias标签、import标签和beans标签进行不同的处理。其中bean标签解析逻辑最为复杂也最为基础,而剩下的那几个标签又复用了bean标签处理的部分逻辑。
我们从中不仅可以学到Spring容器创建的基本原理,还可以学到许多编码规范及技巧,了解到好的代码是什么样子的。比如其中应用到的单一职责原则、模板方法模式等等。而且还可以发现,它的代码逻辑很清晰,往往通过它的方法名称就知道这个方法的功能,并且每个方法也不会特别长,增加了代码的可读性和可维护性。并且代码封装性很好,很多复杂的功能代码都可以复用。
在我们之后的开发工作中需要不断学习好的编码技巧及规范,应用到日常开发工作当中,最终形成我们自己的编码技巧及风格。
4 参考资料
《Spring技术内幕:深入解析Spring架构与设计原理》
《Spring源码深度解析》
作者:曹铭






