

摘要:本文由社区用户 xrfinbj 贡献,主要介绍 Exchange 工具从 Hive 数仓导入数据到 Nebula Graph 的流程及相关的注意事项。
1 背景
公司内部有使用图数据库的场景,内部通过技术选型确定了 Nebula Graph 图数据库,还需要验证 Nebula Graph 数据库在实际业务场景下的查询性能。所以急迫的需要导入数据到 Nebula Graph 并验证。在这个过程中发现通过 Exchange 工具从 hive 数仓导入数据到 Nebula Graph 文档不是很全,所以把这个流程中踩到的坑记录下来,回馈社区,避免后人走弯路。
本文主要基于我之前发在论坛的 2 篇帖子:
2 环境信息
- Nebula Graph 版本:nebula:nightly
- 部署方式(分布式 / 单机 / Docker / DBaaS):Mac 电脑 Docker 部署
- 硬件信息
- 磁盘(SSD / HDD):Mac 电脑 SSD
- CPU、内存信息:16 G
- 数仓环境(Mac 电脑搭建的本地数仓):
- Hive 3.1.2
- Hadoop 3.2.1
- Exchange 工具:https://github.com/vesoft-inc/nebula-java/tree/v1.0/tools/exchange
编译后生成 jar 包
- Spark spark-2.4.7-bin-hadoop2.7 (conf 目录下配置 Hadoop 3.2.1 对应的 core-site.xml,hdfs-site.xml,hive-site.xml 设置 spark-env.sh) Scala code runner version 2.13.3 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
3 配置
1 Nebula Graph DDL
CREATE SPACE test_hive(partition_num=10, replica_factor=1); --创建图空间,本示例中假设只需要一个副本
USE test_hive; --选择图空间 test
CREATE TAG tagA(idInt int, idString string, tboolean bool, tdouble double); -- 创建标签 tagA
CREATE TAG tagB(idInt int, idString string, tboolean bool, tdouble double); -- 创建标签 tagB
CREATE EDGE edgeAB(idInt int, idString string, tboolean bool, tdouble double); -- 创建边类型 edgeAB
2 Hive DDL
CREATE TABLE `tagA`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagA select 1,1,'str1',true,11.11;
insert into tagA select 2,2,"str2",false,22.22;
CREATE TABLE `tagB`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagB select 3,3,"str 3",true,33.33;
insert into tagB select 4,4,"str 4",false,44.44;
CREATE TABLE `edgeAB`(
`id_source` bigint,
`id_dst` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into edgeAB select 1,3,5,"edge 1",true,55.55;
insert into edgeAB select 2,4,6,"edge 2",false,66.66;
3 我的最新 nebula_application.conf 文件
注意看exec、fields、nebula.fields、vertex、source、target字段映射
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 4
}
}
# Nebula Graph relation config
nebula: {
address:{
graph: ["192.168.1.110:3699"]
meta: ["192.168.1.110:45500"]
}
user: user
pswd: password
space: test_hive
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/error
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
tags: [
# Loading from Hive
{
name: tagA
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.taga"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 10
}
{
name: tagB
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.tagb"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 10
}
]
# Processing edges
edges: [
# Loading from Hive
{
name: edgeAB
type: {
source: hive
sink: client
}
exec: "select id_source,id_dst,idint,idstring,tboolean,tdouble from nebula.edgeab"
fields: [id_source,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
source: id_source
target: id_dst
batch: 256
partition: 10
}
]
}
4 执行导入
4.1 确保 nebula 服务启动
4.2 确保 Hive 表和数据就绪
4.3 执行 spark-sql cli 查看 Hive 表以及数据是否正常以确保 Spark 环境没问题
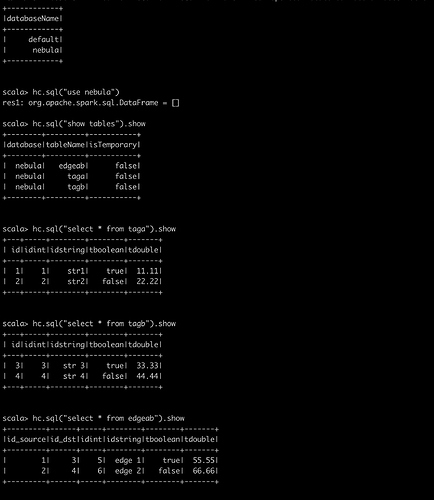
4.4 一切配置工作就绪后,执行 Spark 命令:
spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master “local[4]” /xxx/exchange-1.0.1.jar -c /xxx/nebula_application.conf -h
4.5 导入成功后 可以借助 db_dump 工具查看导入数据量 验证正确性
./db_dump --mode=stat --space=xxx --db_path=/home/xxx/data/storage0/nebula --limit 20000000
5 踩坑以及说明
- 第一个坑就是 spark-submit 命令没有加 -h 参数
- Nebula Graph 中 tagName 是大小写敏感的,tags 的配置中 name 配置的应该是 Nebula Graph 的 tag 名
- Hive的 int 和 Nebula Graph 的 int 不一致,Hive 里面的 bigint 对应 Nebula Graph 的 int
其他说明:
- 由于 Nebula Graph 底层存储是 kv,重复插入其实是覆盖,update 操作用 insert 替代性能会高些
- 文档里面不全的地方可能暂时只有一边看源码解决,一边去论坛问(开发同学也不容易又要紧张的开发又要回答用户的疑问)
- 导入数据、Compact 以及操作建议:https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact/
- 我已经验证如下两个场景:
- 用 Spark 2.4 从 Hive 2(Hadoop 2)中导入数据到 Nebula Graph
- 用 Spark 2.4 从 Hive3(Hadoop 3)中导入数据到 Nebula Graph
说明:Exchange 目前还不支持 Spark 3,编译后运行报错,所以没法验证 Spark 3 环境
还有一些疑问
- nebula_application.conf 文件的参数 batch 和 rate.limit 应该如何设置?参数如何抉择?
- Exchange 工具 Hive 数据导入原理(Spark 这块我也是最近现学现用)
6 Exchange 源码 Debug
Spark Debug 部分参考博客:https://dzone.com/articles/how-to-attach-a-debugger-to-apache-spark
通过 Exchange 源码的学习和 Debug 能加深对 Exchange 原理的理解,同时也能发现一些文档描述不清晰的地方,比如 导入 SST 文件 和 Download and Ingest 只有结合源码看才能发现文档描述不清晰逻辑不严谨的问题。
通过源码 Debug 也能发现一些简单的参数配置问题。
进入正题:
步骤一:
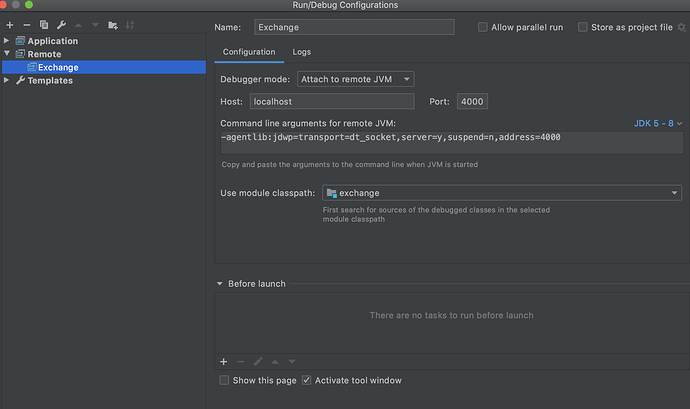
export SPARK_SUBMIT_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=4000
步骤二:
spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master “local” /xxx/exchange-1.1.0.jar -c /xxx/nebula_application.conf -h
Listening for transport dt_socket at address: 4000
步骤三:IDEA 配置
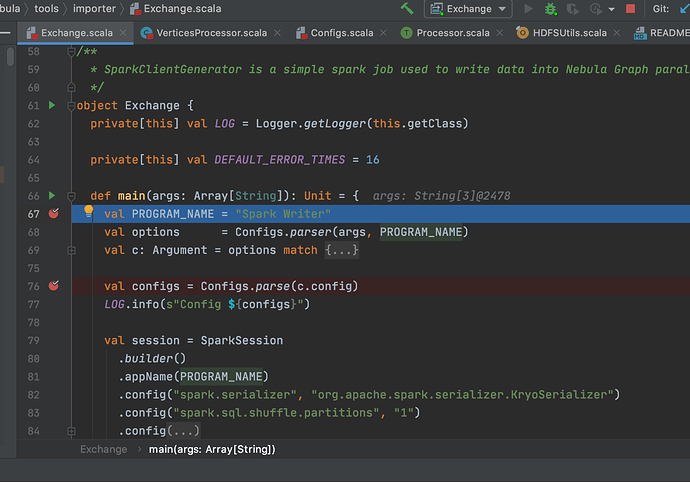
步骤四:在 IDEA 里面点击 Debug
7 建议与感谢
感谢 vesoft 提供了宇宙性能最强的 Nebula Graph 图数据库,能解决业务中很多实际问题,中途这点痛不算什么(看之前的分享,360 数科他们那个痛才是真痛)。中途遇到的问题都有幸得到社区及时的反馈解答,再次感谢
很期待 Exchange 支持 Nebula Graph 2.0
参考资料
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?交个朋友,Nebula Graph 官方小助手微信:NebulaGraphbot 拉你进交流群~~











