
一、Elasticsearch
Elasticsearch是一个基于Apache Lucene的开源的实时分布式搜索和分析引擎。
1. 分布式
- 低成本,高可用,高效
- 配置简单,轻松搭建集群,易扩展
2. 实时
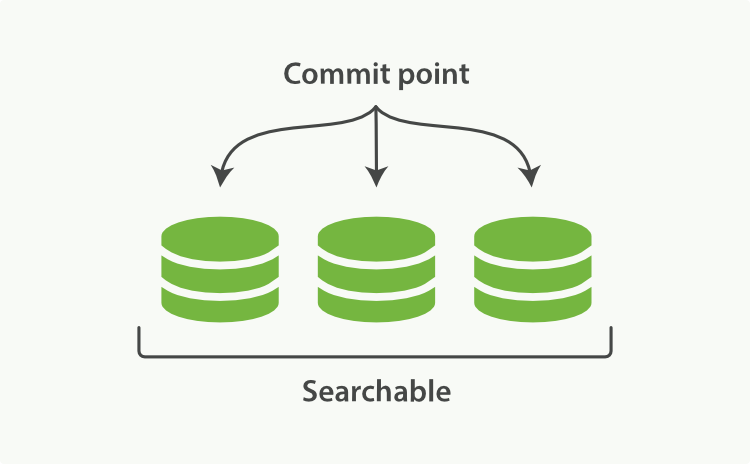
- 当前索引有 3 个文档可用
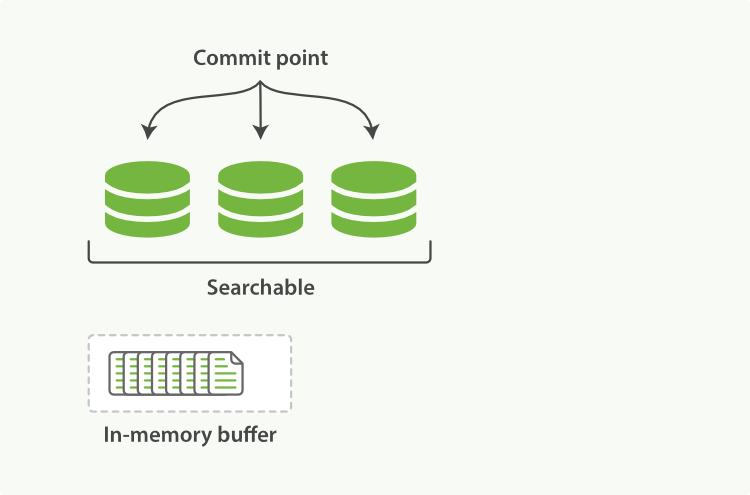
- 新加入一个文档,数据先进入内存buffer
- 内存buffer刷到文件系统缓存中(默认这个时间需要1s),此时新文档已经被索引,可以搜索
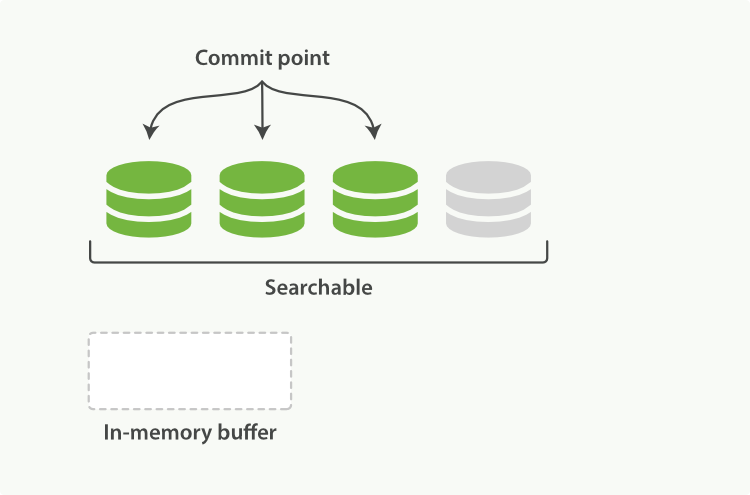
- 文件系统缓存写入磁盘,更新commit文件
3. 分析
提供各种丰富的查询子句,不仅可以实现全文检索,更能对海量数据进行聚合分析。
二、elasticsearch基本概念
1. 索引
索引(indexing) 在Elasticsearch中存储数据的行为
倒排索引(inverted index) Elasticsearch中存储数据的数据结构,加速文档检索
Doc0:"it is what it is" Doc1:"what is it" Doc2:"it is a banana"反向文件索引
"a": {2} "banana": {2} "is": {0, 1, 2} "it": {0, 1, 2} "what": {0, 1}完全反向索引
"a": {(2, 2)} "banana": {(2, 3)} "is": {(0, 1), (0, 4), (1, 1), (2, 1)} "it": {(0, 0), (0, 3), (1, 2), (2, 0)} "what": {(0, 2), (1, 0)}索引(index) 相关文档存储的地方,等同于传统关系数据库中的数据库概念
2. 类型(type)
类型存在于索引(index)中,等同于传统关系数据库中的表概念
3. 文档(document)
文档归属于一种类型(type),等同于传统关系数据库中的行概念
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
Elasticsearch集群可以包含多个索引(indices)(数据库),
每一个索引可以包含多个类型(types)(表),
每一个类型包含多个文档(documents)(行),
然后每个文档包含多个字段(Fields)(列)。
4. 分片
存储文档数据的容器,被均匀的分配到各个节点,保证索引和搜索的负载均衡。







