1. MySQL持久化数据,Redis只读数据
redis在启动之后,从数据库加载数据。
读请求:
不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取
写请求:
数据首先都写到数据库,之后更新redis(先写redis再写mysql,如果写入失败事务回滚会造成redis中存在脏数据)
2.MySQL和Redis处理不同的数据类型
MySQL处理实时性数据,例如金融数据、交易数据
Redis处理实时性要求不高的数据,例如网站最热贴排行榜,好友列表等
在并发不高的情况下,读操作优先读取redis,不存在的话就去访问MySQL,并把读到的数据写回Redis中;写操作的话,直接写MySQL,成功后再写入Redis(可以在MySQL端定义CRUD触发器,在触发CRUD操作后写数据到Redis,也可以在Redis端解析binlog,再做相应的操作)
在并发高的情况下,读操作和上面一样,写操作是异步写,写入Redis后直接返回,然后定期写入MySQL
几个例子:
1.当更新数据时,如更新某商品的库存,当前商品的库存是100,现在要更新为99,先更新数据库更改成99,然后删除缓存,发现删除缓存失败了,这意味着数据库存的是99,而缓存是100,这导致数据库和缓存不一致。
解决方法:
这种情况应该是先删除缓存,然后在更新数据库,如果删除缓存失败,那就不要更新数据库,如果说删除缓存成功,而更新数据库失败,那查询的时候只是从数据库里查了旧的数据而已,这样就能保持数据库与缓存的一致性。
2.在高并发的情况下,如果当删除完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存里没有,就去数据库里查,还是以上面商品库存为例,如果数据库中产品的库存是100,那么查询到的库存是100,然后插入缓存,插入完缓存后,原来那个更新数据库的线程把数据库更新为了99,导致数据库与缓存不一致的情况
解决方法:
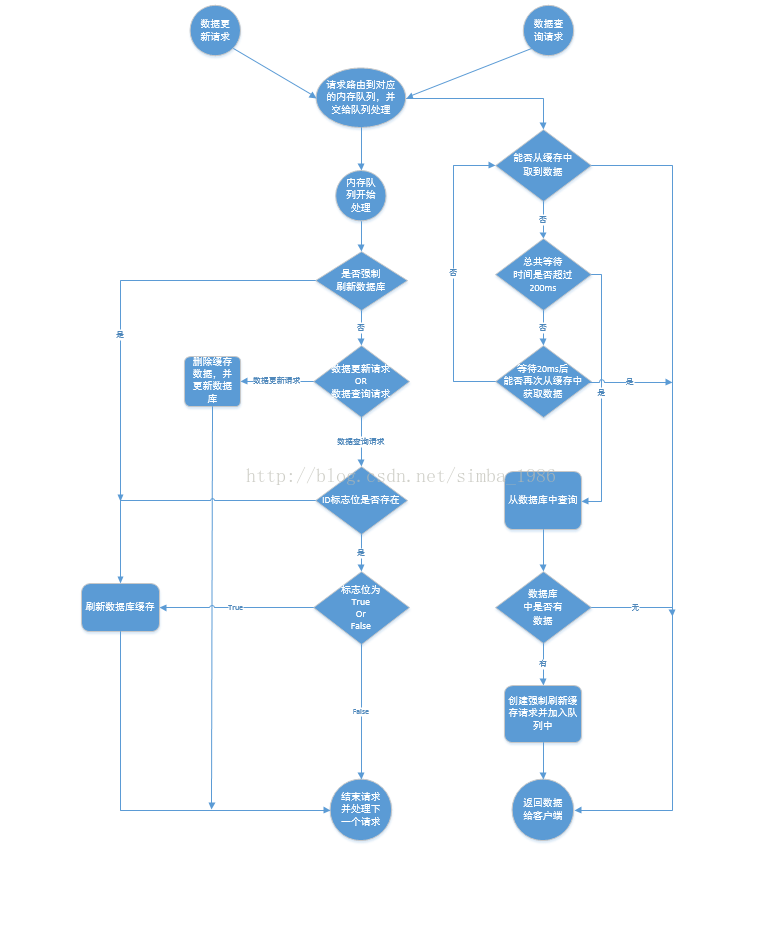
遇到这种情况,可以用队列的去解决这个问,创建几个队列,如20个,根据商品的ID去做hash值,然后对队列个数取摸,当有数据更新请求时,先把它丢到队列里去,当更新完后在从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID在做更新,如果有也把查询的请求发送到队列里去,然后同步等待缓存更新完成。
这里有一个优化点,如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右,如果缓存里还没有则直接取数据库的旧数据,一般情况下是可以取到的。
在高并发下解决场景二要注意的问题:
(1)读请求时长阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时间内返回,该解决方案最大的风险在于可能数据更新很频繁,导致队列中挤压了大量的更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库,像遇到这种情况,一般要做好足够的压力测试,如果压力过大,需要根据实际情况添加机器。
(2)请求并发量过高
这里还是要做好压力测试,多模拟真实场景,并发量在最高的时候QPS多少,扛不住就要多加机器,还有就是做好读写比例是多少
(3)多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过nginx服务器路由到相同的服务实例上
(4)热点商品的路由问题,导致请求的倾斜
某些商品的读请求特别高,全部打到了相同的机器的相同丢列里了,可能造成某台服务器压力过大,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是很大,但是确实有可能某些服务器的负载会高一些。