
papers地址:https://arxiv.org/pdf/1708.05027.pdf
借用论文开头,目前很多的算法任务都是需要使用category feature,而一般对于category feature处理的方式是经过one hot编码,然后我们有些情况下,category feature 对应取值较多时,如:ID等,one hot 编码后,数据会变得非常的稀疏,不仅给算法带来空间上的复杂度,算法收敛也存在一定的挑战。
为了能解决one hot 编码带来的数据稀疏性的问题,我们往往能想到的是不是通过其他的编码Embeding方式。恰好深度学习的爆发,我们可以通过深度学习构架神经网络对category feature进行embeding。为了介绍该篇论文,主要围绕该篇论文进行介绍一下。论文主要分为四个部分:
第一部分:介绍背景
第二部分:介绍Factorization Machines和DNN
第三部分:介绍NFM网络结构及其原理(本文的重点)
第四部分:实验部分
最后谈谈个人的理解和想法。
1、介绍背景
如上面所述,背景部分主要内容说的现阶段的问题和痛点:
(1)category feature在传统机器学习中处理的方法——one hot编码,而这种编码方式会带来数据的维度暴增和数据的稀疏性。这个会给传统机器学习带来空间复杂度和算法收敛较为困难。
(2)FM的二阶交叉项仅仅是两两之间的交叉特征,对于三阶或者高阶的特征并不能很好的表达。
2、介绍Factorization Machines和DNN
(1)Factorization Machines 因式分解机
因式分解机是在LR的基础之上,增加一个二阶交叉特征。其表达式如下所示:
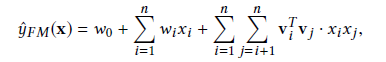
其中,vi和vj是通过矩阵分解的方式得到。
(2)DNN
DNN实际上就会一个全连接的深度神经网络,该网络的特点主要是具有一定的层数,层与层之间是全连接的。
3、NFM网络及其原理
(1)NFM的原理和表达式:
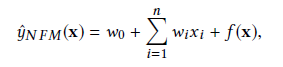
从表达我们可以看出,其基本形式与FM是一致的,区别在于最后一项,NFM使用的是一个f(x)来表示,实际上该f(x)是一个统称,他表示的一个网络的输出。该网络如下所示:
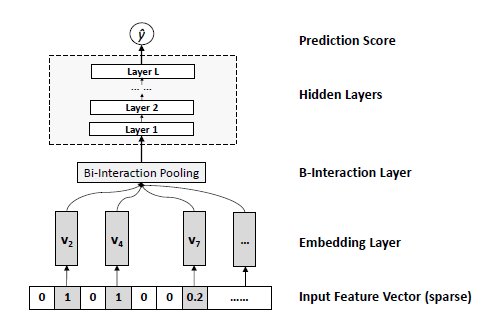
从f(x)的网络结构我们同样可以看出,其主要解决的问题就是二阶交叉项的问题。其结构是:
1)第一层是输入层/,即输入category feature
2)第二层Embeding,对category feature进行编码
3)第三层是二阶交叉项层,该层论文中主要是通过网络得到二阶交叉特征,计算方式:(a+b)^2-a*b 得到二阶交叉项
4)DNN层,该层是通过DNN提取高阶特征
以上就是NFM的基本原理和网络结构。
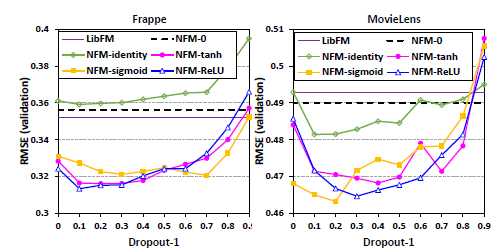
4、实验部分
实验部分主要用了两个数据集,分别如下:

实验结构如下所示:
5、感悟
从该论文内容来看,基本上还是围绕着怎么解决(1)category feature 编码的问题和(2)获取高阶特征,通过神经网络来优化FM,提出了一个NFM的网络结构。论文主要创新点是:
1、Embeding
2、将二阶交叉特征通过DNN提取高阶特征






