
摘要: GaussDB(for MySQL)通过ND算子下推解决存储节点和计算节点之间的传输速度,减少网络开销这个难题。
数据库作为高效稳定处理海量数据交易/分析的坚强数据底座,底层架构设计的重要性不言而喻。
以当前主流的存算分离架构为例,如何提高存储节点和计算节点之间的传输速度,减少网络开销非常关键,GaussDB(for MySQL)就是通过ND算子下推解决了这个难题。
举个例子,当计算和存储分离之后,数据还得从存储节点跨网络到计算节点,计算节点处理完之后再写回存储节点,来来回回好几次,效率很低。
为了提高性能,我们把计算节点的数据处理挪到存储节点。比如有一万个page,a=1的结果只有一两个,发给存储只要一次IO就能完成计算结果,提升整体的查询性能。
除了算子下推之外,GaussDB(for MySQL)还有许多隐藏的黑科技,本篇文章,将从存储层面谈谈华为云自研数据库的技术优势。
华为存储实力加持数据库
华为的存储实力不可小觑,其在数据存储领域的布局已达18年,存储专利超过800件,并在中国区连续16个季度保持市场份额和发货量第一。根据市场机构Gartner发布的2019Q4数据显示,华为存储收入全球排名第四,中国市场连续多年排名第一。在全闪存收入方面,华为存储增长排名第一。
简而言之,在自研数据库方面,华为云相较于其他云厂商,最大的技术优势之一便是多年研发技术积累的存储能力。
毕竟地基稳了,才能造出更好的房子。
而且华为GaussDB数据库全面支持包含鲲鹏和x86在内的多样化算力,且具备从芯片到服务器、存储、操作系统、数据库的E2E研发能力,所以在数据库软硬性能调优方面也占有得天独厚的优势。
也正是得益于领先的存储硬件,华为云自研数据库可以实现算子下推近计算,使得软硬协同性能调优相比友商高出30%,这也是华为全栈软硬件的优势体现,对比之下,其他云数据库大多选择是非自研的存储硬件。

目前,华为已经研发了下一代存储软件架构DFV(数据功能虚拟化/Data Function Virtualisation)。该DFV架构于2018年部署在华为公有云中,开始提供对象服务,之后自研的数据库产品GaussDB系列也用上了DFV存储架构。
DFV的性能亮点很多,比如单个资源池中具备数千个节点,提供EB级别的容量,一个bucket可以保存100亿个对象等等;同时,它可以部署在公有云和私有云上,提供云上云下的统一体验,为GaussDB带来了很多存储上的优势。
GaussDB(for MySQL)架构设计原则
在进入正题之前,先看看GaussDB(for MySQL)架构设计原则:
1.采用华为下一代云存储(DFV)作为快速,可扩展,可靠和共享数据库存储,不复制存储层中的已有功能,例如数据复制,跨AZ可靠性,数据清理。
2.单个数据库集群只需要一份足够可靠的数据库副本集。所有只读副本共享存储在云存储中,甚至跨AZ,数据库中没有逻辑复制。一写多读,没有独立的备用实例。主节点发生故障转移时,只读副本可以切换到接管主服务器。
3.只有数据库日志是通过网络从数据库计算机节点写入 DFV 存储层,基于DFV存储层内的数据库日志重建数据面,以避免繁重的网络流量。
4.基于跨DFV存储节点的切片策略对数据库进行分区,以支持大型数据库卷。单个 DFV 存储节点管理来自不同数据库集群实例的多个分片,实现存储容量和处理能力的无限扩展。
GaussDB(for MySQL)如何在存储架构设计上做到高可靠、高可用
如图所示,GaussDB(for MySQL)自上向下分为3大部分:SQL节点、存储抽象层SAL(Storage Abstract Layer)以及存储层(storage Nodes)。
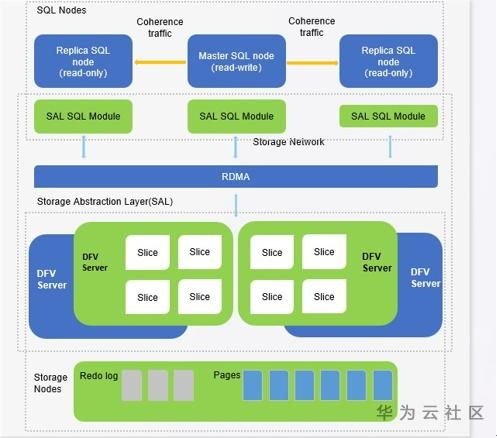
首先,SQL节点形成一个集群,包括一个主节点和多个只读副本(RO最多15个)。每个集群属于一个云租户,一个租户可以具有多个集群。SQL节点管理客户端连接,解析SQL请求,生成查询执行计划,执行查询以及管理事务隔离。
其次是 SAL(存储抽象层),它是SQL节点和存储层之间的桥接器。如下图所示,SAL包括两个主要组件,SAL SQL模块和DFV存储节点内部的Slice存储。
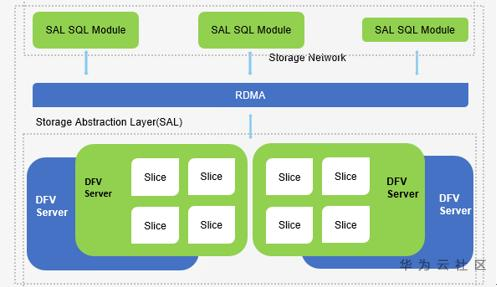
SAL SQL模块为SQL节点(主/只读副本)提供了SAL API,用以与底层存储系统进行交互。 SAL SQL模块包含通用日志处理器CLP(Common Log Processor)、数据库分片管理器SM(Slice Manager)、页面读取器PR(Page Reader)以及与只读副本节点同步信息的工具程序。
其中,CLP负责将数据库全局重做日志持久到DFV,解析日志并将其分发到相应的DFV分片,并生成同步消息(脏页、活动事务列表、分片持久LSN等)以供只读副本获取。CLP还需要处理数据库崩溃恢复,重新加载已提交的全局重做日志,并将其重新分配给所有相应的分片。
SM维护分片策略以及页面映射信息,确定何时添加更多的分片以及哪些数据库页面应分配给哪个DFV切片等。
页面读取器负责通过查找页面映射信息,将特定的页面读取请求路由到相应的切片管理器。
另外,SAL SQL模块还为SQL节点与存储系统交互提供了其他一些接口,包括定期将日志清除信息(RecycleLSN)传递到数据库片等。
Slice Store是在DFV存储节点内部运行的插件模块,它需要与DFV存储框架一起使用,用以在相同DFV节点上管理多个数据库片,支持多租户资源共享,并将页面的多个版本提供给SQL节点。
对于每个分片,Slice Store使用日志目录作为中心组件来管理重做日志和页面数据。Slice Store的主要职责是:
1)、接收分片重做日志,将其持久化并注册到日志目录中;
2)、接收页面阅读请求并构建特定版本的页面;
3)、垃圾回收和合并日志。
最后,GaussDB(for MySQL)存储层建立在华为云存储DFV持久层之上,DFV持久层为上层SQL节点存储提供读写接口,提供跨地域3AZs之间的数据强一致性和可靠性保证。
GaussDB(for MySQL)使用两种模式实现write-optimized以及read-optimized,分别是Plog模式与iShard模式。Plog模式提供强一致性保证,而iShard模式实现最终的一致性。
其中,SQL节点使用Plog模式存储整个数据库的WAL重做日志,使用iShard模式对数据在多个存储节点之间进行分片和管理。Plog以SSD友好的追加写方式使事务提交更快。
iShard将redo以页面为单位进行聚合,管理数据分片,实现快速数据读取,并支持超大型数据库(128 TB)。存储层支持多个GaussDB(for MySQL)集群实例,单个存储节点支持多租户数据库分片。部署灵活,可以将Plog和iShard部署在单独的存储池中或共享同一存储池。
在这种体系架构下,整个数据库集群只需一份足够可靠的数据库副本集,极大节约成本。同时,所有只读副本共享云存储中的数据,去除数据库层的复制逻辑。一写多读,没有独立的备用实例,当主节点发生故障,集群进行切换操作时,只读副本可以切换为主节点,接管集群服务。
而且由于只有数据库日志通过网络从数据库计算节点写入 DFV 存储层,没有脏页、逻辑日志和双写的流量,节省了网络资源。
最后
GaussDB(for MySQL)采用的新一代分布式存储系统DFV,节省了资源,极大提升了数据备份、恢复性能。
它将特定计算任务(备份与恢复逻辑)下推到DFV,以便更高效,快速地实现备份、恢复,而上层计算节点专注于业务逻辑处理。在这种模式之下,客户可以通过本地访问数据并直接与第三方存储系统交互,达到高并发、高性能。
另外,GaussDB(for MySQL)的共享存储架构将数据持久化放入新一代存储DFV中,充分保障数据强一致性和0丢失;针对硬件定制上层系统,利用RDMA 网络、NVME SSD等硬件优势,在这些关键技术上整合创新,使得华为云自研数据库的性能有了质的飞跃。
One more thing
华为云在今年的全联接大会也正式发布了GaussDB(for MySQL)的分布式版,采用share nothing架构,融合华为自研分布式SQL引擎和企业级分布式存储DFV双重优势,业务请求通过负载均衡层转发到分布式SQL引擎层,分布式SQL引擎相关的模块对SQL进行解析、分解、路由到各个分片,最后各个分片返回相应结果汇聚返回给用户端。

通过分库分表,GaussDB(for MySQL)分布式版最高支持PB级海量存储,同时通过内部环境测试,纯写TPS可达百万级,QPS可达千万级,整体性能可随分片数的扩展而成线性提升,可满足几乎所有大型企业集团的核心数据库的要求。
目前,华为云GaussDB已在500+大客户中规模商用,遍布金融、政府、电信、能源、交通、物流、电商等行业。在新基建大潮下,华为云数据库会继续以开源开放的姿态,赋能企业,推动国内的数据库生态发展。












