
作者:京东科技 徐宪章
1 什么是超容量扩容
超容量扩容功能,是指预先调度一定数量的工作节点,当业务高峰期或者集群整体负载较高时,可以使应用不必等待集群工作节点扩容,从而迅速完成应用横向扩容。通常情况下HPA、ClusterAutosacler和超容量扩容同时使用以满足负载敏感度高的业务场景。
超容量扩容功能是通过K8S应用优先级设置和ClusterAutosaler共同作用实现的,通过调整低优先级空载应用的数量,使集群已调度资源保持在较高的状态,当其他高优先级应用因为HPA或者手动调整应用分片数量时,可以通过驱逐空载的方式腾空调度资源却保高优先级应用可以在第一时间调度并创建。当空载应用从被驱逐转变为等到状态时,ClusterAutosaler此时对集群机型扩容,确保下次高优先级应用调度时,有足够的空载应用可以被驱逐。
超容量扩容功能的核心为OverprovisionAutoscaler(超容量扩容)和ClusterAutosaler(集群自动扩容),两者都需要通过不断调整参数配置去适配多重业务需求需求。
超容量扩容功能在一定程度上降低了资源使用饱和度,通过增加成本提高了集群和应用的稳定性,实际业务场景中需要根据需求进行取舍并合理配置。
2 什么情况下需要使用超容量扩容
当集群值开启Hpa和Autoscaler时,在发生节点扩容的情况下,应用调度时间通常为4-12分钟,主要取决于创建工作节点资源以及工作节点从加入集群到Ready的总耗时。以下为最佳和最差效率分析
最佳案例场景-4分钟
• 30秒 - 目标指标值更新:30-60秒
• 30秒 - HPA检查指标值:30秒 - >30秒 - HPA检查指标值:30秒 - >
• <2秒 - Pods创建之后进入pending状态<2秒 -Pods创建之后进入pending状态
• <2秒 - CA看到pending状态的pods,之后调用来创建node 1秒<2秒 -CA看到pending状态的pods,之后调用来创建node 1秒
• 3分钟 - cloud provider创建工作节点,之后加入k8s之后等待node变成ready
最糟糕的情况 - 12分钟
• 60 秒 —目标指标值更新
• 30 秒 — HPA检查指标值
• < 2 秒 — Pods创建之后进入pending状态
• < 2 秒 —CA看到pending状态的pods,之后调用来创建node 1秒
• 10 分钟 — cloud provider创建工作节点,之后加入k8s之后等待node变成ready
两种场景下,创建工作节点耗时占比超过75%,如果可以降低或者完全不考虑该时间,将大大提高应用扩容速度,配合超容量扩容功能可以大大增强集群和业务稳定性。超容量扩容主要用于对应用负载敏感度较高的业务场景
大促备战
流计算/实时计算
Devops系统
其他调度频繁的业务场景
3 如何开启超容量扩容
超容量扩容功能以ClusterAutoscaler为基础,配合OverprovisionAutoscaler实现。以京东公有云Kubernetes容器服务为例
3.1 开启ClusterAutoscaler
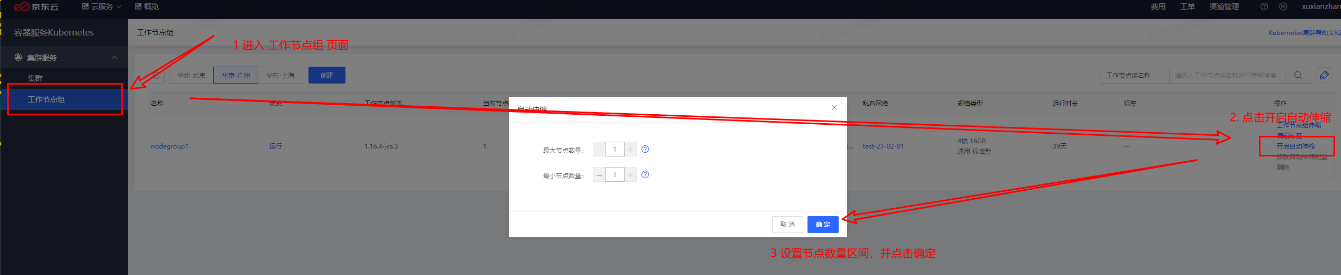
https://cns-console.jdcloud.com/host/nodeGroups/list
• 进入 “kubernetes容器服务”->“工作节点组”
• 选择需要对应节点组,点击开启自动伸缩
• 设置节点数量区间,并点击确定
3.2 部署OverprovisionAutoscaler
1 部署控制器及配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning-autoscaler
namespace: default
labels:
app: overprovisioning-autoscaler
owner: cluster-autoscaler-overprovisioning
spec:
selector:
matchLabels:
app: overprovisioning-autoscaler
owner: cluster-autoscaler-overprovisioning
replicas: 1
template:
metadata:
labels:
app: overprovisioning-autoscaler
owner: cluster-autoscaler-overprovisioning
spec:
serviceAccountName: cluster-proportional-autoscaler
containers:
- image: jdcloud-cn-north-1.jcr.service.jdcloud.com/k8s/cluster-proportional-autoscaler:v1.16.3
name: proportional-autoscaler
command:
- /autoscaler
- --namespace=default
## 注意这里需要根据需要指定上述的configmap的名称
## /overprovisioning-autoscaler-ladder/overprovisioning-autoscaler-linear
- --configmap=overprovisioning-autoscaler-{provision-mode}
## 预热集群应用(类型)/ 名称,基准应用和空值应用需要在同一个命名空间下
- --target=deployment/overprovisioning
- --logtostderr=true
- --v=2
imagePullPolicy: IfNotPresent
volumeMounts:
- name: host-time
mountPath: /etc/localtime
volumes:
- name: host-time
hostPath:
path: /etc/localtime
---
kind: ServiceAccount
apiVersion: v1
metadata:
name: cluster-proportional-autoscaler
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cluster-proportional-autoscaler
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["replicationcontrollers/scale"]
verbs: ["get", "update"]
- apiGroups: ["extensions","apps"]
resources: ["deployments/scale", "replicasets/scale","deployments","replicasets"]
verbs: ["get", "update"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "create"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cluster-proportional-autoscaler
subjects:
- kind: ServiceAccount
name: cluster-proportional-autoscaler
namespace: default
roleRef:
kind: ClusterRole
name: cluster-proportional-autoscaler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
2 部署空载应用
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
namespace: default
labels:
app: overprovisioning
owner: cluster-autoscaler-overprovisioning
spec:
replicas: 1
selector:
matchLabels:
app: overprovisioning
owner: cluster-autoscaler-overprovisioning
template:
metadata:
annotations:
autoscaler.jke.jdcloud.com/overprovisioning: "reserve-pod"
labels:
app: overprovisioning
owner: cluster-autoscaler-overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: reserve-resources
image: jdcloud-cn-east-2.jcr.service.jdcloud.com/k8s/pause-amd64:3.1
resources:
requests:
## 根据预热预期设置配置的分片数量及单分片所需资源
cpu: 7
imagePullPolicy: IfNotPresent
3.3 验证超容量扩容功能是否正常
1 验证Autoscaler
• 查看autoscaler控制器是否Running
• 不断创建测试应用,应用需求资源略微小于节点组单节点可调度资源
• 观察集群节点状态,当资源不足导致pod 等待中状态时,autocalser是否会按照预设(扩容等待、扩容冷却、最大节点数量等)进行扩容
• 开启集群自动缩容,删除测试应用,观察集群节点资源Request到达阈值后是否发生缩容。
2 验证OverprovisionAutoscaler
• 查看OverprovisionAutoscaler控制器是否Running
• 不断创建测试应用,当发生autoscaler后,空载应用数量是否会根据配置发生变化
• 当业务应用pendding后,空载应用是否会发生驱逐,并调度业务应用
4 设置OverprovisionAutoscaler及ClusterAutoscaler参数
4.1 配置ClusterAutoscaler
1 ca参数说明
| 参数名称 | 默认值 | 参数说明 | | scan_interval | 20s | How often cluster is reevaluated for scale up or down | | max_nodes_total | 0 | Maximum number of nodes in all node groups | | estimator | binpacking | Type of resource estimator to be used in scale up. | | expander | least-waste | Type of node group expander to be used in scale up | | max_empty_bulk_delete | 15 | Maximum number of empty nodes that can be deleted at the same time | | max_graceful_termination_sec | 600 | Maximum number of seconds CA waits for pod termination when trying to scale down a node | | max_total_unready_percentage | 45 | Maximum percentage of unready nodes in the cluster. After this is exceeded, CA halts operations | | ok_total_unready_count | 100 | Number of allowed unready nodes, irrespective of max-total-unready-percentage | | max_node_provision_time | 900s | Maximum time CA waits for node to be provisioned | | scale_down_enabled | true | Should CA scale down the cluster | | scale_down_delay_after_add | 600s | How long after scale up that scale down evaluation resumes | | scale_down_delay_after_delete | 10s | How long after node deletion that scale down evaluation resumes, defaults to scanInterval | | scale_down_delay_after_failure | 180s | How long after scale down failure that scale down evaluation resumes | | scale_down_unneeded_time | 600s | How long a node should be unneeded before it is eligible for scale down | | scale_down_unready_time | 1200s | How long an unready node should be unneeded before it is eligible for scale down | | scale_down_utilization_threshold | 0.5 | Node utilization level, defined as sum of requested resources divided by capacity, below which a node can be considered for scale down | | balance_similar_node_groups | false | Detect similar node groups and balance the number of nodes between them | | node_autoprovisioning_enabled | false | Should CA autoprovision node groups when needed | | max_autoprovisioned_node_group_count | 15 | The maximum number of autoprovisioned groups in the cluster | | skip_nodes_with_system_pods | true | If true cluster autoscaler will never delete nodes with pods from kube-system (except for DaemonSet or mirror pods) | | skip_nodes_with_local_storage | true | If true cluster autoscaler will never delete nodes with pods with local storage, e.g. EmptyDir or HostPath', NOW(), NOW(), 1); |
2 推荐配置
# 其他保持默认
scan_interval=10s
max_node_provision_time=180s
scale_down_delay_after_add=180s
scale_down_delay_after_delete=180s
scale_down_unneeded_time=300s
scale_down_utilization_threshold=0.4
4.2 配置OverprovisionAutoscaler
OverprovisionAutoscaler的配置有线性配置和阶梯配置两种方式,两种配置方式只能选择一种.
1 线性配置(ladder)
线性配置,通过配置总体CPU核数以及节点数量和空载应用数量的比例实现线性资源预留,空载应用数量总是和CPU总量以及节点数量成正比,精度会根据空载应用CPU资源request变化,request值越小,精度月高,当配置发生冲突时,取符合线性关系的空载应用数量最大值.
节点数量满足配置中min和max的区间
preventSinglePointFailure,当为true时,Running状态的空载应用分片数满足线性关系;当为false时,Failer/Running状态的空载应用分片数满足线性关系
includeUnschedulableNodes,是否考虑不可调度节点
kind: ConfigMap
apiVersion: v1
metadata:
name: overprovisioning-autoscaler-linear
namespace: default
data:
linear: |-
{
"coresPerReplica": 2,
"nodesPerReplica": 1,
"min": 1,
"max": 100,
"includeUnschedulableNodes": false,
"preventSinglePointFailure": true
}
2 阶梯配置(linear)
阶梯配置,通过配置总体CPU核数或者节点数量和空载应用数量的矩阵实现阶梯状资源预留,空载应用数量符合CPU总量以及节点数量的分布状态,当配置发生冲突时,取符合区间分布的空载应用数量最大值
kind: ConfigMap
apiVersion: v1
metadata:
name: overprovisioning-autoscaler-ladder
namespace: default
data:
ladder: |-
{
"coresToReplicas":
[
[ 1,1 ],
[ 50,3 ],
[ 200,5 ],
[ 500,7 ]
],
"nodesToReplicas":
[
[ 1,1 ],
[ 3,4 ],
[ 10,5 ],
[ 50,20 ],
[ 100,120 ],
[ 150,120 ]
]
}






