
本文源码:GitHub·点这里 || GitEE·点这里
一、MySQL逻辑架构
1、逻辑架构图
基于下面的逻辑架构图,可以大致熟悉MySQL各个架构组件之间的协同工作关系。
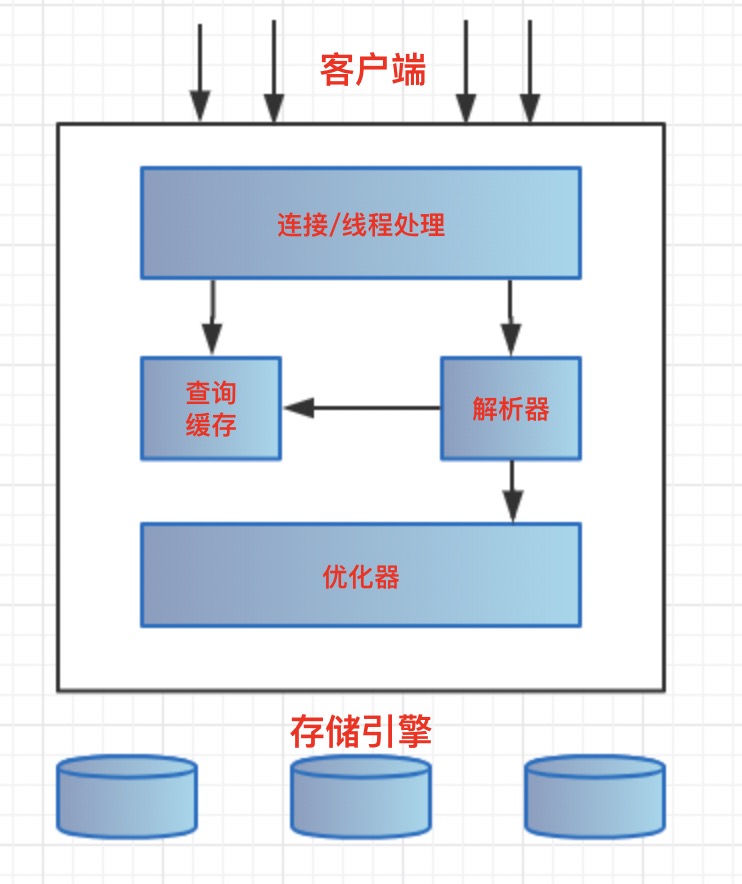
很经典的C/S架构风格,即客户端/服务端模式。
2、分层描述
- 客户端连接
通常会进行连接池管理,连接用户权限认证,安全管理等操作。
可以通过如下命令查看连接配置信息:SHOW VARIABLES LIKE '%connect%';可以看到最大连接和每个连接占用的内存等相关配置。
- 核心功能
第二层架构封装MySQL一系列核心操作,查询解析、优化、缓存、内置函数、触发器、视图等,跨存储引擎的功能都在这一层实现。
- 存储引擎
MySQL的最底层封装,也是最核心的功能,不同的存储引擎有不同的特点功能,共同点是处理数据的存储和提取。
二、概念简介
1、存储引擎
MySQL数据库存储引擎是数据库底层的架构组件,数据库管理系统使用数据引擎进行创建、查询、更新和删除数据操作。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎还具有不同的特点功能,以满足不同场景下的业务需求。
2、支持关系
可以通过下面两个命令查看MySQL当前版本,和对存储引擎的支持情况。
SELECT VERSION() ; SHOW ENGINES ;
可以看出本地环境是MySQL5.7,支持如下几种存储引擎:
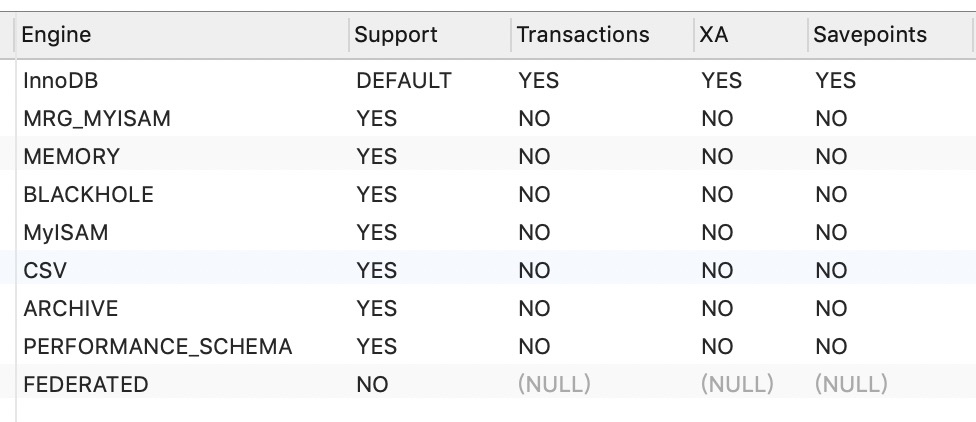
该版本下默认的存储引擎是:InnoDB,功能最为丰富和强大,支持事务,分布式事务,事务保存点。
三、常见存储引擎
1、InnoDB引擎
(1)、基本描述
InnoDB引擎是MySQL默认的事务型引擎,使用非常广泛,极擅长处理短期事务,具有自动崩溃恢复的特性,在日常开发中,一般都要求使用该引擎。
(2)、架构图解
- InnoDB架构图
该图片来自MySQL官网文档。
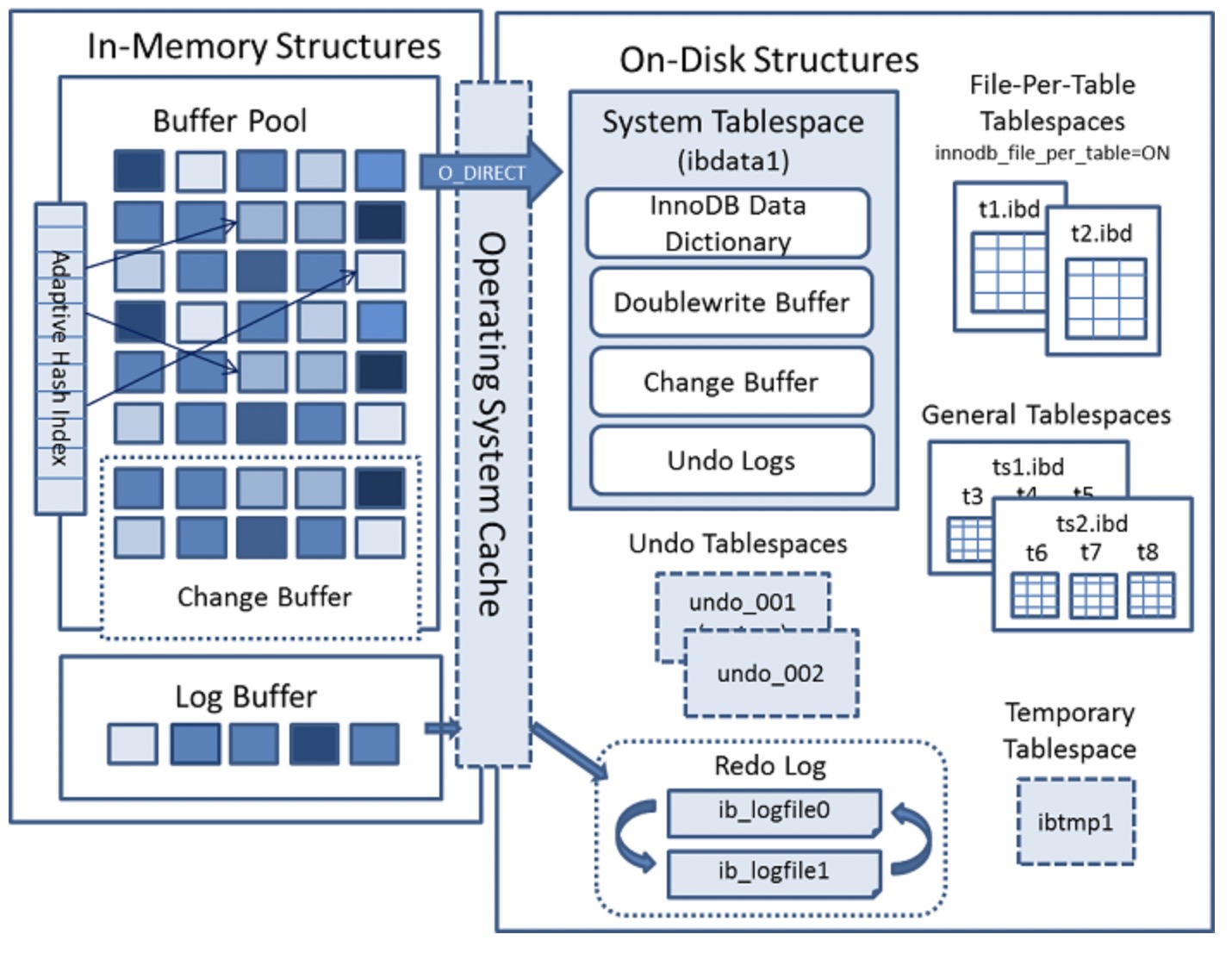
整体分三层:内存结构,Cache,磁盘结构。
- 内存结构
内存结构又包括四大组件
Buffer Pool:缓冲池:是主内存中的一个区域,在InnoDB访问表和索引数据时会在其中进行高速缓存,大量减少磁盘IO操作,提升效率。
Change Buffer:写缓冲区:避免每次增删改都进行IO操作,提升性能。
Adaptive Hash Index:自适应哈希索引:使用索引关键字的前缀构建哈希索引,提升查询速度。
Log Buffer:日志缓冲区:保存要写入磁盘上的日志文件的数据,缓冲区的内容定期刷新到磁盘。
- 磁盘结构
Tables:数据表的物理结构。
Indexes:索引的物理结构。
Tablespaces:表空间,数据存储区域。
Data Dictionary:数据字典,存储元数据信息的表,例如表的描述,结构,索引等。
Doublewrite Buffer:位于系统表空间的一个存储区域,InnoDB在BufferPool中刷新页面时,会将数据页写入该缓冲区后才会写入磁盘。
Redo Log:记录DML操作的日志,用来崩溃后的数据恢复。
Undo Logs:数据更改前的快照,可以用来回滚数据。
(3)、特点描述
- 支持事务
事务内在执行一组SQL语句时,要么全部成功,要么全部失败。
- 支持分布式事务
分布式事务指即使不同操作位于不同的服务应用上,仍然需要保证事务的特性。常见场景:订单和库存在不同的服务中,但却能保持一致性。
- 支持行级锁
加锁时锁定一行数据的锁机制就是行级别锁定(row-level)。MySQL5.7版本中只有InnoDB引擎支持。锁定的粒度小,自然支持的并发就高,锁定的机制也随之变的复杂。
- 支持MVCC
多版本并发控制,通过保存数据在某个时间点的快照来实现的。这意味着一个事务无论运行多长时间,在同一个事务里能够看到数据一致的视图。根据事务开始的时间不同,同时也意味着在同一个时刻不同事务看到的相同表里的数据可能是不同的。
- 支持聚簇索引
是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序。由于聚簇索引的索引页面指针指向数据页面,所以使用聚簇索引查找数据几乎总是比使用非聚簇索引快。
2、MyISAM引擎
(1)、基础描述
MySQL5.1和之前版本的默认存储引擎,不支持事务和行级锁,自然崩溃之后不能自动恢复。
(2)、特点描述
- 锁表机制
对整张表加锁,不针对行加锁,读数据加共享锁,写数据加排他锁。
- 全文索引
支持全文索引,一种基于分词创建的索引,可以支持复杂的检索查询。
3、其他引擎
在MySQL的体系中,最常使用的就是InnoDB和MyISAM引擎,其他多样的存储引擎可以根据业务需求再去熟悉。
絮叨一句:人生苦短,编程语言更是五马六路,这点令人烦躁,所以学习的时候要挑重点,什么是重点,使用最多的就是重点内容。
四、存储引擎选择
在公司的开发规范中,一般硬性要求使用InnoDB引擎,除非有怪癖的业务InnoDB无法支持。
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/mysql-data-base
GitEE·地址
https://gitee.com/cicadasmile/mysql-data-base












