
熟悉Spring开发的朋友都知道Spring提供了5种scope分别是singleton、prototype、request、session、global session。
如下图是官方文档上的截图,感兴趣的朋友可以进去看看这五种分别有什么不同。今天要介绍的是这五种中的前两种,也是Spring最初提供的bean scope singleton 和 prototype。
Spring官方文档介绍如下图:

更多内容可以看官方文档介绍:https://docs.spring.io/spring/docs/3.0.0.M3/reference/html/ch04s04.html
单例bean与原型bean的区别
如果一个bean被声明为单例的时候,在处理多次请求的时候在Spring容器里只实例化出一个bean,后续的请求都公用这个对象,这个对象会保存在一个map里面。当有请求来的时候会先从缓存(map)里查看有没有,有的话直接使用这个对象,没有的话才实例化一个新的对象,所以这是个单例的。但是对于原型(prototype)bean来说当每次请求来的时候直接实例化新的bean,没有缓存以及从缓存查的过程。
1、画图分析
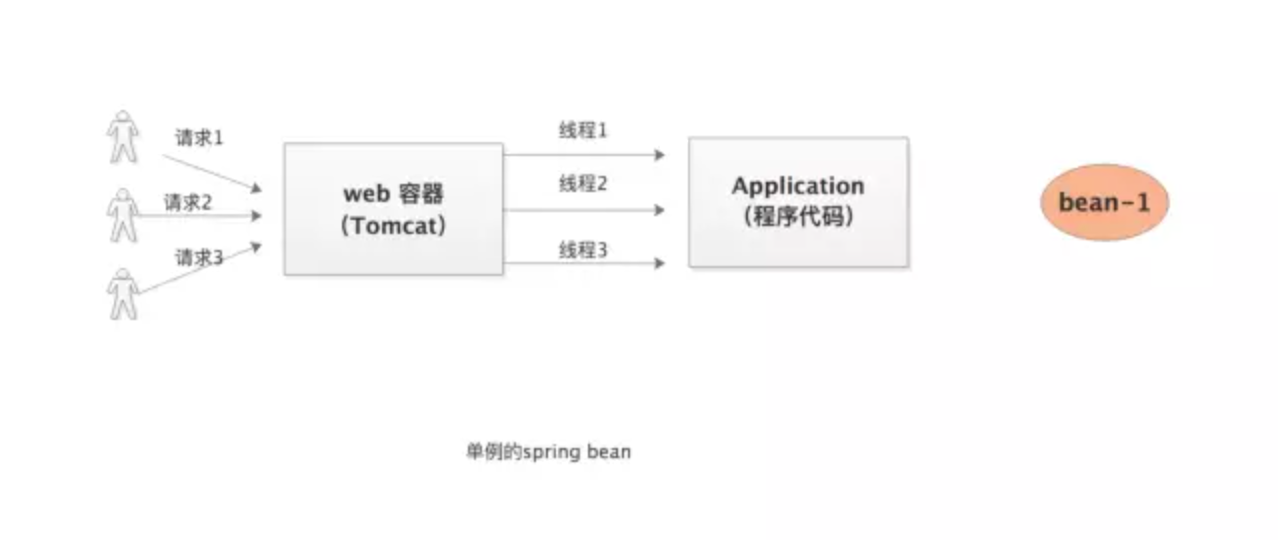
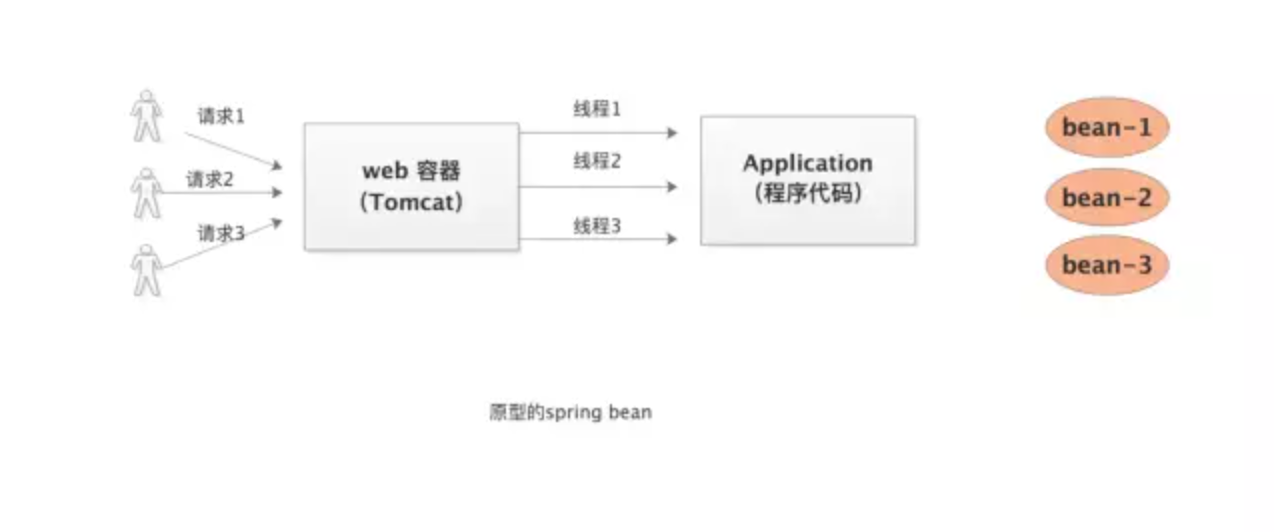
2、源码分析
生成bean时先判断单例的还是原型的。

如果是单例的则先尝试从缓存里获取,没有在新创建。
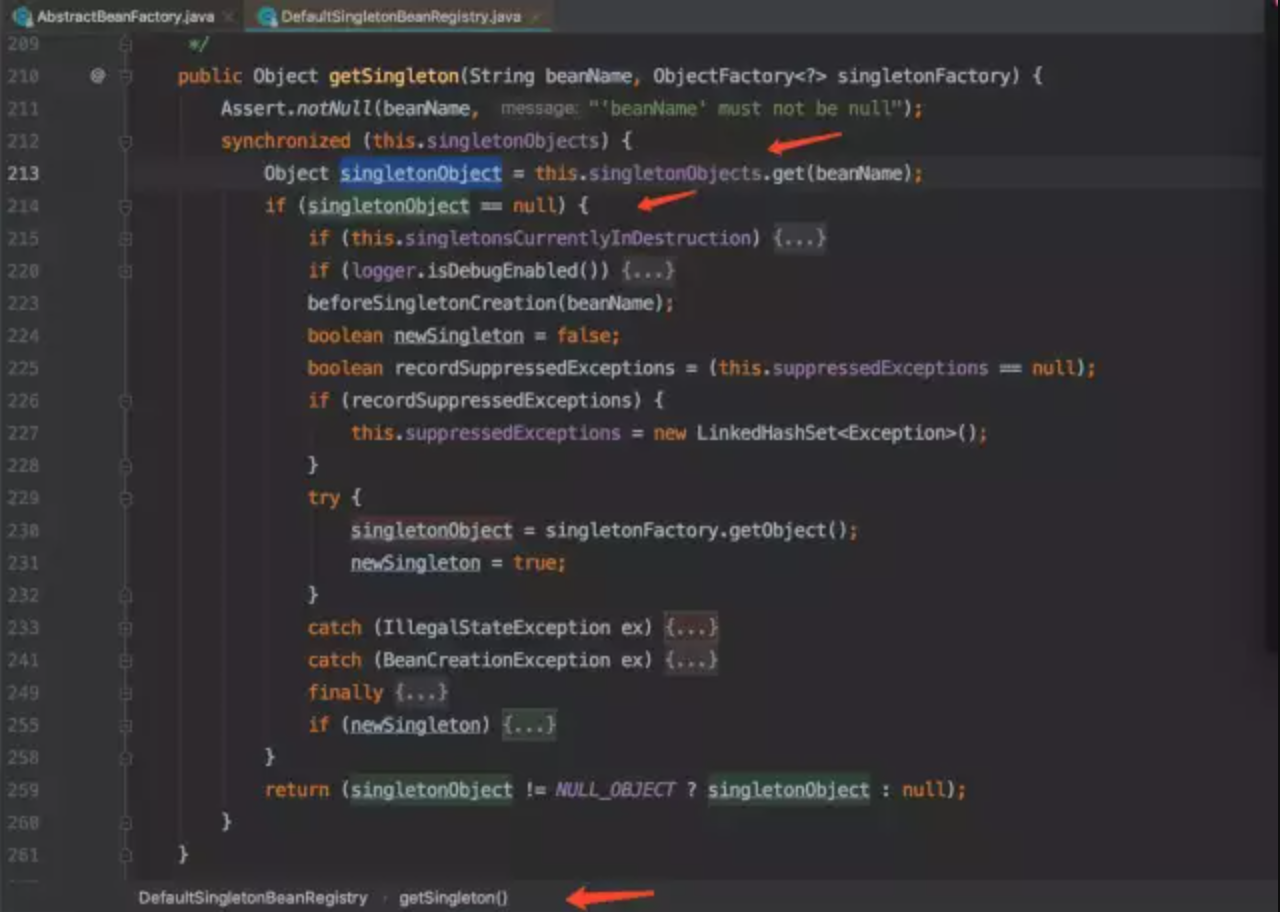
结论:
单例的bean只有第一次创建新的bean 后面都会复用该bean,所以不会频繁创建对象。
原型的bean每次都会新创建
单例bean的优势
由于不会每次都新创建新对象所以有一下几个性能上的优势:
1.减少了新生成实例的消耗
新生成实例消耗包括两方面。第一,spring会通过反射或者cglib来生成bean实例这都是耗性能的操作,其次给对象分配内存也会涉及复杂算法。
2.减少jvm垃圾回收
由于不会给每个请求都新生成bean实例,所以自然回收的对象少了。
3.可以快速获取到bean
因为单例的获取bean操作除了第一次生成之外其余的都是从缓存里获取的所以很快。
单例bean的劣势
单例的bean一个很大的劣势就是他不能做到线程安全!由于所有请求都共享一个bean实例,所以这个bean要是有状态的一个bean的话可能在并发场景下出现问题,而原型的bean则不会有这样问题(但也有例外,比如他被单例bean依赖),因为给每个请求都新创建实例。
总结
Spring 为啥把bean默认设计成单例?
为了提高性能!从几个方面:
少创建实例。
垃圾回收。
缓存快速获取。
单例有啥劣势?
如果是有状态的话在并发环境下线程不安全。














