
原文地址:https://blog.csdn.net/silence2015/article/details/77374910
本文概述
图像检索是图像研究领域中一个重要的话题,广泛应用于医学,电子商务,搜索,皮革等。本文主要是探讨学习基于局部特征和词袋模型的图像检索设计。
图像检索概述
图像检索按照描述图像不同方式可以分为两类,一类是基于文本的图像检索(Text Based Image Retrieval),另一类是基于内容的图像检索(Content Based Image Retrieval)
基于文本的图像检索
基于文本的图像检索主要是利用文本标注的方式为图像添加关键词,比如图像的物体,场景等。在检索图像时候直接根据所要搜索的关键词就可以检索到想要的图像。这种方式实现起来简单,但是非常耗费人工(需要人为给每一张图像标注),对于大型数据库检索不太现实。此外,人工标注存在人为认知误差,对相同图像,人理解不一样,也到导致标注不一致,这使得基于文本的图像检索逐渐失去光彩。
基于内容图像检索
基于内容的图像检索技术是基于图像自身的内容特征来检索图像,这免去人为标注图像的过程。基于内容的图像检索技术是采用某种算法来提取图像中的特征,并将特征存储起来,组成图像特征数据库。当需要检索图像时,采用相同的特征提取技术提取出待检索图像的特征,并根据某种相似性准则计算得到特征数据库中图像与待检索图像的相关度,最后通过由大到小排序,得到与待检索图像最相关的图像,实现图像检索。这种方式使得检索过程自动化,图像检索的结果优劣取决于图像特征提取的好坏,在面对海量数据检索环境中,我们还需要考虑到图像比对(图像相似性考量)的过程,采用高效的算法快速找到相似图像也至关重要。
图像检索主要流程
1、设计预处理流程,对图像数据进行预处理(增强,旋转,滤波,切分等)
2、设计特征提取模块,对图像数据进行高效稳定可重复的特征提取(比如SIFT,SURF,CNN等)
3、对图像数据库建立图像特征数据库
4、抽取检索图像特征,构建特征向量
5、设计检索模块,包含相似性度量准则,排序,搜索
6、返回相似性较高的结果
图像检索所面临的挑战
- 图像光照变化
- 尺度变化
- 视角变化
- 遮挡
- 背景混乱
- 仿射变换
本文实现流程
图像数据集的读取
自己从网上下了十来张图片,有几个美女,有几条狗,有几只猫,还有一本自己拍的书(三个角度拍的)
SIFT提取图像局部特征
SIFT算法是提取特征的一个重要算法,该算法对图像的扭曲,光照变化,视角变化,尺度旋转都具有不变性。SIFT算法提取的图像特征点数不是固定值,维度是统一的128维。SIFT算法我之前也总结过(SIFT算法学习总结)。
KMeans聚类获得视觉单词,构建视觉单词词典
现在得到的是所有图像的128维特征,每个图像的特征点数目还不一定相同(大多有差异)。现在要做的是构建一个描述图像的特征向量,也就是将每一张图像的特征点转换为特征向量。这儿用到了词袋模型,词袋模型源自文本处理,在这儿用在图像上,本质上是一样的。词袋的本质就是用一个袋子将所有维度的特征装起来,在这儿,词袋模型的维度需要我们手动指定,这个维度也就确定了视觉单词的聚类中心数。
这儿可以这么理解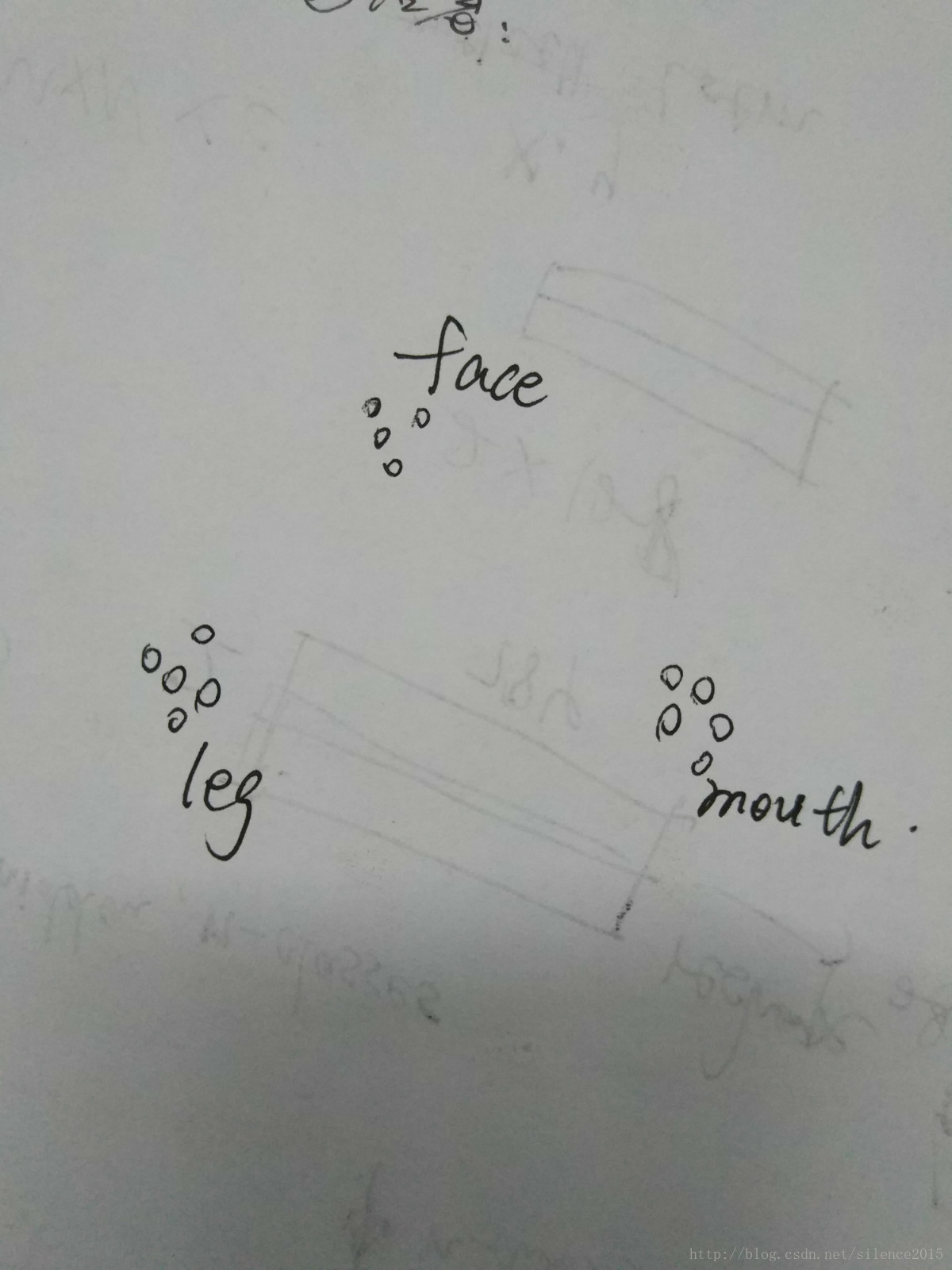
SIFT提取的特征点代表图中的一个小圆圈,很多图像中提取出的特征点代表的属性是类似的,比如某些特征表征脸(这么说很不严谨,但是可以粗浅的这么理解),那么那些表征脸的特征点就会聚集在一起,形成一个簇。那么词袋就是将face,leg,mouth那些特征簇框起来的袋子,一个簇其实也就代表了一个维度的特征,那么怎么让计算机自动形成簇呢?继续往下看。
构造图像特征
熟悉聚类算法的同学已经明白了,上面讲的簇就是通过聚类算法得到的,聚类算法将类别相近,属性相似的样本框起来,是一种无监督学习算法。在本文中,我使用了Kmeans算法来聚类得到视觉单词(也就是face,leg等),通过聚类得到了聚类中心,通过聚类得到了表征词袋的特征点。
ok,到现在,我们得到k个聚类中心(一个聚类中心表征了一个维度特征,k由自己手动设置)和先前SIFT得到的所有图片的特征点,现在就是要通过这两项来构造每一张图像的特征向量。
在本文中,构造的思路跟简单,就是比对特征点与所有聚类中心的距离,将特征点分配到距离最近的特征项,比如经计算某特征点距离leg这个聚类中心最近,那么这个图像中leg这个特征项+1。以此类推,每一张图像特征向量也就构造完毕。
搜索目标图像相似图像
搜索相似图片其实就是在高维特征空间中,寻找靠近的小伙伴的过程。这儿我使用的暴力法,也就是一个个比对检索图片与数据库中所有图片的距离(距离就用的欧式距离计算的),然后排序,得到最接近的图片。在大型数据库中肯定不能这么做,简单的优化思路是可以先将要搜寻的数据集做划分,这儿划分可以理解为特征空间的划分。比如可以用哈希编码来,也可以用神经网络(挺fashion!)。这样在子空间里寻找相似图像就快得多。还有思路就是对数据库做索引,空间换时间。
最后得到的结果


总结
由上面检索不同图片的结果,可以发现,对于简单的物体(在我如数据集中猫,狗,书)检索的结果差强人意,对于大美女的检索结果简直不能看(可能背景比较复杂,还有美女姿势啊,身材啊。。。产生了比较大的影响),最后发现对于书的检索结果是最棒的。
不足之处
- Kmeans聚类时间长
- 词袋表征特征的过程其实牵涉到量化的过程,这其实损失了特征的精度。
- 检索模块设计的太粗糙,速度太慢
- 没有设计反馈系统,系统无法自动升级
- 主要还是慢和精度不高(这么点图片,聚类就花了很久)
github地址
https://github.com/zhaoxin111/imageRetrieval
参考文献
http://yongyuan.name/blog/cbir-technique-summary.html
http://yongyuan.name/blog/CBIR-BoW-for-image-retrieval-and-practice.html
Csurka G, Dance C, Fan L, et al. Visual categorization with bags of keypoints[C]//Workshop on statistical learning in computer vision, ECCV. 2004, 1(1-22): 1-2.










