
一、前言
我是一名京东具身智能算法团队的研究人员,目前,主要专注在真实场景真实机器人下打造一套快速落地新场景的具身智能技术架构,聚集机器人操作泛化能力提升,涉及模仿/强化学习、“视觉-语言-动作”大模型等方法研究。本文主要以第一阶段咖啡机器人任务场景为切入点,来阐述所取得的技术突破,以及后续技术优化方向。如下是机器人全程自主完成打咖啡的视频。
二、问题定义和路径选择
具身智能,指的是配备实体身躯、支持物理交互的智能体所展现出的智能形态。凭借这一智能形式,机器人及其他智能设备得以在复杂多变的现实世界中执行各类任务。然而,鉴于任务的复杂性以及操作所呈现出的高难度与多样性,具身智能技术遭遇诸多挑战,当前仍处于持续发展阶段。现阶段,多数具身智能研究仅在实验室或结构化场景中开展,很难将成果迁移至真实场景加以应用。究其根源,理想环境屏蔽了诸多在真实场景中才会暴露的问题。有鉴于此,我将研究重心聚焦于真实场景下的具身智能技术突破,同时,为推动具身智能技术广泛赋能多元业务,着力打造一套能够快速适配新场景的具身智能技术架构。
目前,具身操作是具身智能核心技术卡点,其技术路线粗分为预测机器人操作动作与预测物体抓取位姿。前者泛化性弱且依赖大量专家数据,后者难适用于复杂长序列任务,灵巧手位姿也难获取。鉴于此,创建了技术上乘上启下“末端模仿” 新路径,融合两者优势,包括预测预抓取位姿(易实现、泛化性强)与统一操作轨迹学习(减少专家数据依赖、操作灵巧),且该路径可灵活扩展为 “视觉 - 语言 - 动作” 大模型方法。
三、快速落地新场景技术架构打造
在当今快速变化的技术环境中,集团会面临着不断适应新业务场景的挑战。只能适应单一场景的具身智能技术不具备长期价值,而能够快速落地新场景的具身智能技术则至关重要。因此,针对于真实场景下机器人打咖啡任务,打造了一套快速落地新场景的技术架构原型,并取得了关键技术突破。
1、关键技术突破及价值
1)真实场景下从0到1打造具身智能系统技术架构
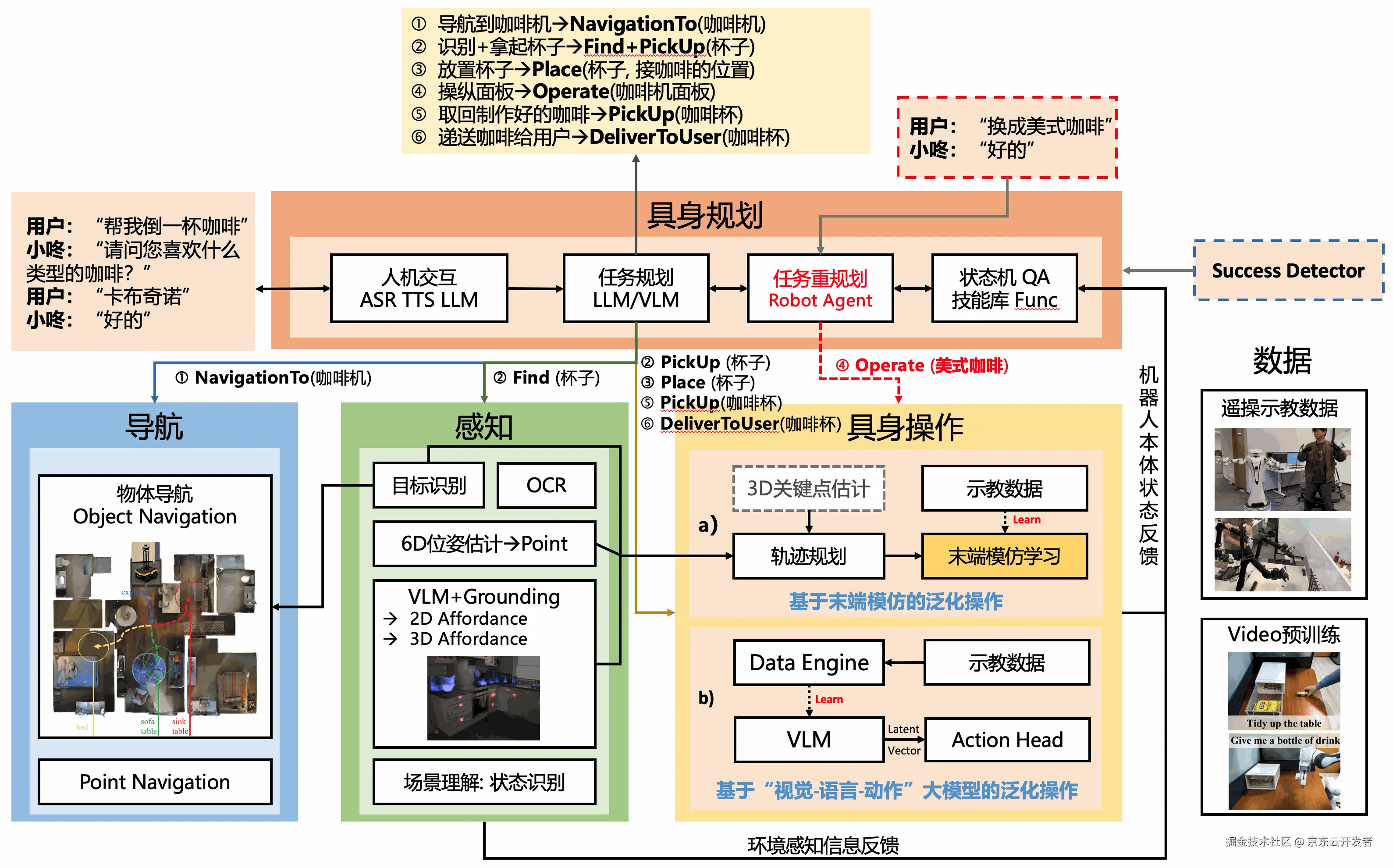
- 面临挑战:具身智能系统往往涉及内容模块较多,耦合关系较为复杂,可扩展性较差,难以快速适应新任务场景。与此同时,真实场景下,往往面临着通信时延、模型推理速度和系统稳定性等挑战。
- 技术突破:如下图所示,打造了一套具备高扩展性的具身智能系统技术架构,只需定义合适的子任务序列就可落地新场景。其中,该系统以ROS系统为基础构建,整个流程通过主调度模块进行协调,确保各模块之间的协同工作,通过不同控制模式决定系统不同阶段的工作方式,包括导航、感知、基于Agent的任务规划、遥操、具身操作等。此外,设计了模型异步推理、GRPC协议数据传输和子母路由通信等机制来攻克通信时延、推理速度慢等问题。
- 核心价值:在真实场景下,从0到1打造了整套具身智能系统技术架构,并且成功落地咖啡机器人任务场景中,而不是在简单的实验室或者结构化场景下。与此同时,为后续真实场景下具身智能技术的研发提供了坚实的基础。
2)面向双臂灵巧手构建高频率一体式遥操技术
- 面临挑战:目前,大多数遥操采用了同构方式。这种方式需要额外配置相应的机械臂,并且不同结构机器人是无法共享,可扩展性及便捷性低。其次,双臂和灵巧手的一体式遥操技术对其同步性及延迟率要求高,实现难度大。
- 技术突破:如以下视频所示,构建了面向双臂灵巧手的一体式高频率遥操技术。通过结合惯性动捕和视觉动捕技术,对遥操设备进行了创新设计,使机器人能够精准复刻人类动作。同时,借助手和臂数据透传技术,优化了从动作捕捉到控制执行的高频率跟随链路,极大提升了系统响应速度与操作精度。
- 核心价值:相比于行业其他遥操技术,该技术具备轻量化、价格低廉和扩展性强特点。此外,通过该遥操技术,双臂灵巧手的整体控制频率达50hz以上,并且系统延时在50ms以内。
3)少量数据下实现物体位置的泛化操作
- 面临挑战:具身操作的泛化性一直是一个挑战性问题。目前,大多数方法都依赖于大量数据使其涌现出泛化性能。然而,大量的示教数据需要消耗大量人力物力。训练模型也需较多计算资源的支撑,且效果也难以达到较佳的泛化性能。
- 技术突破:如下图所示,提出了基于末端模仿的泛化操作方法,聚集于统一的操作轨迹学习,能在较少的数据下实现较强的位置泛化能力,涉及核心模块包括:操作物体感知与位姿估计、预操作位姿到达和聚集物体的策略学习。此外,设计了聚集于物体的视觉特征提取模块,增强对核心操作区域的感知。
- 核心价值:相比与行业已有方法,首次提出聚集于核心操作轨迹的学习方法,能在较少数据量情况下实现物体位置的泛化操作,在打咖啡任务中,成功率达90%以上。此外,在大量抓取任务中(拿扫码枪、抓娃娃、搬箱子等等),该方法表现出的性能相比于baseline成功率提升了50%以上。

2、咖啡机器人任务场景实践
基于所打造的具身智能技术架构,首先落地了咖啡机器人任务场景。机器人打咖啡任务主要包含以下几个步骤:导航到咖啡机、拿起空杯子、放好杯子、点击屏幕(选择咖啡、确认按钮和已放好按钮)、拿起咖啡杯、导航到用户位置、将咖啡杯递给人。打咖啡任务是一个真实场景下的长序列任务,包含多个子任务。子任务都是按序列衔接好的,完成当前子任务才会执行下一个子任务。与此同时,设计了子任务是否成功完成的检测机制,提升整个系统的鲁棒性,比如:点击屏幕过程中,如果没有点击触发,会反复点击直到成功。即便面对打咖啡这样复杂的场景,凭借该具身智能技术架构打造的系统,仍能以极高的成功率完成任务。以下是机器人打咖啡的精彩瞬间。
|
在咖啡机器人任务场景实践中,遇到诸多新问题。起初为机器人在胸部和头部各配备 RealSense D435 相机,却发现胸部相机易被机械臂遮挡,且两款相机 FOV 过小,常无法捕捉操作物体和灵巧手,而这类问题在实验室桌面操作场景中难以察觉。于是,将头部相机换成 FOV 更大的 ZED 相机,可新相机又导致模型视觉特征不聚集,遂通过聚焦手部局部视角解决。点击屏幕时,按钮需快速抽离动作才能触发,给灵巧手控制带来极大困难。为此设计检测机制,让灵巧手能反复尝试,有效提升了点击成功率。
四、下一步技术优化及进展
后续,将进一步完善和优化整个具身智能系统架构,使其能快速落地新场景。核心聚集于具身操作方向,提升机器人的泛化操作能力,扩充其技能库的上限。结合具身技术发展趋势以及现有架构的不足,主要围绕以下两个方面开展工作。
- “视觉-语言-动作”大模型促进快速落地新场景:“视觉-语言-动作”大模型会利用“视觉-语言”预训练模型知识来促进对机器人动作的学习。在大量的数据训练基础上,“视觉-语言-动作”大模型将会涌现出令人意想不到的能力:基于语言指令的新技能泛化、新物体泛化、甚至多机协作能力。这些潜能在Figure AI公司最新发布的Helix模型实验结果中已展现出来。
- 真机强化学习优化整个具身智能系统:在目前的具身操作技术中,大多数采用了模仿学习方法。然而,模仿学习存在其局限性,较为依赖于专家数据,并且存在性能上限。强化学习方法则能使机器人探索更多数据,突破其性能上限,对专家数据依赖程度较低。另外,真机强化学习是基于机器人实时与环境交互所得数据来优化模型,这种优化不仅仅是提升模型性能,而且能够对整个具身系统进行优化。
五、我对具身智能的思考和坚持
- 在具身智能技术的实际落地进程中,真实场景的复杂程度往往远远超出了在实验室或结构化场景中预先设定的界限。在真实任务场景中进行技术探索,不但有助于我们对算法的实际性能进行验证和优化,还能够发掘出在实验室或结构化场景中未曾预想到的问题与挑战。通过在真实场景中对技术进行测试和应用,我们能够获取更为丰富的数据和反馈,进而推动技术不断迭代和创新。
- 随着 Figure AI 公司发布的 Helix 模型并在物流仓库中的成功应用,这使我愈发坚信具身智能的时代已然降临。对其实现的技术逻辑进行剖析:重点围绕一个机器人本体,在一个特定的垂类领域中积累充足的数据量,在 “视觉 - 语言 - 动作” 大模型的有力支持下,机器人能够学会多种类人的技能,并且具有较强的泛化性能。其能够出圈的核心在于围绕一本体在真实场景下打磨技术。我认为这是实现快速落地的较佳方案,值得借鉴。此外,当前技术都围绕提升机器人任务成功率开展,若要真正将其在新场景中落地,还必须考虑机器人完成任务的效率问题。
- 展望未来,机器人会逐步融入人类社会。我们须倾热血与干劲,全力投身具身智能技术攻坚,力求让技术快速落地新场景,为企业技术增长添砖加瓦。











