
最近 “pypy为什么能让python比c还快” 刷屏了,原文讲的内容偏理论,干货比较少。我们可以再深入一点点,了解pypy的真相。
正式开始之前,多唠叨两句。我司发力多个赛道的游戏,其中包括某鱼类游戏Top2项目,拿过阿拉丁神灯奖的SLG卡牌小游戏项目和海外三消游戏。这些不同类型的游戏,后端大多是使用的是pypy。对于如何使用pypy,我有一点使用经验可以聊聊。话不多说,正式开始,本文包括下面几个部分:
语言分类
python的解释器实现
pypy为什么快
性能比较
性能优化方法
pypy的特性
小结
语言分类
我们先从最基本的一些语言分类概念聊起,对这部分内容非常了解的朋友可以跳过。
静态语言 vs 动态语言
如果在编译时知道变量的类型,则该语言为静态类型。静态类型语言的常见示例包括Java,C,C ++,FORTRAN,Pascal和Scala。在静态类型语言中,一旦使用类型声明了变量,就无法将其分配给其他不同类型的变量,这样做会在编译时引发类型错误。
# java
int data;
data = 50;
data = “Hello Game_404!”; // causes an compilation error
如果在运行时检查变量的类型,则语言是动态类型的。动态类型语言的常见示例包括JavaScript,Objective-C,PHP,Python,Ruby,Lisp和Tcl。在动态类型语言中,变量在运行时通过赋值语句绑定到对象,并且可以在程序执行期间将相同的变量绑定到不同类型的对象。
# python
data = 10;
data = "Hello Game_404!"; // no error caused
data = data + str(10)
一般来说静态语言编译成字节码执行,动态语言使用解释器执行。编译型语言性能更高,但是较难移植到不同的CPU架构体系和操作系统。解释型语言易于移植,性能会比编译语言要差得多。这是频谱的两个极端。
强类型语言 vs 弱类型语言
强类型语言是一种变量被绑定到特定数据类型的语言,如果类型与表达式中的预期不一致,将导致类型错误,比如下面这个:
# python
temp = “Hello Game_404!”
temp = temp + 10; // program terminates with below stated error (TypeError: must be str, not int)
python和我们感觉不一致,背叛了弱类型语言,不像世界上最好的语言:(
# php
$temp = “Hello Game_404!”;
$temp = $temp + 10; // no error caused
echo $temp;
常见编程语言的象限分类如下图:
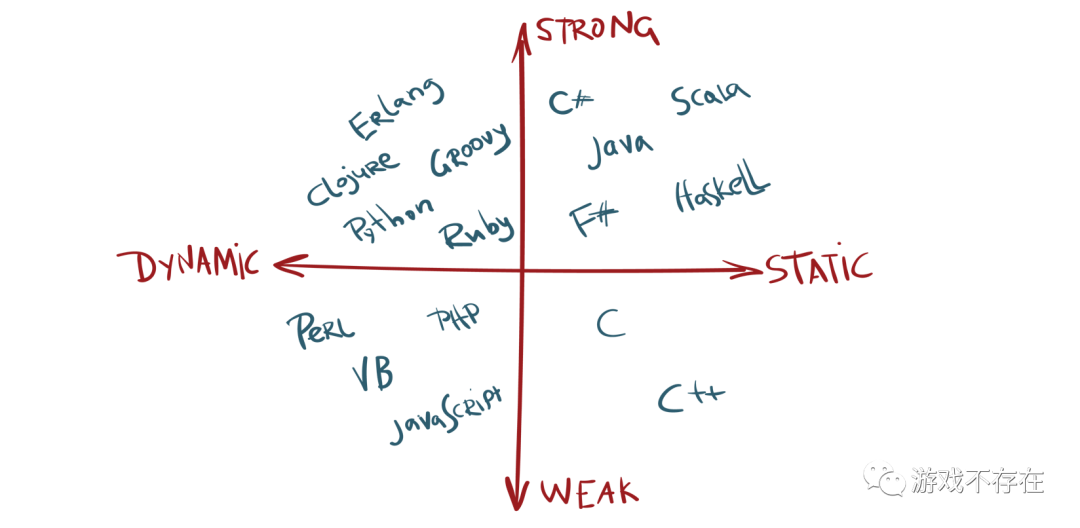
language
这一部分内容主要翻译自参考链接1
python的解释器实现
python是一门动态编程语言,由特定的解释器解释执行。下面是一些解释器实现:
CPython 使用c语言实现的解释器
PyPy 使用python语言的子集RPython实现的解释器,一般情况下PyPy比CPython快4.2倍
Stackless Python 带有协程实现的解释器
Jython Java实现的解释器
IronPython .net实现的解释器
Pyston 一个较新的实现,是CPython 3.8.8的一个分支,具有其他针对性能的优化。它针对大型现实应用程序(例如Web服务),无需进行开发工作即可提供高达30%的加速。
...
还有几个相关概念:
IPython && Jupyter ipython是使用python构建的交互式shell, Jupyter是其web化的包装。
Anaconda 是一个python虚拟环境,Python数据科学常用。
mypyc 一个新的项目,将python编译成c代码库,以期提高python的运行效率。
py文件和pyc文件 pyc文件是python编译后的字节码,也可以由python解释器执行。
wheel文件和egg文件 都是项目版本发布的打包文件,wheel是最新标准。
...
这里大家会有一个疑问,python不是解释型语言嘛?怎么又有编译后的pyc。是这样的: py文件编译成pyc后,解释器默认 优先 执行pyc文件,这样可以加快python程序的 启动速度 (注意是启动速度)。继背叛弱类型语言后,python这个鬼又在编译语言和解释语言之间横跳。
还有一个事件是Go语言在1.5版本实现自举。Go语言在1.5版本之前使用c实现的编译器,在1.5版本时候使用Go实现了自己的编译器,这里有一个鸡生蛋和蛋生鸡的过程,也挺有意思。
pypy为什么快
pypy使用python的子集rpython实现了解释器,和前面介绍的Go的自举有点类似。反常识的是rpython的解释器会比c实现的解释器快?主要是因为pypy使用了JIT技术。
Just-In-Time (JIT) Compiler 试图通过对机器码进行一些实际的编译和一些解释来获得两全其美的方法。简而言之,以下是JIT编译为提高性能而采取的步骤:
标识代码中最常用的组件,例如循环中的函数。
在运行时将这些零件转换为机器码。
优化生成的机器码。
用优化的机器码版本交换以前的实现。
这也是 “pypy为什么能让python比c还快” 一文中的示例展现出来的能力。pypy除了速度快外,还有下面一些特点:
内存使用情况比cpython少
gc策略更优化
Stackless 协程模式默认支持,支持高并发
兼容性好,高度兼容cpython实现,基本可以无缝切换
以上都是宣称
pypy这么强,快和省都占了,为什么没有大规模流行起来呢? 我个人认为,主要还是python的原因。
python生态中大量库采用c实现,特别是科学计算/AI相关的库,pypy在这块并没有优势。pypy快的主要在pure-python,也就是纯粹的python实现部分。
pypy适合长驻内存的高并发应用(web服务类)
python是一门胶水语言,并不追求性能极致,即使快4倍也不够快:( 🐶。肯定比不上c,原文中的c应该是 偷换了概念 ,指c实现的cpython解释器。
需要注意的是,pypy一样也有GIL的存在, 所以高并发主要在stackless。
这一部分内容参考自参考链接2
性能比较
我们可以编写性能测试用例,用代码说话,对各个实现进行对比。本文的测试用例并不严谨,不过也足够说明一些问题了。
开车和步行
原文中累加测试用例是100000000次,我们减少成1000次:
import time
start = time.time()
number = 0
for i in range(1000):
number += i
print(number)
print(f"Elapsed time: {time.time() - start} s")
测试结果如下表(测试环境在本文附录部分):
| 解释器 | 循环次数 | 耗时(s) |
|---|---|---|
| python3 | 1000 | 0.00014281272888183594 |
| pypy3 | 1000 | 0.00036716461181640625 |
结果显示运行1000次循环的情况下cpython要比pypy快,这和循环100000000次 相反 。用下面的例子可以非常形象的解释这一点。
假设您想去一家离您家很近的商店。您可以步行或开车。您的汽车显然比脚快得多。但是,请考虑需要执行以下操作:
去你的车库。
启动你的车。
让汽车暖一点。
开车去商店。
查找停车位。
在返回途中重复该过程。
开车要涉及很多开销,如果您想去的地方在附近,这并不总是值得的!现在想想如果您想去五十英里外的邻近城市会发生什么。开车去那里而不是步行肯定是值得的。
举例来自参考链接2
尽管速度的差异并不像上面类比那么明显,但是PyPy和CPython的情况也是如此。
横向对比
我们横向对比一下c,python3, pypy3, js 和lua的性能。
# js
const start = Date.now();
let number = 0
for (i=0;i<100000000;i++){
number += i
}
console.log(number)
const millis = Date.now() - start;
console.log(`milliseconds elapsed = `, millis);
# lua
local starttime = os.clock();
local number = 0
local total = 100000000-1
for i=total,1,-1 do
number = number+i
end
print(number)
local endtime = os.clock();
print(string.format("elapsed time : %.4f", endtime - starttime));
# c
#include <stdio.h>
#include <time.h>
const long long TOTAL = 100000000;
long long mySum()
{
long long number=0;
long long i;
for( i = 0; i < TOTAL; i++ )
{
number += i;
}
return number;
}
int main(void)
{
// Start measuring time
clock_t start = clock();
printf("%llu \n", mySum());
// Stop measuring time and calculate the elapsed time
clock_t end = clock();
double elapsed = (end - start)/CLOCKS_PER_SEC;
printf("Time measured: %.3f seconds.\n", elapsed);
return 0;
}
| 解释器 | 循环次数 | 耗时(s) |
|---|---|---|
| c | 100000000 | 0.000 |
| pypy3 | 100000000 | 0.15746307373046875 |
| js | 100000000 | 0.198 |
| lua | 100000000 | 0.8023 |
| python3 | 100000000 | 10.14592313766479 |
测试结果可见,c无疑是最快的,秒杀其它语言,这是编译语言的特点。在解释语言中,pypy3表现配得上优秀二字。
内存占用
测试用例中增加内存占用的输出:
p = psutil.Process()
mem = p.memory_info()
print(mem)
测试结果如下:
# python3
pmem(rss= 9027584, vms=4747534336, pfaults= 2914, pageins=1)
# pypy3
pmem(rss=39518208, vms=5127745536, pfaults=12188, pageins=58)
pypy3的内存占用会比python3要高,这个才科学,用内存空间换了运行时间。当然这个评测并不严谨,实际情况如何,pypy宣称的内存占用较少,我表示怀疑,但是没有证据。
性能优化方法
了解语言的性能比较后,我们再看看一些性能优化的方法,这对在cpython和pypy之间选型有帮助。
使用c函数
python中使用c函数,比如这里的累加可以使用reduce替换,可以提高效率:
def my_add(a, b):
return a + b
number = reduce(add, range(100000000))
| 解释器 | 次数 | 耗时(s) |
|---|---|---|
| pypy3 | reduce | 0.08371400833129883 |
| pypy3 | 100000000 | 0.15746307373046875 |
| python3 | reduce | 5.705173015594482 s |
| python3 | 100000000循环 | 10.14592313766479 |
结果展示,reduce对cpython和pypy都有效。
优化循环
优化最关键的地方,提高算法效率,减少循环。更改一下累加的需求,假设我们是求100000000以内的偶数的和,下面展示了使用range的步进减少循环次数来提高性能:
try:
xrange # python2注意使用xrange是迭代器,而range是返回一个list
except NameError: # python3
xrange = range
def test_0():
number = 0
for i in range(100000000):
if i % 2 == 0:
number += i
return number
def test_1():
number = 0
for i in xrange(0, 100000000, 2):
number += i
return number
| 解释器 | 循环次数 | 耗时(s) |
|---|---|---|
| python3 | 50000000 | 2.6723649501800537 s |
| python3 | 100000000 | 6.530670881271362 s |
循环次数减半后,有效率显著提升。
静态类型
python3可以使用类型注解,提高代码可读性。类型确定逻辑上对性能有帮助,每次处理数据的时候,不用再进行类型推断。
number: int = 0
for i in range(100000000):
number += i
| 解释器 | 循环次数 | 类型 | 耗时(s) |
|---|---|---|---|
| python3 | 100000000 | int | 9.492593050003052 s |
| python3 | 100000000 | 不定义 | 10.14592313766479 s |
内存相当于一个空间,我们要用不同的盒子去填充它。图中左边部分1,都使用长度为4(想像float类型)的盒子填充,一行一个,速度最快;图中中间部分2,使用长度为3(想像long类型)和长度为1(想像int类型)的箱子,一行2个,也挺快;图中右侧3,虽然箱子长度仍然是3和1,但是由于没有刻度,填充时候需要试装,所以速度最慢。
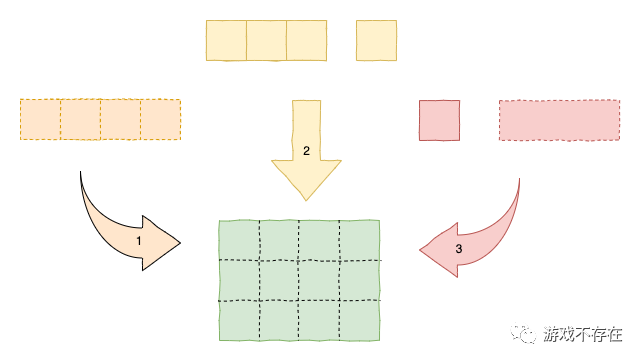
数据类型
算法的魅力
优化到最后,最重量级的内容登场:高斯求和算法。高斯的故事,想必大家都不陌生,下面是算法实现:
def gaussian_sum(total: int) -> int:
if total & 1 == 0:
return (1 + total) * int(total / 2)
else:
return total * int((total - 1) / 2) + total
# 4999999950000000
number = gaussian_sum(100000000 - 1)
| 解释器 | 循环次数 | 耗时(s) |
|---|---|---|
| python3 | 高斯求和 | 4.100799560546875e-05 s |
| python3 | 100000000循环 | 10.14592313766479 |
使用高斯求和后,程序秒开。这大概就是业内面试,要考算法的真相,也是算法的魅力所在。
优化的原则
简单介绍一下优化的原则,主要是下面2点:
- 使用测试而不是推测。
python3 -m timeit 'x=3' 'x%2'
10000000 loops, best of 5: 25.3 nsec per loop
python3 -m timeit 'x=3' 'x&1'
5000000 loops, best of 5: 41.3 nsec per loop
python2 -m timeit 'x=3' 'x&1'
10000000 loops, best of 3: 0.0262 usec per loop
python2 -m timeit 'x=3' 'x%2'
10000000 loops, best of 3: 0.0371 usec per loop
`上面示例展示了,求奇偶的情况下,python3中位运算比取模慢,这是个反直觉推测的地方。在我的python冷兵器合集一文中也有介绍。而且需要注意的是,python2和python3表现相反,所以性能优化要实测,注意环境和实效性。
- 遵循2/8法则, 不要过度优化,不用赘述。
pypy的特性
pypy还有下面一些特性:
cffi pypy推荐使用cffi的方式加载c
cProfile pypy下使用cProfile检测性能无效
sys.getsizeof pypy的gc方式差异,sys.getsizeof无法使用
__slots__ cpython使用的slots,在pypy下失效
使用slots在python对象中,可以减少对象内存占用,提高效率,下面是测试用例:
def test_0():
class Player(object):
def __init__(self, name, age):
self.name = name
self.age = age
players = []
for i in range(10000):
p = Player(name="p" + str(i), age=i)
players.append(p)
return players
def test_1():
class Player(object):
__slots__ = "name", "age"
def __init__(self, name, age):
self.name = name
self.age = age
players = []
for i in range(10000):
p = Player(name="p" + str(i), age=i)
players.append(p)
return players
测试日志如下:
# python3 slots
pmem(rss=10776576, vms=5178499072, pfaults=3351, pageins=58)
Elapsed time: 0.010818958282470703 s
# python3 默认
pmem(rss=11792384, vms=5033795584, pfaults=3587, pageins=0)
Elapsed time: 0.01322031021118164 s
# pypy3 slots
pmem(rss=40042496, vms=5263011840, pfaults=12341, pageins=4071)
Elapsed time: 0.005321025848388672 s
# pypy3 默认
pmem(rss=39862272, vms=4974653440, pfaults=12280, pageins=0)
Elapsed time: 0.004619121551513672 s
详细信息可以看参考链接4和5
pypy最重要的特性还是stackless,支持高并发。这里有IO密集型任务(I/O-bound)和CPU密集型任务(compute-bound)的区分,CPU密集型任务的代码,速度很慢,是因为执行大量CPU指令,比如上文的for循环;I / O密集型,速度因磁盘或网络延迟而变慢,这两者之间是有区别的。这部分内容,要介绍清楚也不容易,容我们下章见。
小结
python是一门解释型编程语言,具有多种解释器实现,常见的是cpython的实现。pypy使用了JIT技术,在一些常见的场景下可以显著提高python的执行效率,对cpython的兼容性也很高。如果项目纯python部分较多,推荐尝试使用pypy运行程序。
注:由于个人能力有限,文中示例如有谬误,还望海涵。
附录
测试环境
MacBook Pro (16-inch, 2019)(2.6 GHz 六核Intel Core i7)
Python 2.7.16
Python 3.8.5
Python 3.6.9 [PyPy 7.3.1 with GCC 4.2.1 Compatible Apple LLVM 11.0.3 (clang-1103.0.32.59)]
Python 2.7.13 [PyPy 7.3.1 with GCC 4.2.1 Compatible Apple LLVM 11.0.3 (clang-1103.0.32.59)]
lua#Lua 5.2.3 Copyright (C) 1994-2013 Lua.org, PUC-Rio
node#v10.16.3
参考链接
https://stackoverflow.com/questions/23068076/using-slots-under-pypy
https://morepypy.blogspot.com/2010/11/efficiently-implementing-python-objects.html
**-----**------**-----**---**** End **-----**--------**-----**-****
往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/SpT1aLzjcyRaLWOzYZRxOg,如有侵权,请联系删除。











