
项目背景
大家好,我是J哥。
新房数据,对于房地产置业者来说是买房的重要参考依据,对于房地产开发商来说,也是分析竞争对手项目的绝佳途径,对于房地产代理来说,是踩盘前的重要准备。
今天J哥以 「惠民之家」 为例,手把手教你利用Python将惠州市新房数据批量抓取下来,共采集到近千个楼盘,包含楼盘名称、销售价格、主力户型、开盘时间、容积率、绿化率等 「41个字段」。数据预览如下:
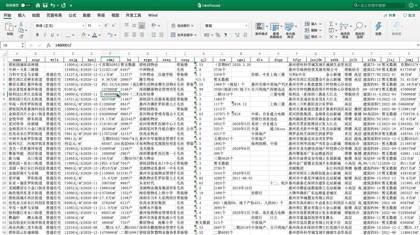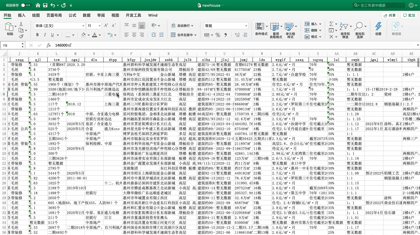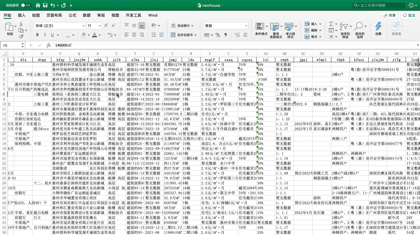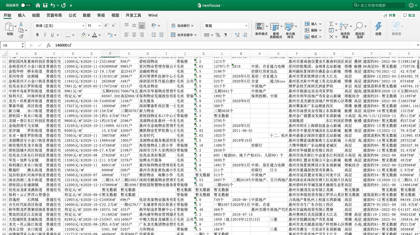
后台回复「新房」二字,可领取本文代码。
项目目标
惠民之家首页网址:
http://www.fz0752.com/
新房列表网址:
http://www.fz0752.com/project/list.shtml
选择一个新房并点击「详情信息」即可找到目标字段:
项目准备
软件:Pycharm
第三方库:requests,fake_useragent,lxml
网页分析
列表页分析
打开新房列表网页,点击「下一页」后,网址变成:
http://www.fz0752.com/project/list.shtml?state=&key=&qy=&area=&danjia=&func=&fea=&type=&kp=&mj=&sort=&pageNO=2
很显然,这是静态网页,翻页参数为「pageNO」,区域参数为「qy」,其余参数也很好理解,点击对应筛选项即可发现网页链接变化。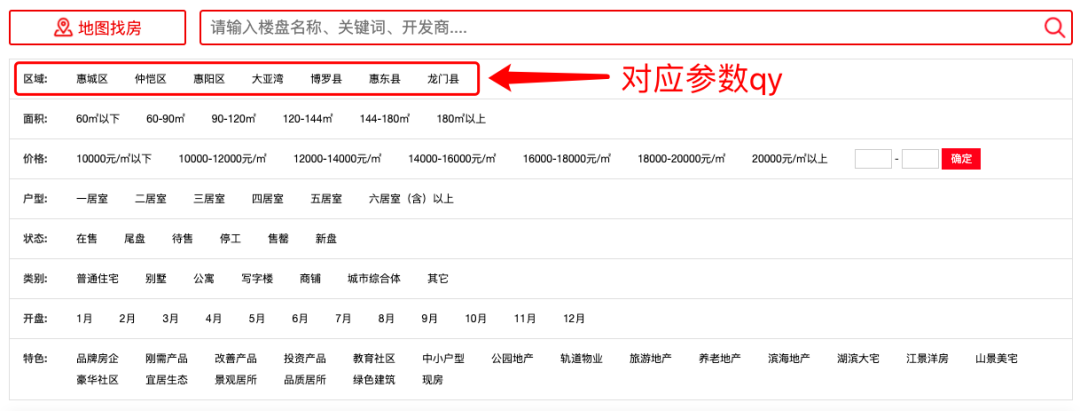 )咱们可以通过遍历区域和页码,将新房列表的房源URL提取下来,再遍历这些URL,抓取到每个房源的详情信息。
)咱们可以通过遍历区域和页码,将新房列表的房源URL提取下来,再遍历这些URL,抓取到每个房源的详情信息。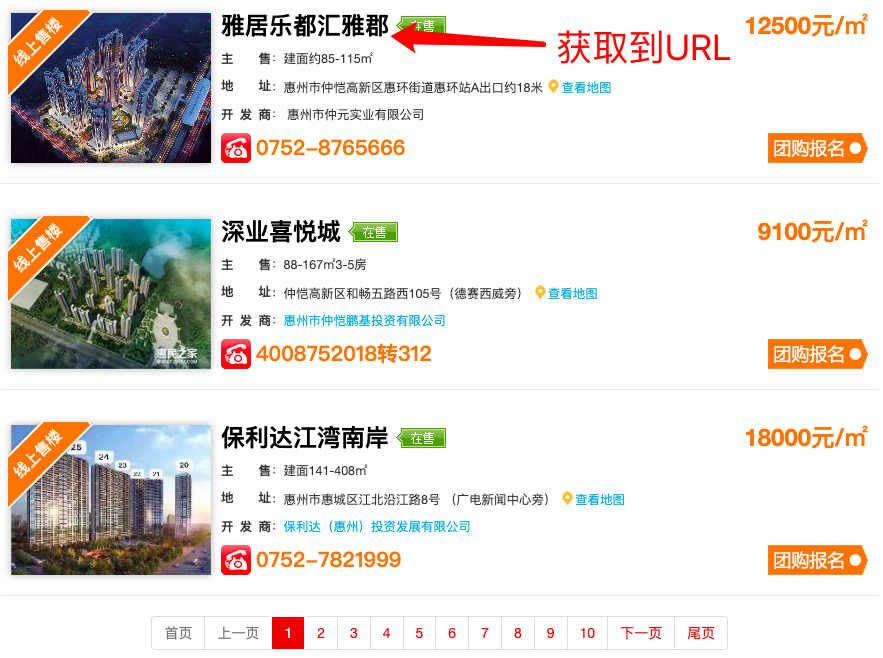
详情页分析
选择一个新房URL,点击进去,链接如下:
http://newhouse.fz0752.com/fontHtml/html/project/00020170060.html
即这个新房的id为「00020170060」,再点击详情信息,链接变为:
http://newhouse.fz0752.com/project/detail.shtml?num=20170060
即这个新房的「详情信息」的id为「20170060」,我们可以大胆假设这个id就是新房id截取的一部分。多找几个新房点击尝试,很容易验证这个规律。
反爬分析
相同的ip地址频繁访问同一个网页会有被封风险,本文采用fake_useragent,将随机生成的User-Agent请求头去访问网页,将减少ip封锁的风险。
代码实现
导入爬虫相关库,定义一个主函数,构建区域列表(不同区域对应不用的区域id),遍历并用requests去请求由区域参数和页码参数拼接的URL。这里将页码设置50上限,当遍历的某个房源URL长度为0(即不存在新房数据)时,直接break,让程序进行下一个区域的遍历,直至所有数据抓取完毕,程序停止。
# -*- coding = uft-8 -*-
# @Time : 2020/12/21 9:29 下午
# @Author : J哥
# @File : newhouse.py
import csv
import time
import random
import requests
import traceback
from lxml import etree
from fake_useragent import UserAgent
def main():
#46:惠城区,47:仲恺区,171:惠阳区,172:大亚湾,173:博罗县,174:惠东县,175:龙门县
qy_list = [46,47,171,172,173,174,175]
for qy in qy_list: #遍历区域
for page in range(1,50): #遍历页数
url = f'http://www.fz0752.com/project/list.shtml?state=&key=&qy={qy}&area=&danjia=&func=&fea=&type=&kp=&mj=&sort=&pageNO={page}'
response = requests.request("GET", url, headers = headers,timeout = 5)
print(response.status_code)
if response.status_code == 200:
re = response.content.decode('utf-8')
print("正在提取" + str(qy) +'第' + str(page) + "页")
#time.sleep(random.uniform(1, 2))
print("-" * 80)
# print(re)
parse = etree.HTML(re)
get_href(parse,qy)
num = ''.join(parse.xpath('//*[@id="parent-content"]/div/div[6]/div/div[1]/div[2]/div[1]/div[2]/div[1]/div[1]/a/@href'))
print(len(num))
if len(num) == 0:
break
if __name__ == '__main__':
ua = UserAgent(verify_ssl=False)
headers = {"User-Agent": ua.random}
time.sleep(random.uniform(1, 2))
main()
发送请求,获取新房列表网页,并解析到所有新房URL,同时将新房id替换为详情信息id。在程序运行中发现有少数新房URL不一致,因此这里做了判断,修改后可以获取完整的详情信息id,并拼接出对应的URL。
def get_href(parse,qy):
items = parse.xpath('//*[@id="parent-content"]/div/div[6]/div/div[1]/div[2]/div')
try:
for item in items:
href = ''.join(item.xpath('./div[2]/div[1]/div[1]/a/@href')).strip()
print("初始href为:",href)
#print(len(href))
if len(href) > 25:
href1 = 'http://newhouse.fz0752.com/project/detail.shtml?num=' + href[52:].replace(".html","")
else:
href1 = 'http://newhouse.fz0752.com/project/detail.shtml?num=' + href[15:]
print("详情href为:",href1)
try:
get_detail(href1,qy)
except:
pass
except Exception:
print(traceback.print_exc())
打印结果如下: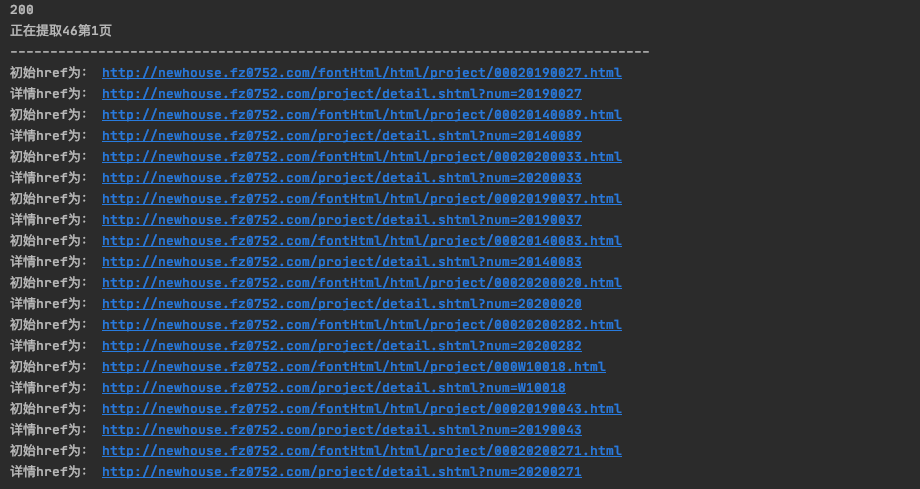
详情信息URL找到后,定义一个函数去请求详情页数据,同时携带qy参数,最后将其保存到csv中。
def get_detail(href1,qy):
time.sleep(random.uniform(1, 2))
response = requests.get(href1, headers=headers,timeout = 5)
if response.status_code == 200:
source = response.text
html = etree.HTML(source)
开始解析详情页中的各个字段,这里用到xpath进行数据解析,由于需要解析的字段太多,高达41个,限于篇幅,以下仅给出部分字段解析代码。当然,其他字段解析基本一样。
#项目状态
try:
xmzt = html.xpath('//*[@id="parent-content"]/div/div[3]/div[3]/div[1]/div[1]/text()')[0].strip()
except:
xmzt = None
#项目名称
try:
name = html.xpath('//*[@id="parent-content"]/div/div[3]/div[3]/div[1]/h1/text()')[0].strip()
except:
name = None
#项目简介
ps = html.xpath('//*[@id="parent-content"]/div/div[3]/div[5]/div[2]/div')
for p in ps:
try:
xmjj = p.xpath('./p[1]/text()')[0].strip()
except:
xmjj = None
infos = html.xpath('//*[@id="parent-content"]/div/div[3]/div[5]/div[1]/div/table/tbody')
for info in infos:
#行政区域
try:
xzqy = info.xpath('./tr[1]/td[1]/text()')[0].strip()
except:
xzqy = None
#物业类型
try:
wylx = info.xpath('./tr[2]/td[1]/text()')[0].strip()
except:
wylx = None
#销售价格
try:
xsjg = info.xpath('./tr[3]/td[1]/text()')[0].strip()
except:
xsjg = None
······
data = {
'xmzt':xmzt,
'name':name,
'xzqy':xzqy,
······
'qy':qy
}
print(data)
解析完数据后,将其置于字典中,打印结果如下: 然后追加保存为csv:
然后追加保存为csv:
try:
with open('hz_newhouse.csv', 'a', encoding='utf_8_sig', newline='') as fp:
fieldnames = ['xmzt','name','xzqy',······,'qy']
writer = csv.DictWriter(fp, fieldnames = fieldnames)
writer.writerow(data)
except Exception:
print(traceback.print_exc())
当然,我们也可以读取csv文件,并写入Excel:
df = pd.read_csv("newhouse.csv",names=['name','xzqy','wylx',······,'state'])
df = df.drop_duplicates()
df.to_excel("newhouse.xlsx",index=False)
总结
本文基于Python爬虫技术,提供了一种更直观的抓取新房数据的方法。
不建议抓取太多,容易使得服务器负载,浅尝辄止即可。
如需本文完整代码,后台回复「新房」两个字即可获取。
**-----**------**-----**---**** End **-----**--------**-----**-****
往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/8xrV4JlgaUnbyp4bNYvZ-w,如有侵权,请联系删除。











