
作者
tomdu,腾讯云高级工程师,主要负责宙斯盾安全防护系统管控中心架构设计和后台开发工作。
导语
宙斯盾 DDoS 防护系统作为公司级网络安全产品,为各类业务提供专业可靠的 DDoS/CC 攻击防护。在黑客攻防对抗日益激烈的环境下, DDoS 对抗不仅需要“降本”还需要“增效”。随着云原生的普及,宙斯盾团队持续投入云原生架构改造和优化,以提升系统的处理能力及效率。本文主要介绍宙斯盾防护调度平台上云过程实践与思考。
为什么上云?
云原生作为近年来相当热门的概念,无论在公司内各部门,还是公司外各大同行友商,都受到追捧。云原生涉及技术包括容器、微服务、 DevOps 、持续交付等,这些新的技术和理念能带来哪些收益?在我们看来,
资源共享,动态扩缩容——“降本”
以宙斯盾防护调度平台为例,因为以前申请的物理机资源还在服役期,所以当前大部分后台服务还是运行在物理机。申请时会适当预留 buffer (资源消耗跟外部攻击威胁有关,波峰波谷相差可达十倍)。这部分 buffer 虽然作为 backup ,但同时大部分时间处于空闲状态,物理机也不便于跨系统、项目共享。在资源上云阶段, CVM 已经对物理机做了虚拟化,一定程度上实现资源共享。随着容器化管理平台的出现,资源控制粒度更细。例如在 TKE 平台上,一个容器分配的资源可以精确到0.1核 CPU 、1 MB 内存,根据负载随时扩缩容。同时所有资源作为一个大池子来共享,减少资源浪费。
容器化管理,快速部署——“增效”
要提升迭代速度,除了开发环节,测试、发布、运维都需要做优化。原来物理机部署时,需要运维同学手工或者通过专门的运维发布平台来完成发布,期间还可能因为机器环境的差异出现发布失败或者异常,需要人工处理。现在通过容器化部署,可以保证服务的运行环境一致性,避免“雪花服务器”。同时借助容器管理平台,可以实现一键发布、快速扩缩容,通用的容器容灾策略为服务的稳定性提供了基本保证。
怎么上云?
当前架构
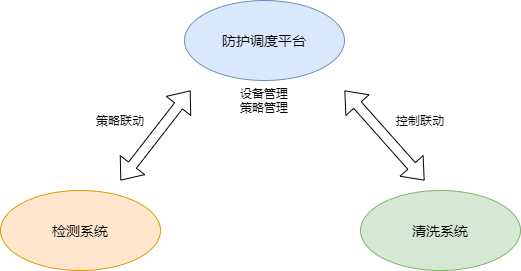
如上图所示, DDoS 防护流程包括攻击检测(发现攻击)和攻击防护(攻击流量清洗及正常流量回源)。
在这个过程中,还需要一个主控“大脑”来协调检测系统和防护系统,以实现全流程的自动化处理——这个“大脑”就是防护调度平台。在检测到 DDoS/CC 攻击时,防护调度平台会自动化决策需要调用的防护设备机房、数量、以及需要下发的防护策略,遇上强对抗时还需要实时调整防护设备上的防护策略,其重要程度可见一斑。
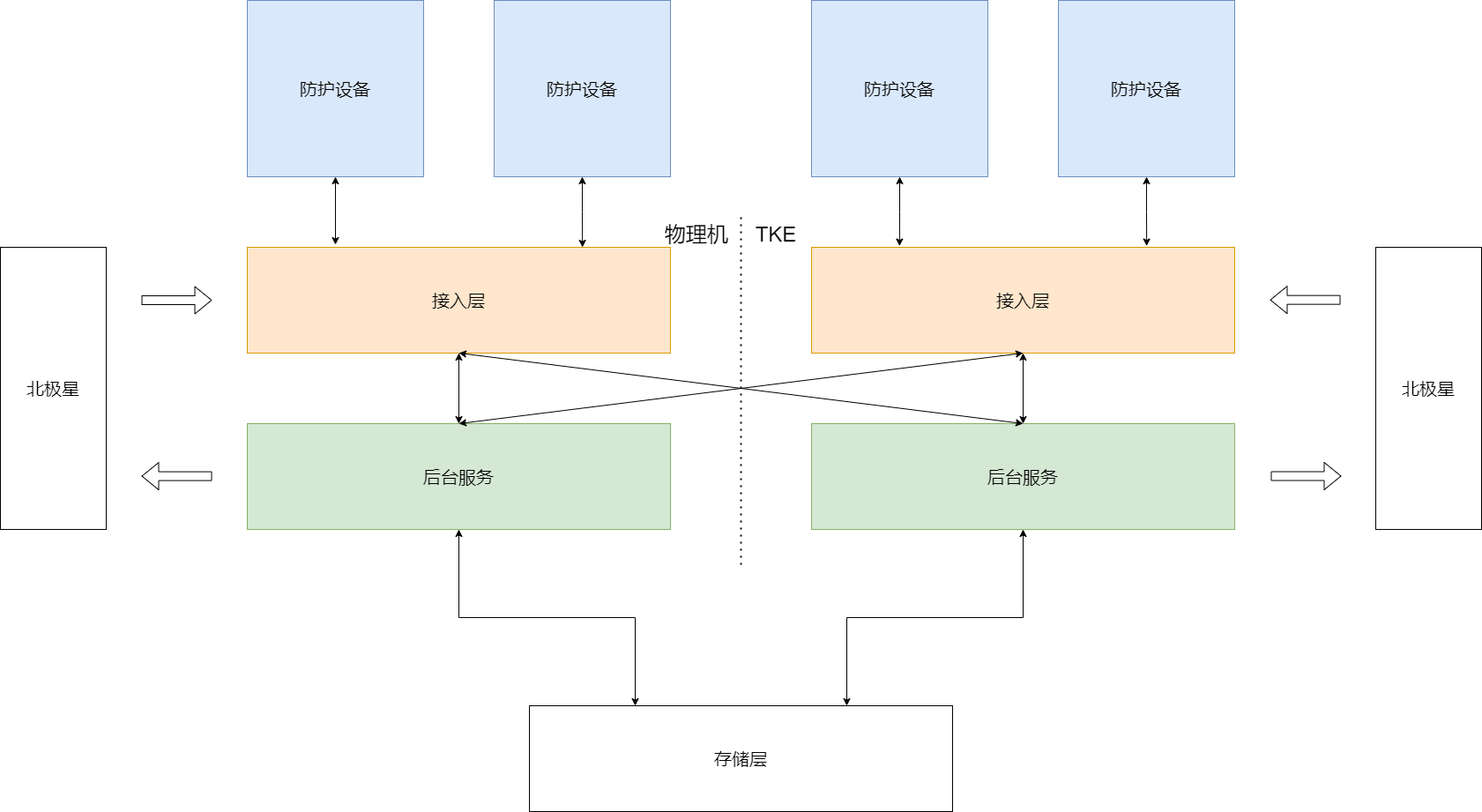
当前防护调度平台整体架构如下图所示。
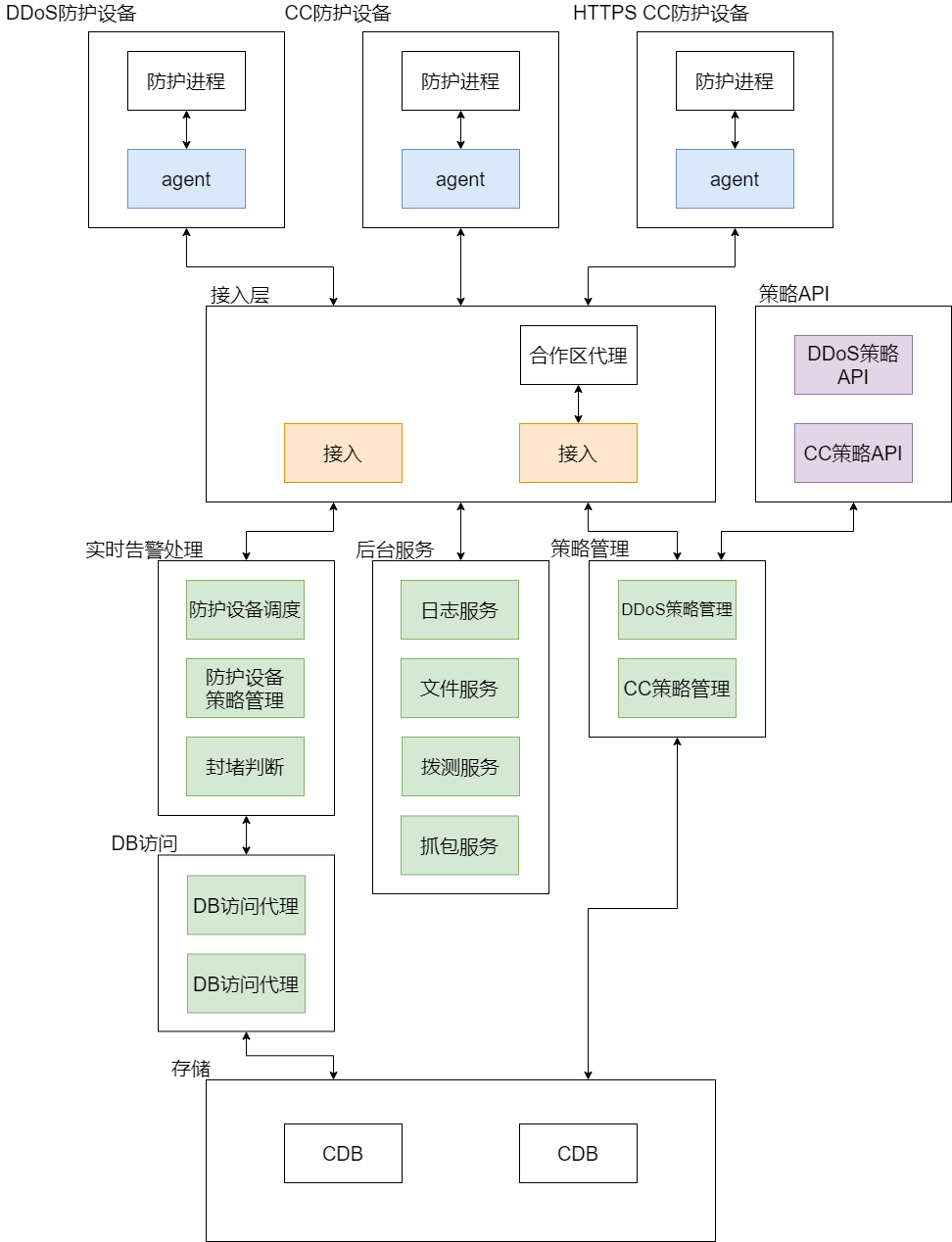
- 防护设备:分为 ADS ( Anti-DDoS System )、 HTTP CC 、 HTTPS CC 三大类,结合多年来团队在 DDoS/CC 攻防对抗上的积累,分别集成了各种协议/场景下的自研防护算法。防护设备部署在全球各地机房入口,在触发攻击告警后牵引并清洗攻击流量,然后回源。其上部署有管控 agent ,负责与后台通信、并管理防护设备。
- 接入层:多点接入,内网、公网接入。管控 agent 启动后随机选择一个可用接入进行 TCP 连接。
- 后台服务:多主/主备部署,向接入注册心跳,所有后台请求通过接入分发、负载均衡,所有 agent 请求通过接入转发。
如果按照当前架构直接部署到 TKE 上,系统是可以运行起来,但是由于机器部署和容器部署的特性不同,直接部署总会有些冲突、别扭的地方。考虑方案时,我们觉得当前架构不适应 TKE 部署的主要地方有:
- 服务发现:后台服务根据预配置的接入 IP 列表注册心跳,容器化部署后 IP 切换频繁,通过配置的方式加载接入已经不适用。
- 无状态:容器化部署可以做到根据负载快速扩容,但需要服务做到完全无状态才能达到完全水平扩展。当前多主部署的服务都是无状态的,可以直接迁移,但主备部署的服务则需要改造。
- 配置管理:当前按机器维度管理,与运行环境相关/无关的配置混在一起。
同时,借着这次上云的机会,我们也希望对系统架构做一次大的优化,接入公司成熟的公共服务如北极星名字服务、七彩石配置中心、智研,提升研效。
上云架构
基于当前架构,除了把服务做镜像打包、迁移到 TKE 上部署,同时对不适应的地方做改造、优化。改造后的大致架构及流程如下:
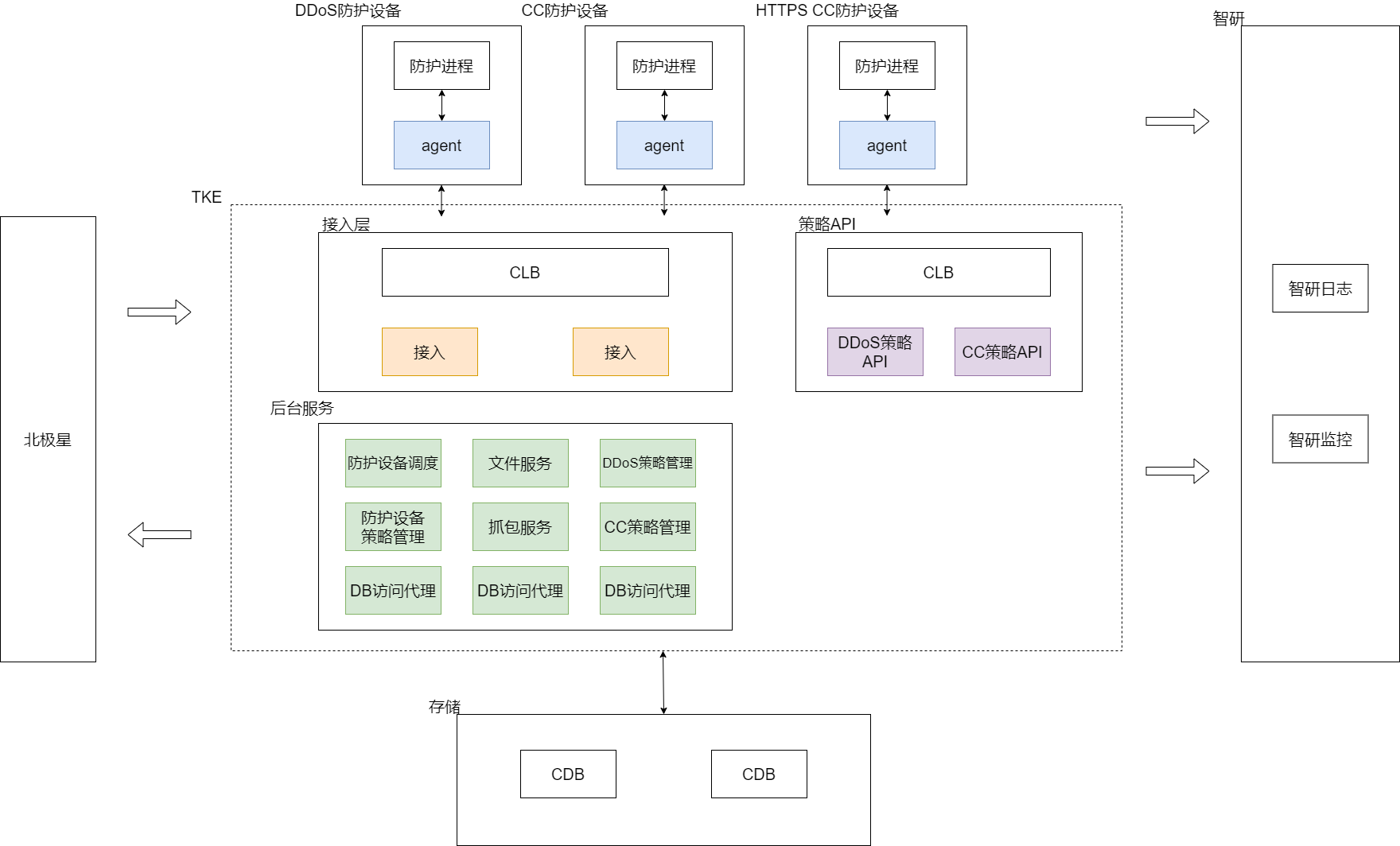
- 服务发现:后台服务全部接入北极星名字服务,向北极星注册实例、定期发送心跳,接入从北极星获取各类服务健康实例来分发请求。
- 无状态:当前系统存在状态的场景主要有两类。
- 文件下载:主要是防护设备的策略文件下载,无状态化改造涉及待下载文件在多个文件服务实例间同步。解决方案是选择使用 CFS 来同步文件。
- 策略分包下发:策略太大时应用层做了分包,同一请求哈希到同一后台策略服务实例。解决方案是请求中带上当前分包状态信息,任一策略服务实例可以处理且结果一致。
- 配置管理:与运行环境无关的配置,接入七彩石配置中心,保证同一类型部署的实例配置一致。
- 日志监控:迁移到智研日志汇、监控宝。
两大“拦路虎”
如何平滑迁移
当前物理机环境稳定运行,计划逐步灰度、切量到TKE环境,因此会有一段时间是物理机+ TKE 混跑的状态。管控接入、后台服务迁移 TKE ,对于防护设备 agent 是透明的。因为防护设备 agent 只会选择一个可用接入建立连接,即 agent 只会连到物理机环境或 TKE 环境,因此后台服务与 agent 交互时,混跑状态下涉及物理机环境和 TKE 环境互访的情况。这种情况 TKE 提供了灵活的配置支持。
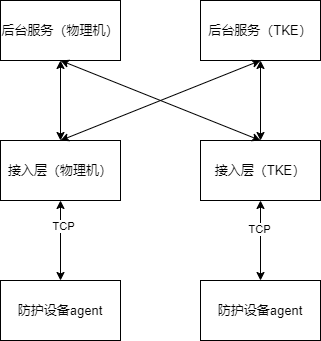
在 TKE 上部署服务时,提供了两种网络模块:
- Global Route : VPC 内私有 IP ,无法从集群外访问,不可以注册到 CMDB 。开启随机端口映射后可从集群外访问,并可绑定 CLB 和北极星。
- ENI IP :公司内可路由 IP ,可从集群外访问,可以注册 CMDB 、 CLB 和北极星。
在混跑灰度期间,接入部署选择 ENI IP 的方式,物理机后台服务访问 TKE 接入跟访问普通内网服务无异。迁移完成后,后台服务改用 Global Route 的方式,仅允许集群内互访。后台服务间通过原生的 service 访问,对外只通过 CLB 暴露服务。
不断变化的 IP
由于 DDoS 攻防对抗的业务特性,我们长期跟 IP 打交道,对 IP 有一种特殊的情节。在内部交流中,我们发现大家在迁移 TKE 过程中都会遇到一些共性问题。其中,跟 IP 相关的问题就会经常被提及。
在物理机部署环境,机器 IP 是固定的且变化频率较低(几年一次的机器裁撤)。但是在 TKE 环境,重启一次服务,分配到的容器 IP 、节点就可能变了,导致系统中依赖 IP 实现的功能无法很好适应 TKE 环境。
访问鉴权
比较简单的鉴权是基于源 IP 加白,如接口访问、 DB 访问。对于接口访问,我们定义了一套基于 JWT 的接口鉴权规范,所有对外接口不再使用源 IP 加白的方式。对于 DB 访问,当前是使用不限源的独立 DB 账号,并对权限做更细的划分(精确到表)。后续 DB 权限支持实时申请,当容器起来以后通过接口申请当前容器所在节点的访问权限。
服务发现
原来的架构中,管控接入层实现了简单的服务注册、服务发现功能,后台服务通过 IP 配置来注册、上报心跳。如果接入层不迁移到 TKE 、继续保持相对固定,那么这套方案还是可行的。但是,接入层迁移到 TKE 后,自身的部署节点也在不断变化,因此需要一个独立与接入、相对固定的服务注册与发现模块。集群内部署的服务可以使用 K8s / TKE 原生的 service ,对于物理机和 TKE 混跑的情况则可以考虑北极星名字服务。
服务暴露
这里包含两层含义,一个是该暴露给外部的服务如何保持稳定,另一个是不该暴露给外部的服务如何隐藏起来。
(1)暴露服务给外部
在物理机环境,机器裁撤导致服务IP变化就是经常出现的问题,通过域名、 VIP 都可以解决。在 TKE 上,通过 CLB 来实现。
(2)隐藏内部服务
通过 VPC 内私有 IP ,就能保证服务无法从集群外访问,实现隔离。
我们系统的最终目标是:所有对外服务通过接入层暴露出去,做好鉴权;内部的后台服务都隐藏起来,保证安全性。
上云效果
防护调度平台上云之后,
(1)在降低成本方面,预计资源使用率可以达到50%以上。之前为了保证 DDoS 攻击峰值时能正常运行而预留的一大部分资源,闲时放到整个大资源池里共享,忙时动态扩容。
(2)在部署效率方面,部署、扩容耗时从天降到分钟。原来需要运维同学专人专职完成发布,上 TKE 后只需开发同学简单配置即可完成。同时,随着业务场景的快速变化,通过 TKE 满足了我们对高防、网关、第三方云等场景的快速部署和扩容。
随着公司内云上服务越来越丰富,通过上云和接入公共服务,优化宙斯盾防护调度平台的架构,从而提升系统扩展性和迭代效率。 另外,宙斯盾的核心能力是 DDoS 、 CC 防护,除了管控上云,我们也正在探索防护能力虚拟化的可能性,为云上各种业务、场景提供灵活、弹性的防护能力。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。











