
作者
黄雷,腾讯云高级工程师,曾负责构建腾讯云云监控新一代多维业务监控系统,擅长大规模分布式监控系统设计,对 golang 后台项目架构设计有较深理解,后加入TKE团队,致力于研究 Kubernetes 相关运维技术,拥有多年 Kubernetes 集群联邦运维管理经验,目前在团队主要负责大规模集群联邦可观测性提升,主导研发了腾讯云万级 Kubernetes 集群监控告警系统,智能巡检与风险探测系统。
摘要
如果问笔者,在管理 Kubernetes 集群的时候,有什么开源组件是一定会用的,那笔者觉得 Prometheus 一定会是其中之一。Prometheus 拥有强劲的性能,活跃的生态,便捷的部署方式,还有灵活的 PromQL,特别适合用于 Kubernetes 场景下的 master,节点,应用等各个层级的监控数据采集和聚合,再配合炫丽的 Grafana 面板(如下图),可谓是云原生监控的最佳方案。
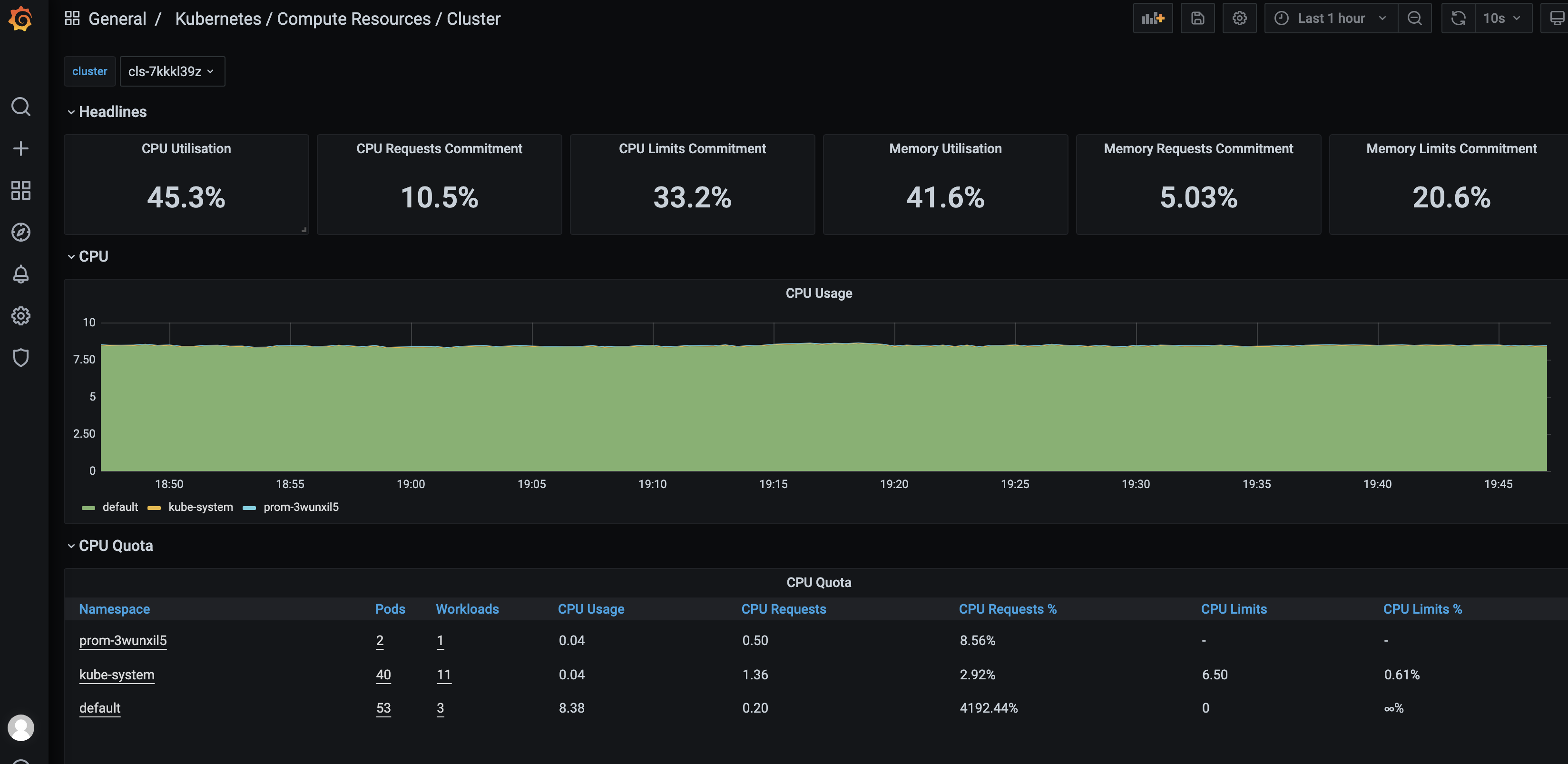
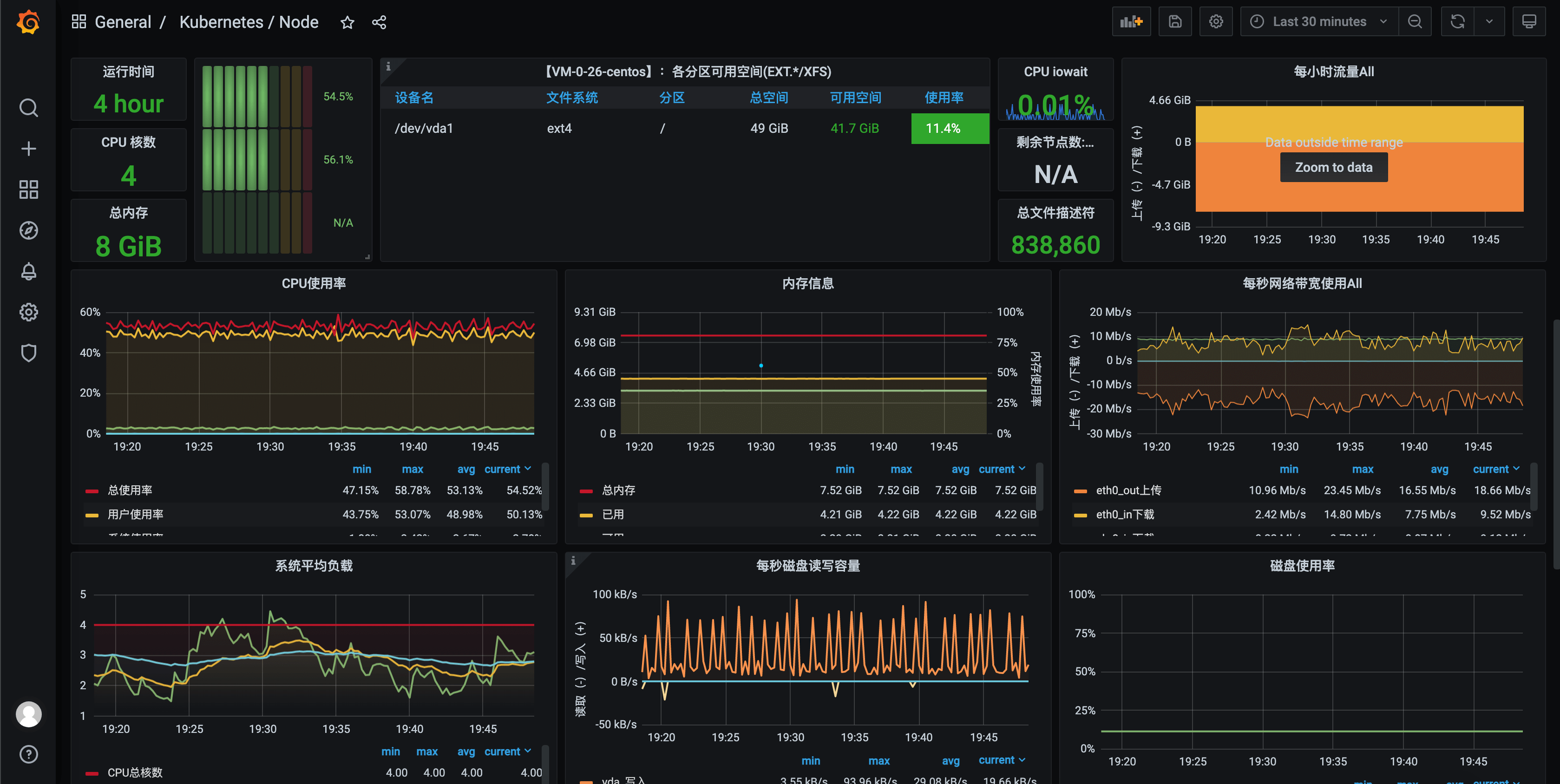
固然 Prometheus 和 Grafana 十分强大,但是刚接触的时候,还是有一定的学习成本,不易上手,这点笔者特别有感触。记得几年前笔者还未负责团队云原生可观测性提升的时候,就经常听到边上一刚接触 Prometheus 的哥们成天和笔者吐槽,“哎,Prometheus 的语法怎么这么复杂”,“这东西太恶心了,这怎么写啊”。当时笔者还嘲笑他夸张,但当我也开始学习 Prometheus,开始配 Grafana 面板的时候,也发出过一样的吐槽声,例如下边的语句。
max(label_replace(
label_replace(
label_replace(
kube_deployment_status_replicas_unavailable,
"workload_kind","Deployment","","")
,"workload_name","$1","deployment","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)")
)
by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__) max(label_replace(
label_replace(
label_replace(
kube_daemonset_status_number_unavailable,
"workload_kind","DaemonSet","","")
,"workload_name","$1","daemonset","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__)
max(label_replace(
label_replace(
label_replace(
(kube_statefulset_replicas - kube_statefulset_status_replicas_ready),
"workload_kind","StatefulSet","","")
,"workload_name","$1","statefulset","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__)
max(label_replace(
label_replace(
label_replace(
(kube_job_status_failed),
"workload_kind","Job","","")
,"workload_name","$1","job_name","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)
or on (namespace,workload_name,workload_kind, __name__)
max(label_replace(
label_replace(
label_replace(
(kube_cronjob_info * 0),
"workload_kind","CronJob","","")
,"workload_name","","cronjob","(.*)"),
"__name__", "k8s_workload_abnormal", "__name__","(.*)") ) by (namespace, workload_name, workload_kind,__name__)笔者这几年在使用 Prometheus 的过程中积累了一定实践经验,也踩了不少坑。
为了让想要学习 Prometheus 的读者朋友更加快速的入门,少走弯路,提升云原生时代业务监控技能。
笔者整理并总结了一版教程,包括一些最基本,最核心的概念,技巧以及最佳实践分享给大家,让大家用 20% 的时间掌握 80% 最常用的部分。
学会如何从零开始给自己的业务暴露监控指标,如何正确配置服务发现,以及如何配出实用的 Grafana 面板,带领读者光速入门 Prometheus+Grafana,掌握云原生监控的正确姿势。图片
「腾讯云原生」公众号后台回复“ Prometheus”或“光速入门”即可获取教程!一起学起来吧!
小Tips:教材目前有网站版本(需在浏览器中打开)和PDF版本,童鞋们可根据自身需求进行查看。本教材网站版本会持续进行更新,大家可以持续关注~
同时欢迎大家给教程提issue, 此教程会根据大家的反馈不定时更新,扩展,修订!

(提issue的GitHub地址)
教材目录如下














