
摘要
在这篇文章中,我将从消息在Kafka中的物理存储方式讲起,介绍分区-日志段-日志的各个层次。
然后我将接着上一篇文章的内容,把消费者的内容展开讲一讲,区分消费者与消费者组,以及这么设计有什么用。
根据消费者的消费可能引发的问题,我将介绍Kafka中的位移主题,以及消费者要怎么提交位移到这个位移主题中。
最后,我将聊一聊消费者Rebalance的原因,以及不足之处。
1. log
在上一篇文章中,我们提到了“partition”的概念。
我们那个时候所表达的意思是,消息的生产跟消费是处于topic中的partition这个维度的,而不是位于主题的维度。
也就是说,我们那个时候对Kafka的理解,是处在topic下的每个parititon,都有一个称为“队列”的数据结构,所有送往这个主题的消息,会被分配到其中的一个parititon中。
这样的设计可以避免消息队列的性能在IO上具有瓶颈。
在这一节中,我们将进一步的解释Kafka的消息储存方式。
我们所理解的“消息”,在Kafka中被称为日志。
在每一个broker中,保存了多个名字为{Topic}-{Parititon}的文件夹,例如Test-1、Test-2。
这里的意思是,这个broker中能够处理topic为Test,分区为1和2的消息。
但是注意,对于“parititon”这个名词来说,他也是一个逻辑上的概念,对应在broker中只是一个文件夹,那么什么才是物理意义上的概念呢,我们接着往下看。
在{Topic}-{Parititon}的文件夹内部,包含了很多很多的文件,里面的文件名都是64位的长整数。
例如:
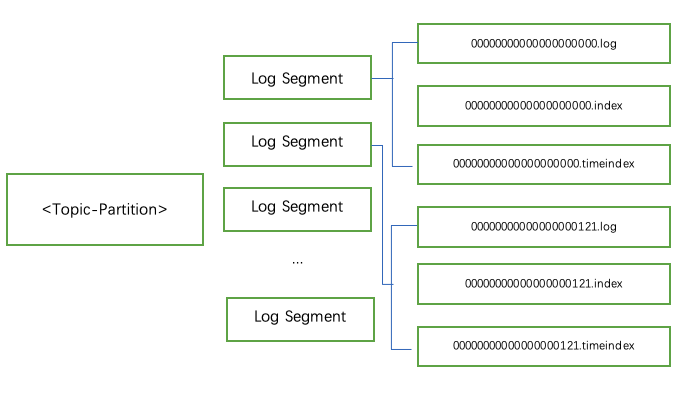
在这张图中,一个分区,包含了多个Log Segment。注意,这里的Log Segment也是逻辑上的概念,只有具体到具体的日志文件,才是物理上的概念。
我们看图片最右边的部分,文件名都是20位的整数,这个数字称为消息的“基准偏移量”。例如我们第二个Log Segment是从121开始的,那么代表了这个日志段的第一条消息的偏移量是从121开始的,也代表了在这之前有121条日志记录。
注意,因为我们的偏移量是从0开始的,所以在121这个偏移量之前有121条数据,而不是120条。
然后我们再聊聊文件的格式,我们看到这里有三种类型的文件,*.log、*.index、*.timeindex。
log格式的文件记录了消息,index是偏移量索引,timeindex是时间戳索引。但是这个我们不展开聊,这篇文章的定位还是偏向于了解各个组件。
如此一来,broker在接收到生产者发过来的消息的时候,需要将消息写在最后的Log Segment中。这样还带来了一个好处,消息的写入是顺序的IO。也因为如此,最后的一个Log Segment,被称为“active Log Segment”。
2. 消费者与消费者组
在上一篇文章中,我们只提到了“消费者”这个概念。
同样在本文中,我们将更深入更准确的了解位于Kafka中的“消费者”。
其实在Kafka中,消费者是以消费者组的形式对外消费的。
我们作一个假设,假设没有消费者组这种概念,我们现在有10个消费者订阅了同一个主题,那么当这个主题有新的消息之后,我们这10个消费者是不是应该去“抢消息”进行消费呢?
这是一种浪费资源的表现。
所以消费者组,也可以认为是一种更加合理分配资源,进行负载均衡的设计。
假设有5个消费者属于同一个消费者组,这个消费者组订阅了一个具有10个分区的主题,那么组内的每一个消费者,都会负责处理2个分区的消息。
这样,能够保证当一条消息发送到主题中,只会被一个消费者所消费,不会造成重复消费的情况。
此外,消费者组的设计还能够令我们很方便的横向扩展系统的消费能力。设想一下在我们发觉系统中消息堆积越来越多,消费速度跟不上生产速度的时候,只需要新增消费者,并且将这个消费者划入原来的消费者组中,Kafka会自动调整组内消费者对分区的分配,这个过程称为重平衡,我们在后面会提到。
但是需要注意的是,组内消费者的数量不能超过主题的分区数目。否则,多出的消费者将会空闲。例如一个主题具有10个分区,而组内有11个消费者,那么这多出来的一个消费者将空闲。
Kafka这样的设计是为了同一个分区只能够被一个消费者所消费,这个跟位移管理有关,我们在后文会提到。
另外,Kafka还支持多个消费者组订阅同一个主题,这样,相同的消息将被发送到所有订阅了这个主题的消费者组中。
注意:我们说到了同一分区只能被同一个消费者消费,但是这个说法的前提是这些消费者位于同一个消费者组。也就是说,不同消费者组内的消费者,是可以消费同一个主题分区的。
所以,我们也可以认为Kafka的消费者组,是为了实现点对点以及广播这两种方式的消息传递。
3. 位移主题
我们在上一个小节提到了消费者组内的消费者对分区内的信息进行消费,并且存在了消费者的加入与退出这种情况。
所以在这节我们来聊聊Kafka是怎么做到在消费者有变动的情况下,消息不会丢失或者重复消费。
我们可以很容易的想到,只要记录下消费过的位移,就能够实现上述的目标了。
我们直接聊聊位移主题这种方式,不管以前的将位移保存在zk中的实现方式。
在Kafka中有一种特殊的主题,称为位移主题,在Kafka中的主题名称是__consumer_offsets。
因为位移主题也是一个主题,所以也符合Kafka中主题的各种特性,我们可以随意的发送消息,拉取消息,删除主题。但是因为这个主题的数据是kafka设计好的,所以不能随意的发送消息过去,否则在broker端不能解析的话,就会造成崩溃。
然后我们讨论一下发往位移主题的消息格式。因为我们是希望保存位移,所以很容易会想到这是一个KV结构。那么Key中应该保存哪些消息呢?
Key中包含了主题名,分区名,消费者组名。
其实在这里是不需要保存消费者id之类的信息的,也就是说只需要具体到是哪个消费者组在哪个主题的哪个分区消费了多少数据,就足够了。为什么呢?因为我们上文也提到了,消费者是可能发生变动的,我们的目的是让消费者发生变动后,能知道从哪里继续消费。因此,位移信息的精确度到消费者组级别,就足够了。
并且,在Value中,只需要保存消费位移,就足够了。
说完了位移信息是怎么保存的,我们再来聊聊位移主题本身。因为位移主题也是一个主题,所以必然也会有分区,也会有副本。那么消费者在消费了信息之后,该把位移发送到哪呢?
Kafka中的位移主题会在第一个消费者被创建的时候创建,默认会有50个分区。消费者在提交位移的时候,会根据自己组id的hash值模位移主题的分区数,所得到的结果就是位移信息该提交的分区id,然后找到这个分区id的leader节点,将位移信息提交到这个leader节点所在的broker中。
4. 位移的提交
聊了位移主题,我想你大概明白Kafka关于位移状态的保存了,那么在这一节中,我们来聊聊位移是怎么被提交的。
在说到位移的提交之前需要明确的是:虽然有了位移主题这样的设计,但是并不代表了消息一定不会被重复消费,也不代表消息一定不会丢失。
另外,Kafka会严格的执行位移主题中所提交的信息。例如已经消费了0-20的消息,如果你提交的位移是100,那么下一次拉取的信息一定是从100开始的,20-99的消息将会丢失。又比如你提交的位移是10,那么10-20的消息将会被重复消费。
在Kafka中,位移的提交有两种方式,一种是自动提交,一种是手动提交。
4.1 自动提交
位移的自动提交是在POLL操作的时候进行的。
在消费者POLL拉取最新的消息之前,会先判断目前是否已经到了提交位移的Deadline时间点,如果已经到了这个时间,则先进行位移的提交,然后再拉取信息。
注意,这里可能会发生如下的情况:
在某一时刻提交了位移100,随后你拉取了100-150的消息,但是还没有到下一次提交位移的时候,消费者宕机了。可能这个时候只消费了100-120的消息,那么在消费者重启后,因为120的位移没有提交,所以这部分的消息会被重复消费一次。
再设想一种情况,你拉取了100-150的消息,这个时候到了自动提交的时间,提交了150的这个位移,而这个时候消费者宕机了,重启之后会从150开始拉取信息处理,那么在这之前的信息将会丢失。
4.2 手动提交
对于因为自动提交而造成的信息丢失和重复消费,你可以采取手动提交的方式来避免。
手动提交又分为同步提交和异步提交两种提交方式。
同步提交会直到消息被写入了位移主题,才会返回,这样是安全的,但是可能造成的问题是TPS降低。
异步提交是触发了提交这个操作,就会返回。这样速度是很快的,但是可能会造成提交失败的情况。
5. Rebalance
我们在上面的内容中提到过这么一种情况:
消费者组内的成员增减,导致组内的成员需要重新调整他需要负责的消费的分区。
这种情况我们称为“Rebalance”,或者称为“重平衡”。
用专业一点的话来下定义就是:某个消费组内的消费者就如何消费某个主题的所有分区达成一个共识的过程。
但是这个过程对Kafka的吞吐率影响是巨大的,因为这个过程有点像GC中的STW(世界停止),在Rebalance的时候,所有的消费者只能去做重平衡这一件事情,不能消费任何的消息。
下面我们来说说哪些情况可能会导致Rebalance:
- 组内成员数量发生了变化
- 订阅主题的数量发生了变化
- 订阅主题的分区数量发生了变化
而且在Rebalance的时候,假设有消费者退出了,导致多出了一些分区,Kafka并不是把这几个多出来的分区分配给原来的那些消费者,而是所有的消费者一起参与重新分配所有的分区。
当有新的消费者加入的时候,也不是原本的每个消费者分出一些分区给新的消费者,而是所有的消费者一起参与重新分配所有的分区。
这样的分配策略听起来就很奇怪且影响效率,但是没有办法。
不过社区新推出了StickyAssignor(粘性分配)策略,就可以做到我们上面假设的情况,但是目前还存在一些bug。
写在最后
首先,谢谢你能看到这里!
关于Kafka的前两篇文章,我认为都是科普性质的,希望可以用比较简单的方式给你梳理一遍Kafka具有的功能,以及各个功能的运作方式。
在后面的文章中,我也希望能够比较清晰易懂的给你介绍Kafka的一些原理之类的东西。
因为作者也刚开始研究Kafka,很多地方的理解可能还是不到位的,所以在这期间如果你发现有什么问题,或者有哪些地方是我解释的不好的,请留言告诉我,谢谢你!
再次感谢你能看到这里!
PS:如果有其他的问题,也可以在公众号找到我,欢迎来找我玩~










