kafka消费者在消费的时候对于位移提交的具体时机的把握也很有讲究,有可能会造成重复消费和消息丢失的现象。
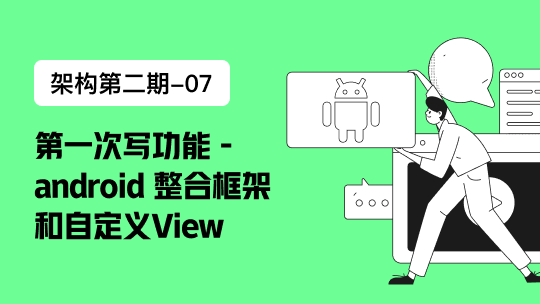
参考上图,当前一次 poll() 操作所拉取的消息集为 [x+2, x+7],x+2 代表上一次提交的消费位移,说明已经完成了 x+1 之前(包括 x+1 在内)的所有消息的消费,x+5 表示当前正在处理的位置。如果拉取到消息之后就进行了位移提交,即提交了 x+8,那么当前消费 x+5 的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从 x+8 开始的。也就是说,x+5 至 x+7 之间的消息并未能被消费,如此便发生了消息丢失的现象。
再考虑另外一种情形,位移提交的动作是在消费完所有拉取到的消息之后才执行的,那么当消费 x+5 的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从 x+2 开始的。也就是说,x+2 至 x+4 之间的消息又重新消费了一遍,故而又发生了重复消费的现象。
而实际情况还会有比这两种更加复杂的情形,比如第一次的位移提交的位置为 x+8,而下一次的位移提交的位置为 x+4这种情况。
在 Kafka 中默认的消费位移的提交方式是自动提交,这个由消费者客户端参数 enable.auto.commit 配置,默认值为 true。当然这个默认的自动提交不是每消费一条消息就提交一次,而是定期提交,这个定期的周期时间由客户端参数 auto.commit.interval.ms 配置,默认值为5秒,此参数生效的前提是 enable.auto.commit 参数为 true。在代码清单8-1中并没有展示出这两个参数,说明使用的正是默认值。
在默认的方式下,消费者每隔5秒会将拉取到的每个分区中最大的消息位移进行提交。自动位移提交的动作是在 poll() 方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。
在 Kafka 消费的编程逻辑中位移提交是一大难点,自动提交消费位移的方式非常简便,它免去了复杂的位移提交逻辑,让编码更简洁。但随之而来的是重复消费和消息丢失的问题。假设刚刚提交完一次消费位移,然后拉取一批消息进行消费,在下一次自动提交消费位移之前,消费者崩溃了,那么又得从上一次位移提交的地方重新开始消费,这样便发生了重复消费的现象(对于再均衡的情况同样适用)。我们可以通过减小位移提交的时间间隔来减小重复消息的窗口大小,但这样并不能避免重复消费的发送,而且也会使位移提交更加频繁。
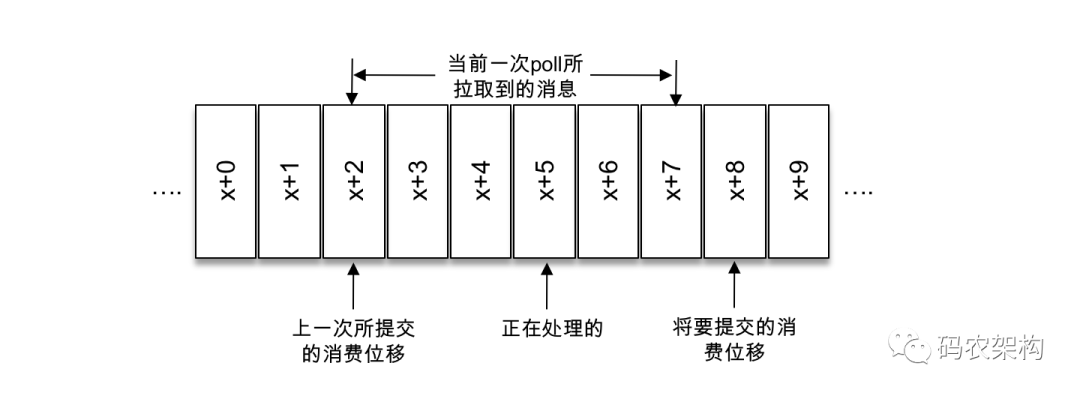
按照一般思维逻辑而言,自动提交是延时提交,重复消费可以理解,那么消息丢失又是在什么情形下会发生的呢?
结合上图中的情形。拉取线程A不断地拉取消息并存入本地缓存,比如在 BlockingQueue 中,另一个处理线程B从缓存中读取消息并进行相应的逻辑处理。假设目前进行到了第 y+1 次拉取,以及第m次位移提交的时候,也就是 x+6 之前的位移已经确认提交了,处理线程B却还正在消费 x+3 的消息。此时如果处理线程B发生了异常,待其恢复之后会从第m此位移提交处,也就是 x+6 的位置开始拉取消息,那么 x+3 至 x+6 之间的消息就没有得到相应的处理,这样便发生消息丢失的现象。
自动位移提交的方式在正常情况下不会发生消息丢失或重复消费的现象,但是在编程的世界里异常无可避免,与此同时,自动位移提交也无法做到精确的位移管理。在 Kafka 中还提供了手动位移提交的方式,这样可以使得开发人员对消费位移的管理控制更加灵活。很多时候并不是说拉取到消息就算消费完成,而是需要将消息写入数据库、写入本地缓存,或者是更加复杂的业务处理。在这些场景下,所有的业务处理完成才能认为消息被成功消费,手动的提交方式可以让开发人员根据程序的逻辑在合适的地方进行位移提交。开启手动提交功能的前提是消费者客户端参数 enable.auto.commit 配置为 false。
手动提交可以细分为同步提交和异步提交,对应于 KafkaConsumer 中的 commitSync() 和 commitAsync() 两种类型的方法
该方法提供了一个 offsets 参数,用来提交指定分区的位移。无参的 commitSync() 方法只能提交当前批次对应的 position 值。如果需要提交一个中间值,比如业务每消费一条消息就提交一次位移,那么就可以使用这种方式。
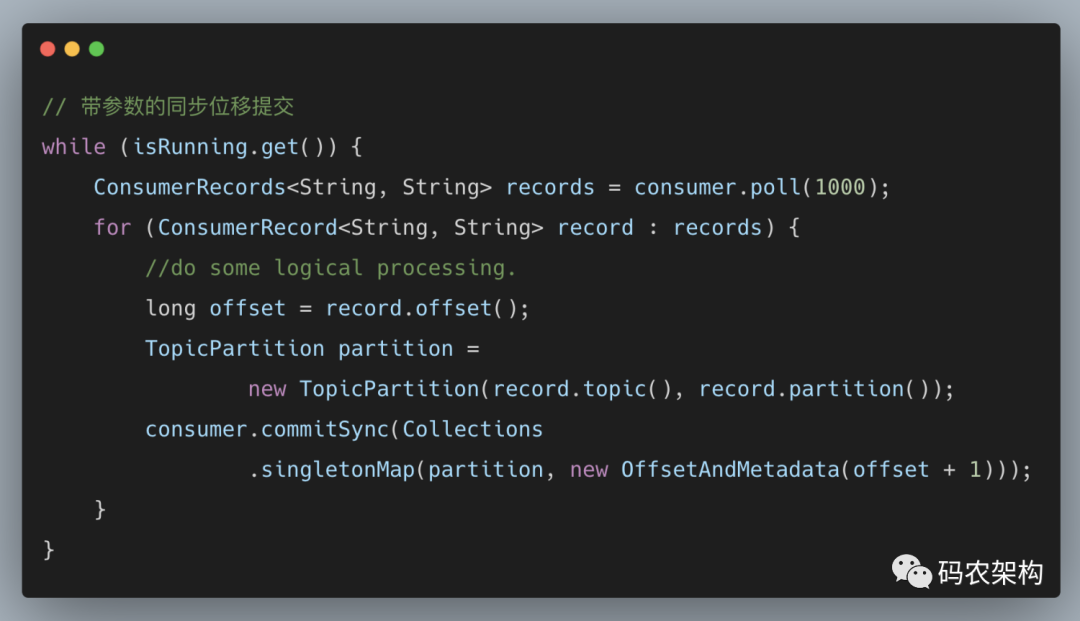
在实际应用中,很少会有这种每消费一条消息就提交一次消费位移的必要场景。commitSync() 方法本身是同步执行的,会耗费一定的性能,而示例中的这种提交方式会将性能拉到一个相当低的点。更多时候是按照分区的粒度划分提交位移的界限,这里我们就要用到了第10节中提及的 ConsumerRecords 类的 partitions() 方法和 records(TopicPartition) 方法(修改自 KafkaConsumer 源码中的示例)。
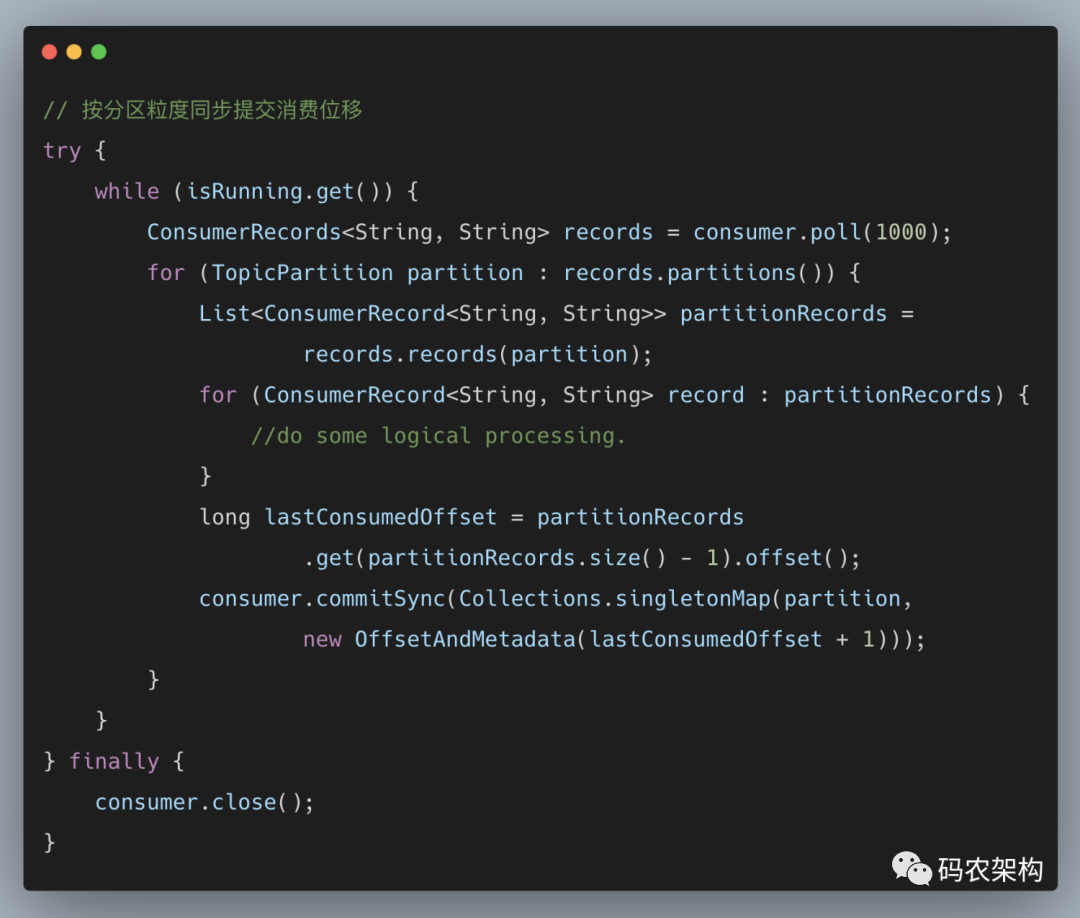
与 commitSync() 方法相反,异步提交的方式(commitAsync())在执行的时候消费者线程不会被阻塞,可能在提交消费位移的结果还未返回之前就开始了新一次的拉取操作。异步提交可以使消费者的性能得到一定的增强。commitAsync 方法有三个不同的重载方法,具体定义如下:
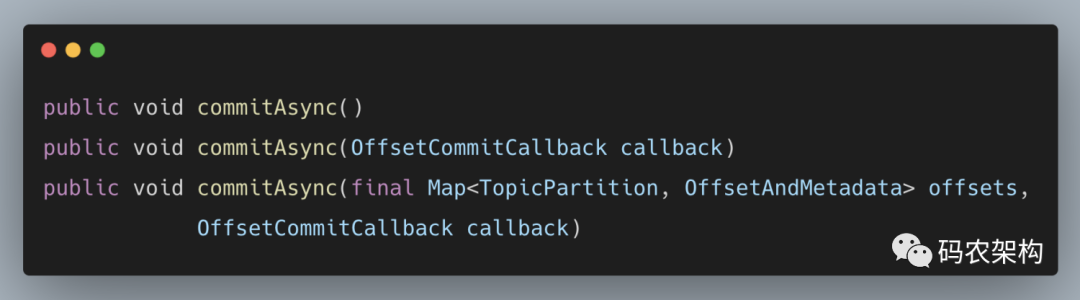
第一个无参的方法和第三个方法中的 offsets 都很好理解,对照 commitSync() 方法即可。关键的是这里的第二个方法和第三个方法中的 callback 参数,它提供了一个异步提交的回调方法,当位移提交完成后会回调 OffsetCommitCallback 中的 onComplete() 方法。这里采用第二个方法来演示回调函数的用法,关键代码如下:
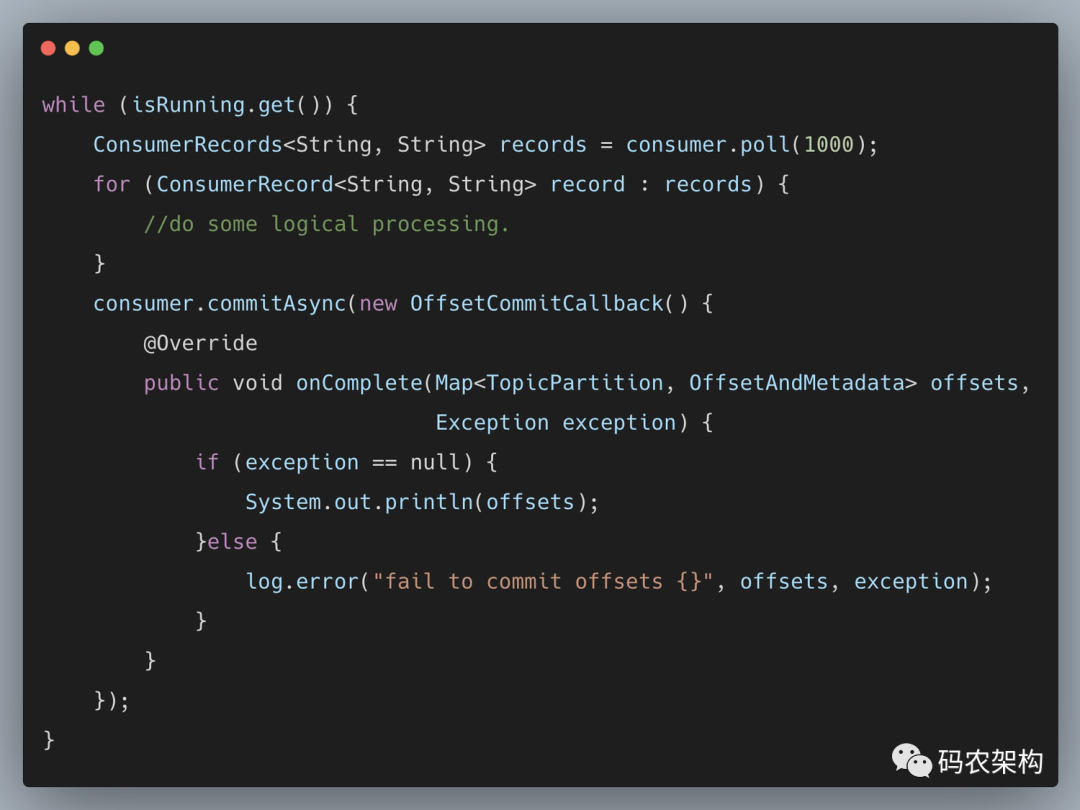
commitAsync() 提交的时候同样会有失败的情况发生,那么我们应该怎么处理呢?读者有可能想到的是重试,问题的关键也就在这里了。如果某一次异步提交的消费位移为x,但是提交失败了,然后下一次又异步提交了消费位移为x+y,这次成功了。如果这里引入了重试机制,前一次的异步提交的消费位移在重试的时候提交成功了,那么此时的消费位移又变为了x。如果此时发生异常(或者再均衡),那么恢复之后的消费者(或者新的消费者)就会从x处开始消费消息,这样就发生了重复消费的问题。
为此我们可以设置一个递增的序号来维护异步提交的顺序,每次位移提交之后就增加序号相对应的值。在遇到位移提交失败需要重试的时候,可以检查所提交的位移和序号的值的大小,如果前者小于后者,则说明有更大的位移已经提交了,不需要再进行本次重试;如果两者相同,则说明可以进行重试提交。除非程序编码错误,否则不会出现前者大于后者的情况。
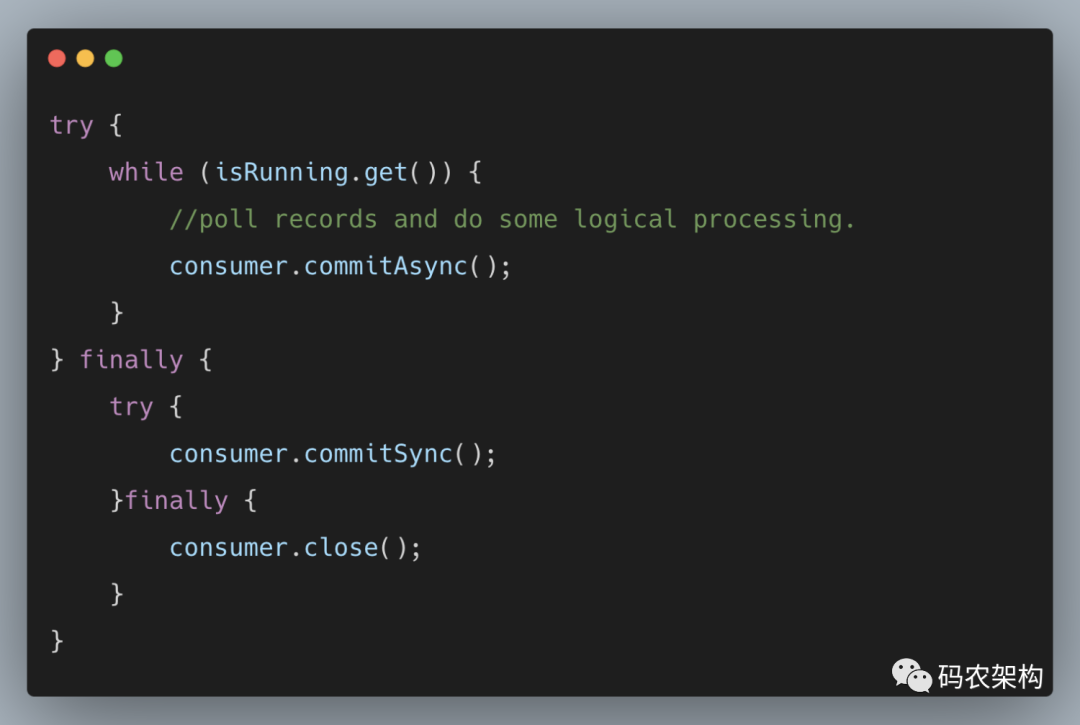
如果位移提交失败的情况经常发生,那么说明系统肯定出现了故障,在一般情况下,位移提交失败的情况很少发生,不重试也没有关系,后面的提交也会有成功的。重试会增加代码逻辑的复杂度,不重试会增加重复消费的概率。如果消费者异常退出,那么这个重复消费的问题就很难避免,因为这种情况下无法及时提交消费位移;如果消费者正常退出或发生再均衡的情况,那么可以在退出或再均衡执行之前使用同步提交的方式做最后的把关。
- END -

本文分享自微信公众号 - 码农架构(iByteCoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。