
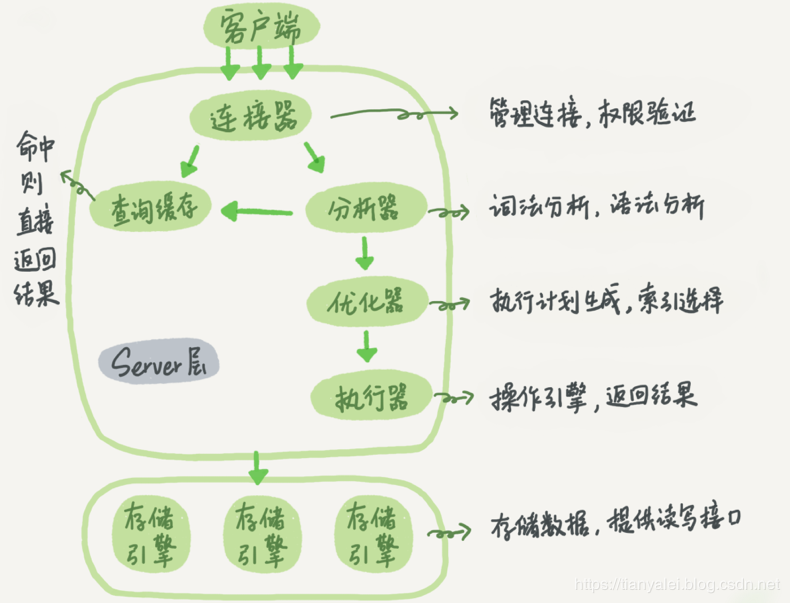
学习了mysql的连接层之后,要来看一下mysql的server层了。这一层聚集了mysql的最多的逻辑,包括了请求解析、查询缓存、语义分析、查询优化、各种计算函数、扫描记录、binlog、缓存、锁、内存管理等等。
当一个连接建立起了,用户发过来一个sql语句,从接到这个语句到返回给用户结果,这个过程中,经历了很多事,如果每一步都非常清楚,那么你就能解决大部分的问题。
这一篇主要是讲表对象缓存。
我借用一下别人画的一个图
创建表
假如你已经创建好了一个表,设置好了列、列属性,索引什么的,并且指定好了存储引擎(默认innodb)。
表对象缓存
用户发过来一个sql,譬如select * from tableA where id =1;此时mysql拿到了这个请求,会先到查询缓存中看,之前是不是执行过这个语句。缓存里key就是这个查询语句,如果查询缓存有,那么就直接返回value给客户端。这个查询缓存是个非常鸡肋的东西,新版8.0已经把它删掉了。这里也不多提。
mysql收到请求后,会进行sql语句解析,会分析出,你是查询(插入、删除),哪个表(tableA、tableB),条件。然后先判断sql语句是否合法,假如你写了个selector * 那么就会报错给你看。
ok,要进入正题表对象缓存了。
解析出了表之后,要得到这个表的各种信息。
一级表结构缓存
我要操作表了,首先我要找到这个表。先从缓存中(源码里的table_def_cache,是一个Hash结构)找,根据表名做为Key去找,由于我是第一次访问这个表,缓存里没有。那么就会从System表里去找,熟悉mysql元数据的应该知道,元数据里有每个表的定义,列信息什么的都在表里。找到了这个表,就会构建出这个表的结构体TABLE_SHARE。
这个TABLE_SHARE是一个静态的、不允许修改的(在内存中)结构体TABLE_SHARE,并将其放入缓存中(一个Hash结构里,key就是表名+模式名)。可以理解为一个java里的类,每个字段已经被赋了初始值。这个缓存是属于mysql层的,与后面的存储引擎无关。里面保存了表名、库名、所有列信息、列默认值、表的字符集、对应的frm文件路径、对应的存储引擎、主键等。
请注意,这个结构体就是一级缓存,它被所有用户共享,并且不可修改,从系统表被读入直到该表被修改或删除,这个缓存都会一直存在。
二级表对象缓存
表已经找到了,结构也已经被缓存了,此时我还不能操作这个表。因为缺少一个表对象。
上面的TABLE_SHARE可以理解为一个模板类,包含了表的基本信息,能被所有用户共享。但是里面还缺少一些信息,譬如不同用户对该表的权限、譬如存储引擎信息。那么要想操作这个表,就需要创建一个表对象来供当前用户(线程)使用。
创建表对象就是实例化的过程,每个用户独享一个实例,我们称之为table实例,不会影响其他用户。创建的这个实例,里面有一个指向TABLE_SHARE的引用,用以获取基本信息,还有一些其他属性,譬如存储引擎层的信息也会被初始化(引擎的handler)。
表对象创建完毕后,就具备了和存储引擎交互的能力(通过handler)。创建后,也会放入缓存,供下次使用时避免反复创建实例。
mysql层与存储引擎层,就是从这里开始分家的,table对象就是他俩沟通的桥梁。对于各个存储引擎,需要提供公共的接口来供上层(mysql server)层来调用,并由各自的table实例来完成各自的操作。
譬如插入一条记录,就可以调用table实例中被初始化过的存储引擎的句柄接口函数ha_write_row,进行写入。
这个table实例在一次操作完成之后就不需要了,系统此时并没有将其释放掉,而是保存下来,用一个状态标志位标记一下,并且会调用handler.reset()来重置引擎表状态,目的是handler会被复用,如果不reset,可能导致信息错误。缓存后,当下次用户再访问时,就不需要重新实例化了。
总结
可以看到,当你想操作一个表时,系统对于这个表,会有两层缓存。第一层是SHARE缓存,第二层就是实例化后的对象缓存Table。
是缓存就有淘汰策略,其实我们自己就能判断出来,SHARE缓存只有在表结构定义改变时,才会被删除,但是倘若表巨多,SHARE缓存超出限制,也会淘汰那些不经常使用的SHARE。
第二层的实例缓存,也是有最大值的,超出后则开始淘汰。
涉及的参数变量有两个,table_open_cache和table_definition_cache,一些淘汰策略数值就是靠这两个参数来计算得到的。当你有巨多的表时,可以网上查查这两个参数的涵义,适当调整修改。
优缺点
不同于某些数据库,一启动就加载了所有表信息。mysql是按需加载,由于mysql的插件式存储引擎,mysql做了两层的缓存模型,第二层才加载引擎的handler。
优缺点:
按需加载,提高内存利用率,避免启动时加载所有表信息带来的内存占用。
缺点:
两层缓存带来了效率的损失,每个用户(线程)都要实例化table对象。
在并发情况下,有可能会实例化多个table对象,导致table_open_cache增长过快,导致淘汰掉其他的table对象。同时倘若table比较大,譬如有N多的列,那么会占用非常多的内存。













