大家好,我是Python进阶者,今天给大家整点好玩的,一起来看看吧~
【一、项目背景】
平时宅在家的我们最爱做的事莫过于追剧了,但是有时候了,网络原因,可能会让你无网可上,这个时候那些好看的电视剧和电影自然是无法观看了,本期我们要讲的就是怎样下载这些视频。
【二、项目目标】通过Python程序对所感兴趣的视频进行批量下载,正好小编近期看到一些不错的视频,因为想往安卓方向走,但又苦于重新学习太复杂,有没有简单点的,之前好像有什么e4a但是要学易语言就放弃了,于是乎在茫茫网络发现了一个小众的编程语言---裕语言。好家伙,不说了,赶紧下载,盘它。
【三、项目实施】采用sublime text 3 编写程序,先看看效果:
C:\Users\Administrator\Desktop\232.jpg
接下来,由小编我为大家展现程序的具体实现步骤。
【四、实现步骤】1.分析网页结构
老样子,审查元素定位,如下图:
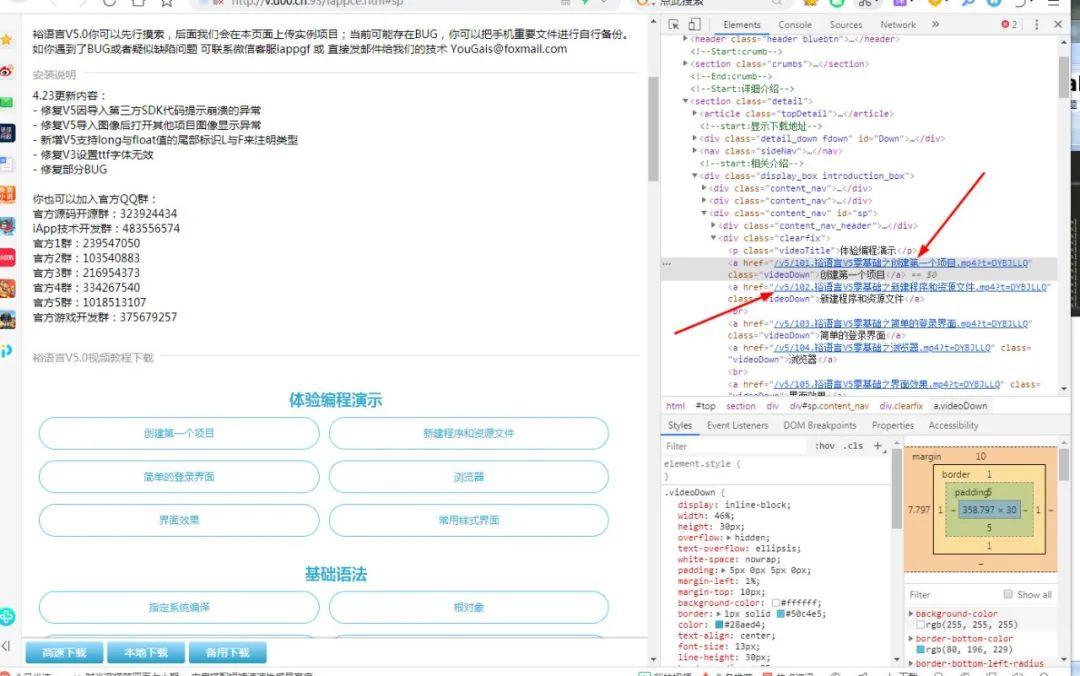
C:\Users\Administrator\Desktop\1212.jpg
发现视频全都在a标签里面,因为这个页面的视频比较多,所以我们继续分析页面,发现一个神奇的事情。哈哈,原来所有的视频都在class为videoDown的a标签里,有了这个重要的信息就什么都好办了。
#解析页面
def parser():
ab=[]
rep=requests.get('http://v.u00.cn:93/iappce.htm#sp',timeout=5,headers=headers)
rep.encoding='utf-8'
soup=BeautifulSoup(rep.text,'html.parser')
res=soup.find_all('a',class_='videoDown')#寻找所有class为videoDown的a标签
for y in res:
ab.append('http://v.u00.cn:93'+y.attrs['href'])
#将获取到的视频URL地址添加到列表中
return ab #返回所有视频地址的列表这样就轻轻松松拿到了页面所有的视频地址,怎么样,是不是超级简单了。
2.下载文件
因为我们讲的是批量下载,所以在此之前需要先了解单个下载,当然,单个下载是很耗费时间,而且系统资源利用率太低。
我们来看看这个下载函数如何实现:
#下载函数
def down(y,x):
print('------下载第',str(x),'课-------')
ss=str(y.split('.')[3:4]) \#截取文件名
sa=ss.replace('[','').replace(']','')\#替换文件名中的特殊符号
ree=requests.get(y)
with open('%d.%s.mp4'%(x,sa),'wb') as f:
f.write(ree.content) \#保存文件无非就是一些常用的字符串分隔以及文件操作罢了,不过此种因为比较单一,下载多个文件就行不通了,所以一般只要不是大批量下载,这种方法就够了。
然后在给他套一个函数用来简化他的启动之路。
def main():
for y in range(len(parser())):
down(parser()[y],y) \#下载
main()最后调用主函数main,轻轻松松完成单个文件下载。
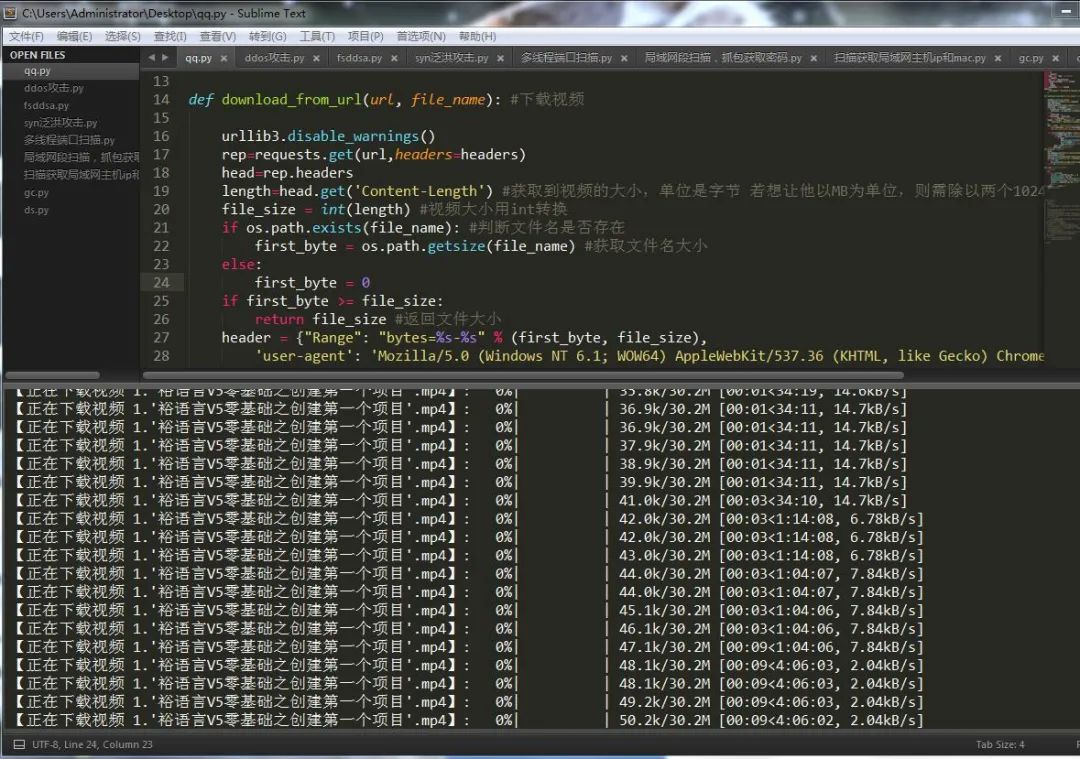
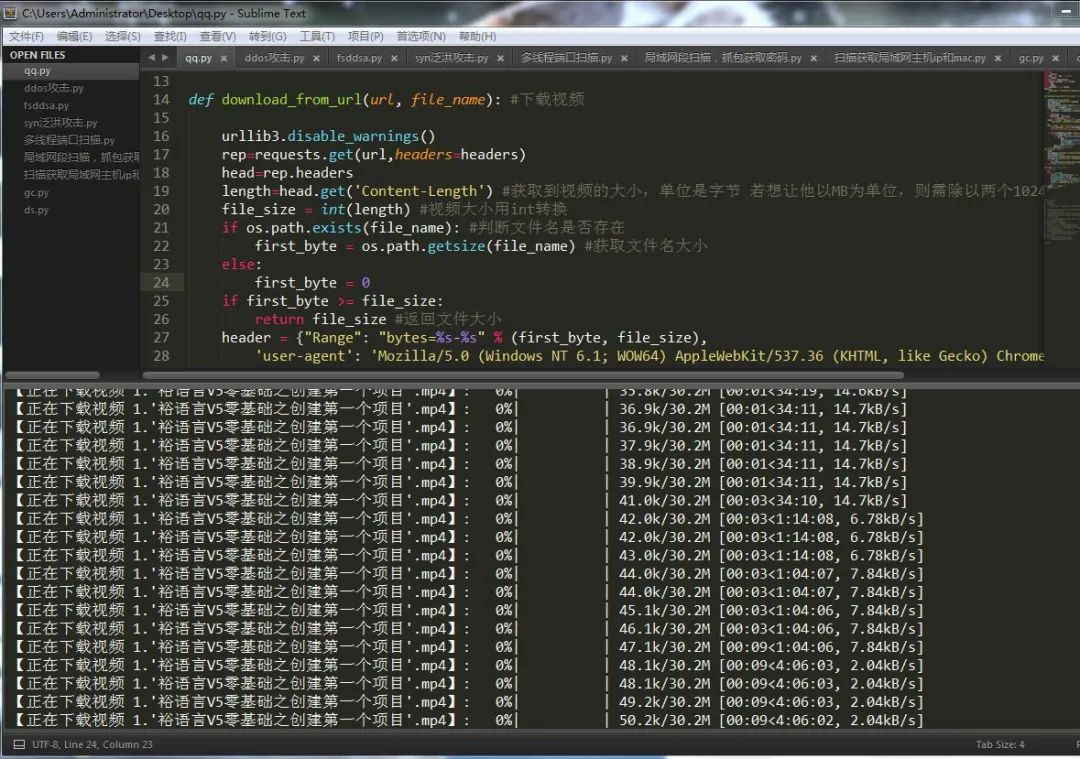
3.获取文件大小并给下载文件添加缓冲
在下载视频的时候如果我们一下子把所有的资源你都拿出来放进CPU读取,那么很快就会崩溃,所以我们需要设置一个缓冲,等他缓冲区满了然后拿出来读取,听起来好像挺抽象,让我们一起来看一下吧。
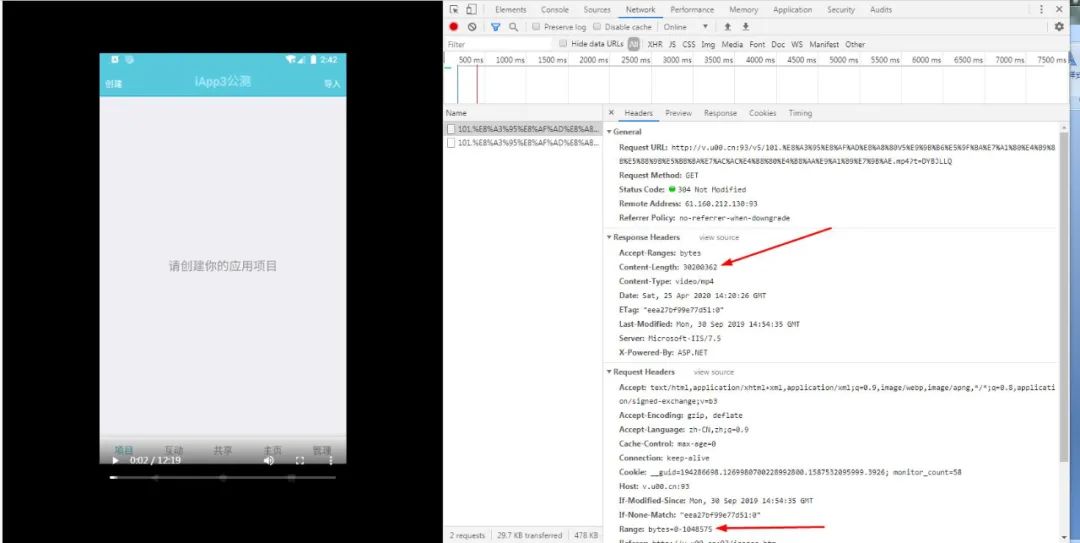
C:\Users\Administrator\Desktop\4343.jpg
图中所示即为视频大小值和请求范围的值。
1.获取视频大小
def download(url, file_name):
# 下载视频
urllib3.disable_warnings()
rep = requests.get(url, headers=headers)
head = rep.headers
rep = requests.get(url, headers=headers)
head = rep.headers # 获取请求头字典
length = head.get('Content-Length') # 获取到视频的大小,单位是字节若想让他以MB为单位,则需除以两个1024
file_size = int(length) # 视频大小用int转换
if os.path.exists(file_name):
# 判断文件名是否存在
first_byte = os.path.getsize(file_name) # 获取文件名大小
else:
first_byte = 0
if first_byte >= file_size:
return file_size # 返回文件大小
header = {"Range": "bytes=%s-%s" % (first_byte, file_size),
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome / 78.0
.3904
.108
Safari / 537.36
'
} # 设置请求头,标明请求范围
2.配置进度条
pbar = tqdm( \#配置进度条模块,设置文件大小,文件字节数,文件的进度
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=url.split('/')[-1])
#关于tqdm 具体用法大家可以百度tqdm模块。3.添加缓冲
with closing(requests.get(url, headers=header, stream=True)) as req:
#关闭连接
with open(file_name,'wb') as f: \#打开文件
for chunk in req.iter_content(chunk_size=1024\*2): \#设置缓冲
if chunk:
pbar.set_description("【正在下载视频 %s】"%str(f.name))
f.write(chunk) \#写入文件
pbar.update(1024) \#更新当前进度条
pbar.close() \#关闭进度条
return file_size \#返回文件大小4.构建下载视频并显示进度条函数
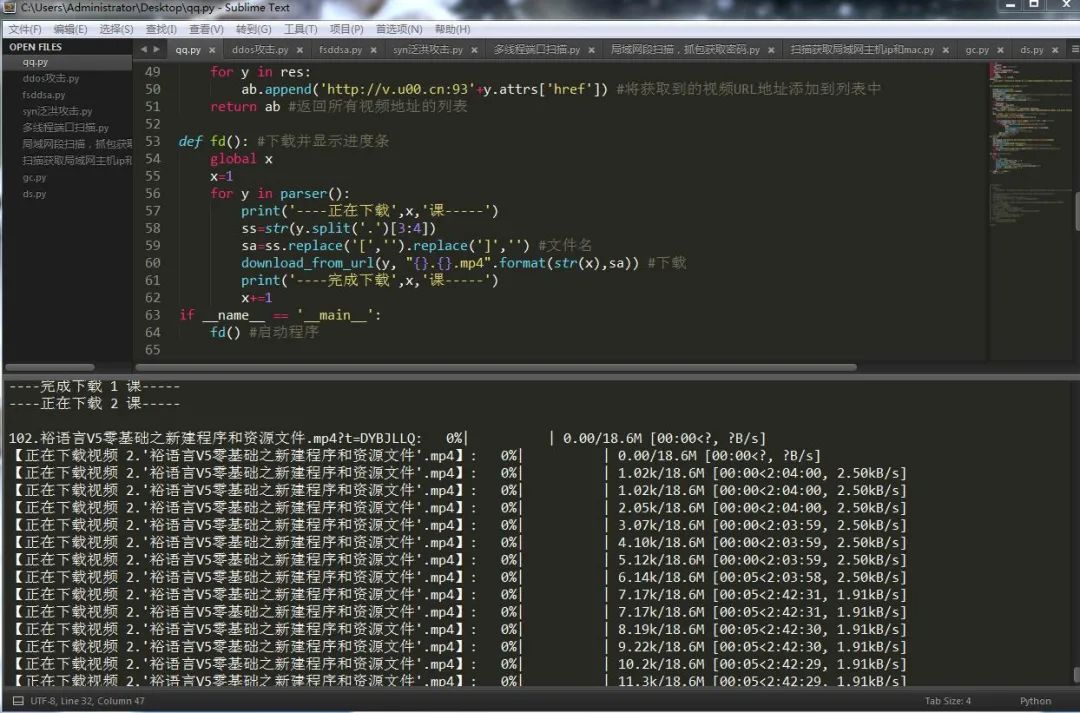
def fd(): \#下载并显示进度条
global x
x=1
for y in parser():
print('----正在下载',x,'课-----')
ss=str(y.split('.')[3:4])
sa=ss.replace('[','').replace(']','') \#文件名
download(y, "{}.{}.mp4".format(str(x),sa)) \#下载
print('----完成下载',x,'课-----')
x+=15.启动程序
Fd()【五.总结】
批量下载视频文件是一个不可多得的技术,程序写的并不够好,比如程序没有添加多线程,多进程,协程,也没有异步操作,可能是因为自己比较懒吧,哈哈哈。
不过也挺简单,多线程就是threading.Thread 顺便加锁 Lock,也可以用多进程multiprocessing中的Process或者进程池Pool,或者协程genvent,或者异步asynic
**-----**------**-----**---**** End **-----**--------**-----**-****

往期精彩文章推荐:
欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/t25QgSgU_KoTbbDFCICqog,如有侵权,请联系删除。