
本文对Clickhouse架构原理、语法、性能特点做一定研究,同时将其与mysql、elasticsearch、tidb做横向对比,并重点分析与mysql的语法差异,为有mysql迁移clickhouse场景需求的技术预研及参考。
1 基础概念
Clickhouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
1.1 集群架构
ClickHouse 采用典型的分组式的分布式架构,具体集群架构如下图所示:
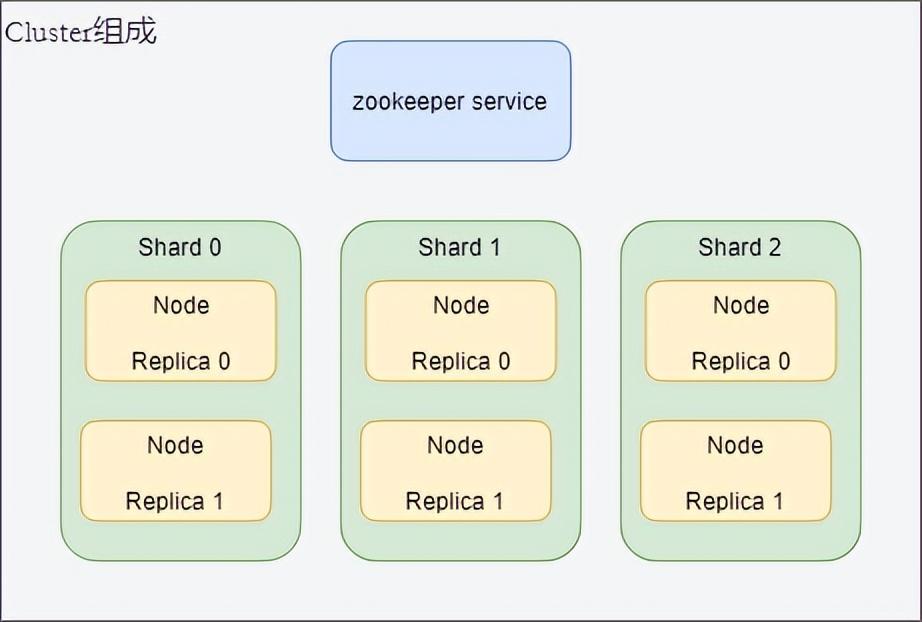 )
)- Shard:集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard 的线性扩展能力,支持海量数据的分布式存储计算。
- Node: 每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
- ZooKeeper Service: 集群所有节点对等,节点间通过 ZooKeeper 服务进行分布式协调。
1.2 数据分区
Clickhouse是分布式系统,其数据表的创建,与mysql是有差异的,可以类比的是在mysql上实现分库分表的方式。
Clichhouse先在每个 Shard 每个节点上创建本地表(即 Shard 的副本),本地表只在对应节点内可见;然后再创建分布式表[Distributed],映射到前面创建的本地表。
用户在访问分布式表时,ClickHouse 会自动根据集群架构信息,把请求转发给对应的本地表。
 )
)1.3 列式存储
相对于关系型数据库(RDBMS),是按行存储的。以mysql中innodb的主键索引为例,构建主键索引的B+树中,每个叶子节点存储的就是一行记录。
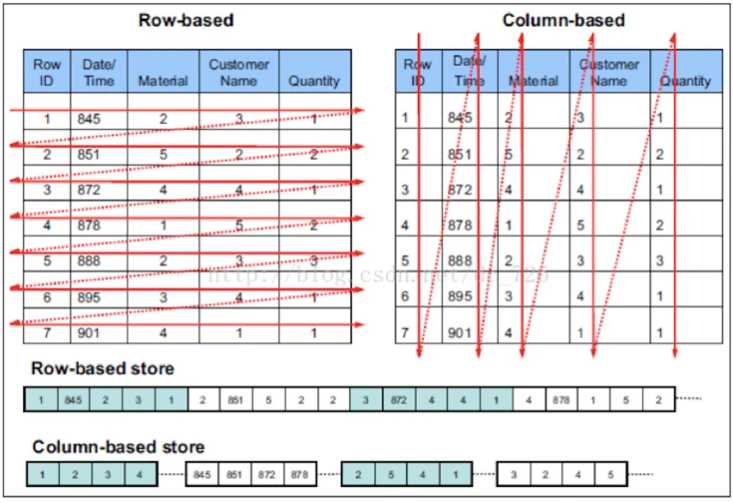
而列式数据库,是将一个表,按column的维护进行存储,“单次磁盘I/O拿到的是一列的数据”。
 )
)列式存储的优点
在查询时,只会读取涉及到的列,会大大减少IO次数/开销。并且clickhouse在存储时会按指定顺序排列数据,因此只需要按where条件指定列进行顺序扫描、多个列的扫描结果合并,即可找到满足条件的数据。
但由于insert数据时,是按行写入的,因此存储的过程会麻烦一些。
查询时的区别:
- 列存储:仅从存储系统中读取必要的列数据(select + where 涉及到的),无用列不读取,速度非常快。
- 行存储:从存储系统读取所有满足条件的行数据,然后在内存中过滤出需要的字段,速度较慢。
1.4 数据排序
每个数据分区内部,所有列的数据是按照 排序键(ORDER BY 列)进行排序的。
可以理解为:对于生成这个分区的原始记录行,先按 排序键 进行排序,然后再按列拆分存储。
1.5 数据分块
每个列的数据文件中,实际是分块存储的,方便数据压缩及查询裁剪,每个块中的记录数不超过 index_granularity,默认 8192,当达到index_granularity的值,数据会分文件。
1.6 向量化执行
在支持列存的基础上,ClickHouse 实现了一套面向向量化处理的计算引擎,大量的处理操作都是向量化执行的。
向量化处理的计算引擎:
基于数据存储模型,叠加批量处理模式,利用SIMD指令集,降低函数调用次数,降低硬件开销(比如各级硬件缓存),提升多核CPU利用率。
再加上分布式架构,多机器、多节点、多线程、批量操作数据的指令,最大限度利用硬件资源,提高效率。
注:SIMD指令,单指令多数据流,也就是说在同一个指令周期可以同时处理多个数据。(例如:在一个指令周期内就可以完成多个数据单元的比较).
1.7 编码压缩
由于 ClickHouse 采用列存储,相同列的数据连续存储,且底层数据在存储时是经过排序的,这样数据的局部规律性非常强,有利于获得更高的数据压缩比。
同时,超高的压缩比又可以降低存储读取开销、提升系统缓存能力,从而提高查询性能。
1.8 索引
前面提到的列式存储,用于裁剪不必要的字段读取;
而索引,则用于裁剪不必要的记录读取(减少未命中数据的IO)。
简单解释:
以主键索引为例,Clickhouse存储数据时,会按排序键(ORDER BY)指定的列进行排序,并按Index_granularity参数切分成块,然后会抽取每个数据块的首行,组织为一份稀疏的排序索引。
类比B+树的查找过程,如果where条件中包含主键列,就可以通过稀疏索引快速的过滤。稀疏索引对于范围查找比较高效。
二级索引,则是采用bloom filter来实现的:minmax,set,ngrambf/tokenbf。
1.9 适用场景
OLAP 分析领域有两个典型的方向:
- ROLAP, 通过列存、索引等各类技术手段,提升查询时性能。
宽表、大表场景,where条件过多且动态,mysql无法每列都建索引。 - MOLAP, 通过预计算提前生成聚合后的结果数据,降低查询读取的数据量,属于计算换性能方式。
复杂的报表查询,聚合、筛选很复杂的场景。
既然是OLAP分析,对数据的使用有些基本要求:
- 绝大多数都是用于读访问
- 无更新、大批量的更新(大于1000行)。(ck没有高速、低延迟的更新和删除方法)
- 查询的列尽量少,但行数很多。
- 不需要事务、可以避免事务(clickhouse不支持事务)
- 数据一致性要求较低
- 多表join时,只有一个是大表、大表关联小表
- 单表的查询、聚合效率最高,建议数据做宽表处理
2 横向对比
搬仓系统面临的是从十几亿数据中进行查询、聚合分析,从世面上可选的支持海量数据读写的中间件中搜集到,能够有支持类似场景、有比较轻量级的产品大概有Clickhouse、ElasticSearch、TiDB。
2.1 clickhouse与ElasticSearch对比
elastic生态很丰富,es作为其中的存储产品,从首个版本算起,已经有10年发展历史,主要解决的是搜索问题。es的底层存储采用lucene,主要包含行存储、列存储和倒排索引,利用分片与副本机制,解决了集群下搜索性能与高可用的问题。
es的优势:
- 支持实时更新,对update、delete操作支持更完整。
- 数据分片更均匀,集群扩展更加方便
es的局限性:
- 数据量超过千万或者亿级时,若聚合的列数太多,性能也到达瓶颈;
- 不支持深度二次聚合,导致一些复杂的聚合需求,需要人工编写代码在外部实现,这又增加很多开发工作量。
ClickHouse 与 Elasticsearch(排序与聚合查询) 一样,都采用列式存储结构,都支持副本分片,不同的是 ClickHouse 底层有一些独特的实现,如下:
- 合并树表引擎系列(MergeTree ),提供了数据分区、一级索引、二级索引。
- 向量引擎(Vector Engine),数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用 CPU
网上资料:聚合查询的性能对比
es对于在处理大查询,可能导致OOM问题,集群虽然能够对异常节点有自动恢复机制,但其查询数据量级不满足搬仓系统需求。
2.2 clickhouse与TiDB对比
TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合OLTP场景还适OLAP场景的混合数据库。
TiDB的优势:
- 兼容Mysql协议和绝大多数Mysql语法,在大多数情况下,用户无需修改一行代码就可以从Mysql无缝迁移到TiDB
- 高可用、强制一致性(Raft)
- 支持ACID事务(依赖事务列表),支持二级索引
适合快速的点插入,点更新和点删除
TiDB的局限性:
- 更擅长OLTP
- 性能依赖硬件和集群规模,单机的读写性能不够出色
TiDB更加适合作为MySql的替代,其对MySQL的兼容可以使得我们的应用切换成本较低,并且TiDB提供的数据自动分片无需人工维护。
3 为什么是clickhouse
我们的项目场景是每天要同步十几亿单表数据,基本业务的查询在百万,还包含复杂的聚合分析。而Clickhouse在处理单表海量数据的查询分析方面,是十分优秀的,因此选用clickhouse。
3.1 clickhouse读写性能验证
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
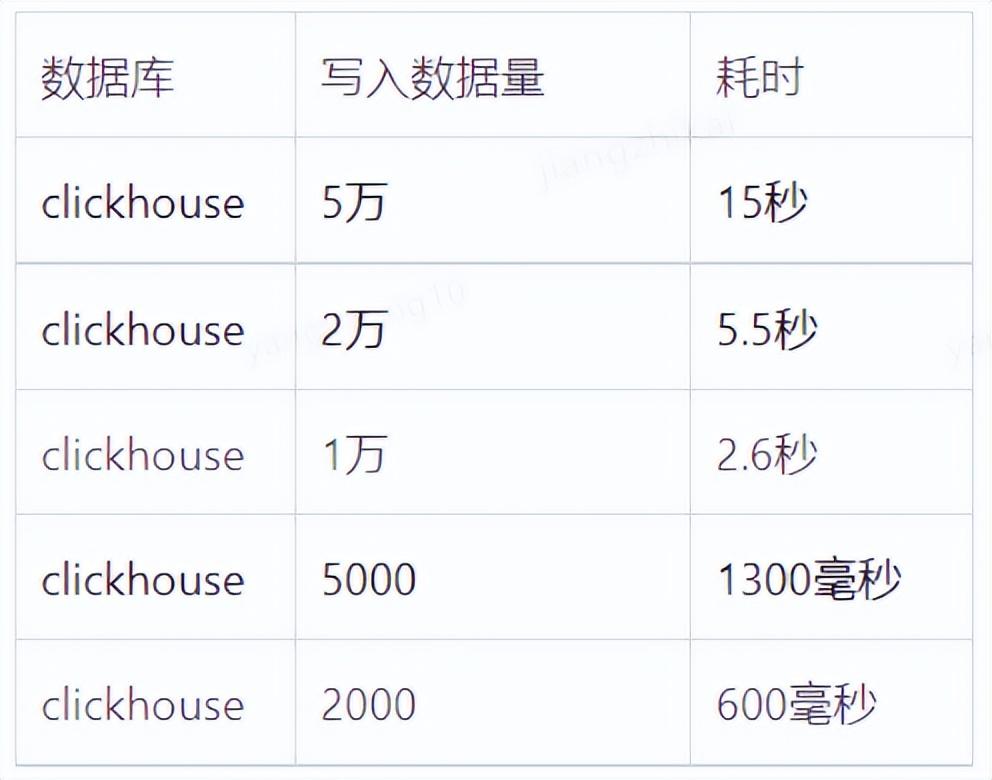
下面是对Clickhouse的读写性能的简单测试,数据量越大差距越明显。
1)JDBC方式单表、单次写入性能测试(性能更好):
 )
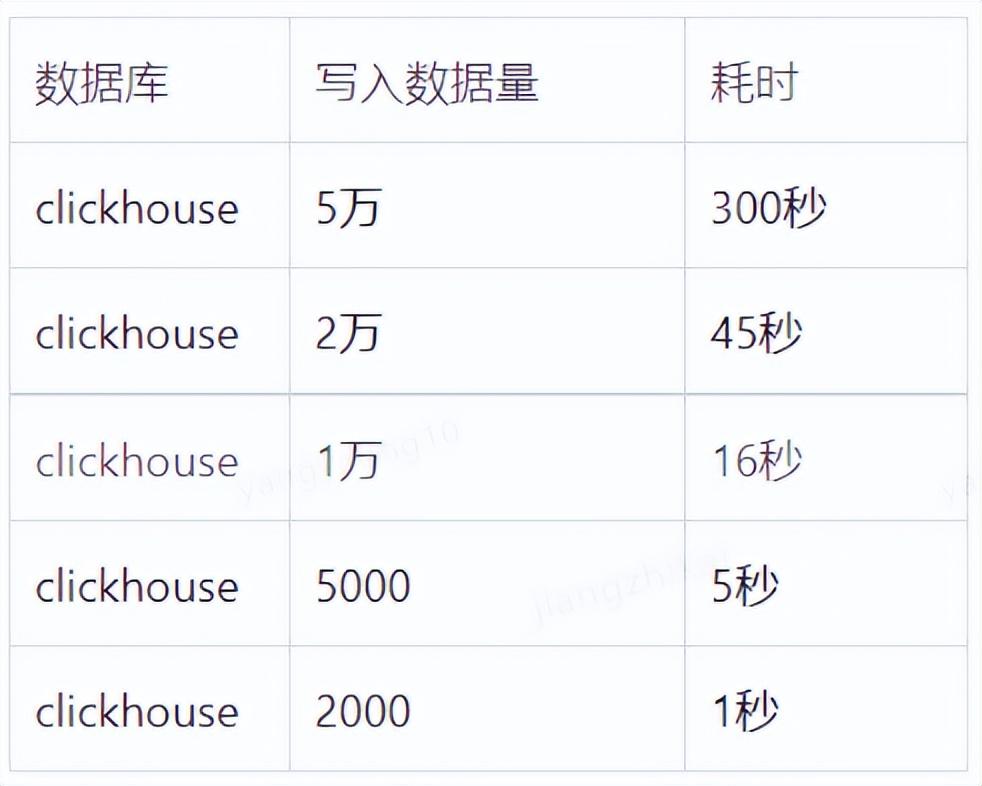
)2)Mybatis方式单表、单次写入性能测试:
 )
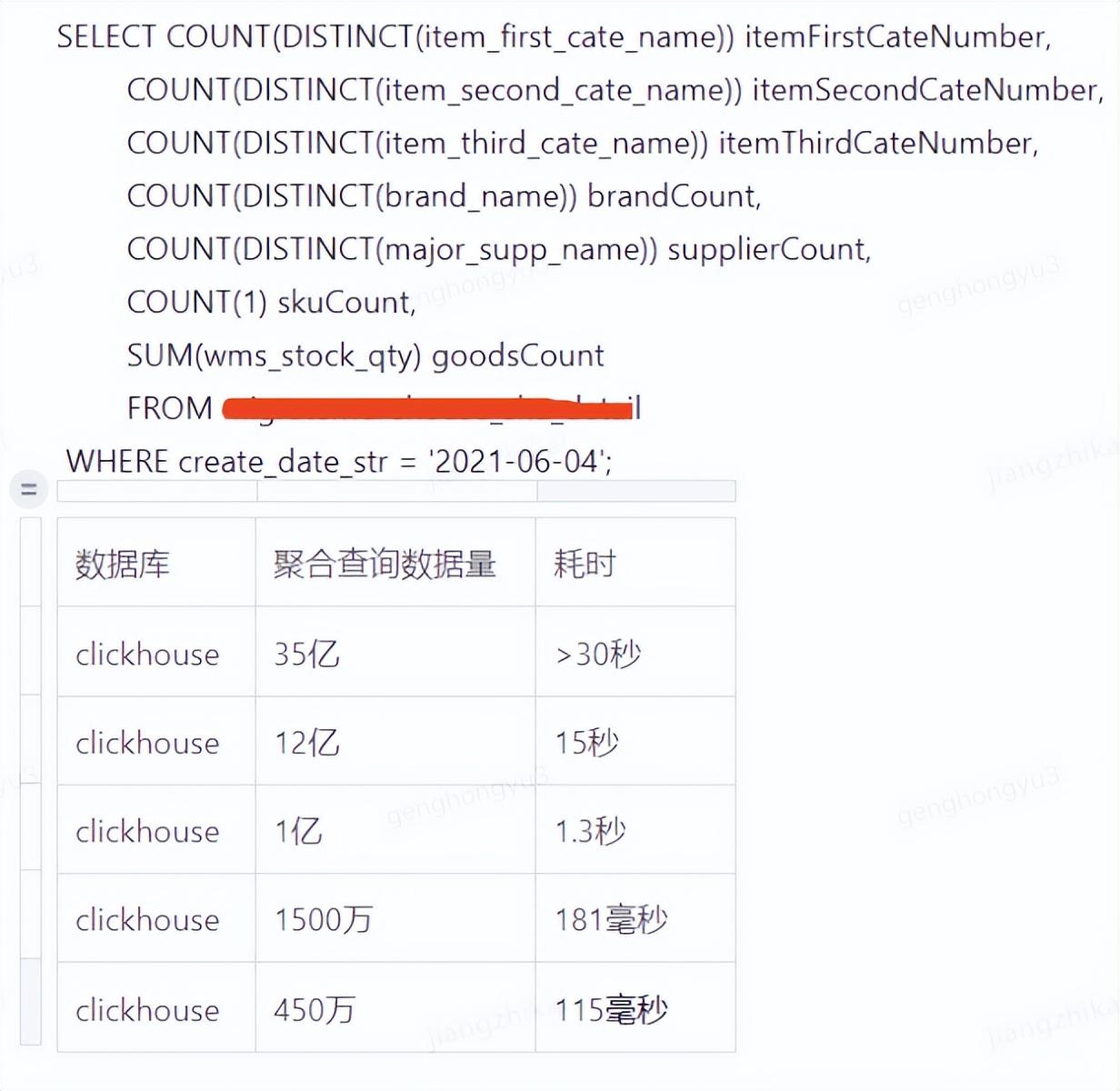
)聚合查询性能举例:下图是搬仓系统一个聚合查询,在clickhouse中不同数据量级情况下的表现。这个查询在mysql中执行,一百万左右的数据量时,耗时已经是分钟级别。
1)count+distinct方式聚合:
 )
)2)group by方式聚合:
 )
)3.2 不足之处
作为分布式系统,通常包含三个重要组成:1、存储引擎。 2、计算引擎。 3、分布式管控层。
在分布式管控层,CK显得较为薄弱,导致运营、使用成本较高。
- 分布式表、本地表、副本的维护,这些都是需要用户自己来定义的,在使用时需要提前学习大量相关内容。
- 弹性伸缩:ck虽然可以做到水平增加节点,但不支持自动的数据均衡。也就是说当集群扩容后,需要手动将数据重写分片,或者依赖数据过期,才能保持存储压力的均衡。
- 故障恢复:在节点故障的情况下,ck不能利用其他机器补齐缺失的副本数据,需要用户ian补齐节点后,才能自动在副本件进行数据同步。
这方面,由于我们直接采用京东云实例,可以省很多事情。
计算引擎,CK在处理多表关联查询、复杂嵌套子查询等场景,需要人工优化,才能做到明显的性能提升;
实时写入,CK使用场景并不适合比较分散的插入,因为其没有实现内存表(Memory Table)结构,每批次写入直接落盘,单条记录实时写入会导致底层大量的小文件,影响查询性能。
建议单次大批量写入方式、报表库场景降低小文件产生概率。
集群模式下本地表的写入,需要自定义分片规则,否则随机写入会造成数据不均匀。
依赖分布式表的写入,对网络、资源的占用较高。
从数据量增长情况来看,使用场景:
- 如果预估自己的业务数据量不大(日增不到百万行), 那么写分布式表和本地表都可以, 但要注意如果选择写本地表, 请保证每次写入数据都建立新的连接, 且每个连接写入的数据量基本相同,手动保持数据均匀
- 如果预估自己的业务数据量大(日增百万以上, 并发插入大于10), 那么请写本地表
- 建议每次插入50W行左右数据, 最多不可超过100W行. 总之CH不像MySQL要小事务. 比如1000W行数据, MySQL建议一次插入1W左右, 使用小事务, 执行1000次. CH建议20次,每次50W. 这是MergeTree引擎原理决定的, 频繁少量插入会导致data part过多, 合并不过来.
- MergeTree系列:被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
- Log系列:功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。
- Integration系列:主要用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
- Special系列:大多是为了特定场景而定制的。上面提到的Distributed就属于该系列。
4.1 MergeTree表引擎
主要用于海量数据分析,支持数据分区、存储有序、主键索引、稀疏索引、数据TTL等。MergeTree支持所有ClickHouse SQL语法,但是有些功能与MySQL并不一致,比如在MergeTree中主键并不用于去重。
先看一个创建表的简单语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr] -- 数据分区规则
[ORDER BY expr] -- 排序键
[SAMPLE BY expr] -- 采样键
[SETTINGS index_granularity = 8192, ...] -- 额外参数先忽略表结构的定义,先看看相比于mysql建表的差异项。(指定集群、分区规则、排序键、采样0-1数字)
数据分区:每个分片副本的内部,数据按照 PARTITION BY 列进行分区,分区以目录的方式管理,本文样例中表按照时间进行分区。
 )
)基于MergeTree表引擎,CK扩展很多解决特殊场景的表引擎,下面介绍几种常用的。
4.1.1 ReplacingMergeTree引擎
该引擎和 MergeTree 的不同之处在于它会删除排序键值(ORDER BY)相同的重复项。
官方建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]注意:在设置表引擎时,比MergeTree多了一个参数:ver-版本列,ENGINE = ReplacingMergeTree([ver]) 。
在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:
- 如果 ver 列未指定,保留最后一条。
- 如果 ver 列已指定,保留 ver 值最大的版本。
ReplacingMergeTree引擎,在数据写入后,不一定立即进行去重操作,或者不一定去重完毕(官方描述在10到15分钟内会进行合并)。
由于去重依赖的是排序键,ReplacingMergeTree引擎是会按照分区键进行分区的,因此相同排序键的数据有可能被分到不同的分区,不同shard间可能无法去重。
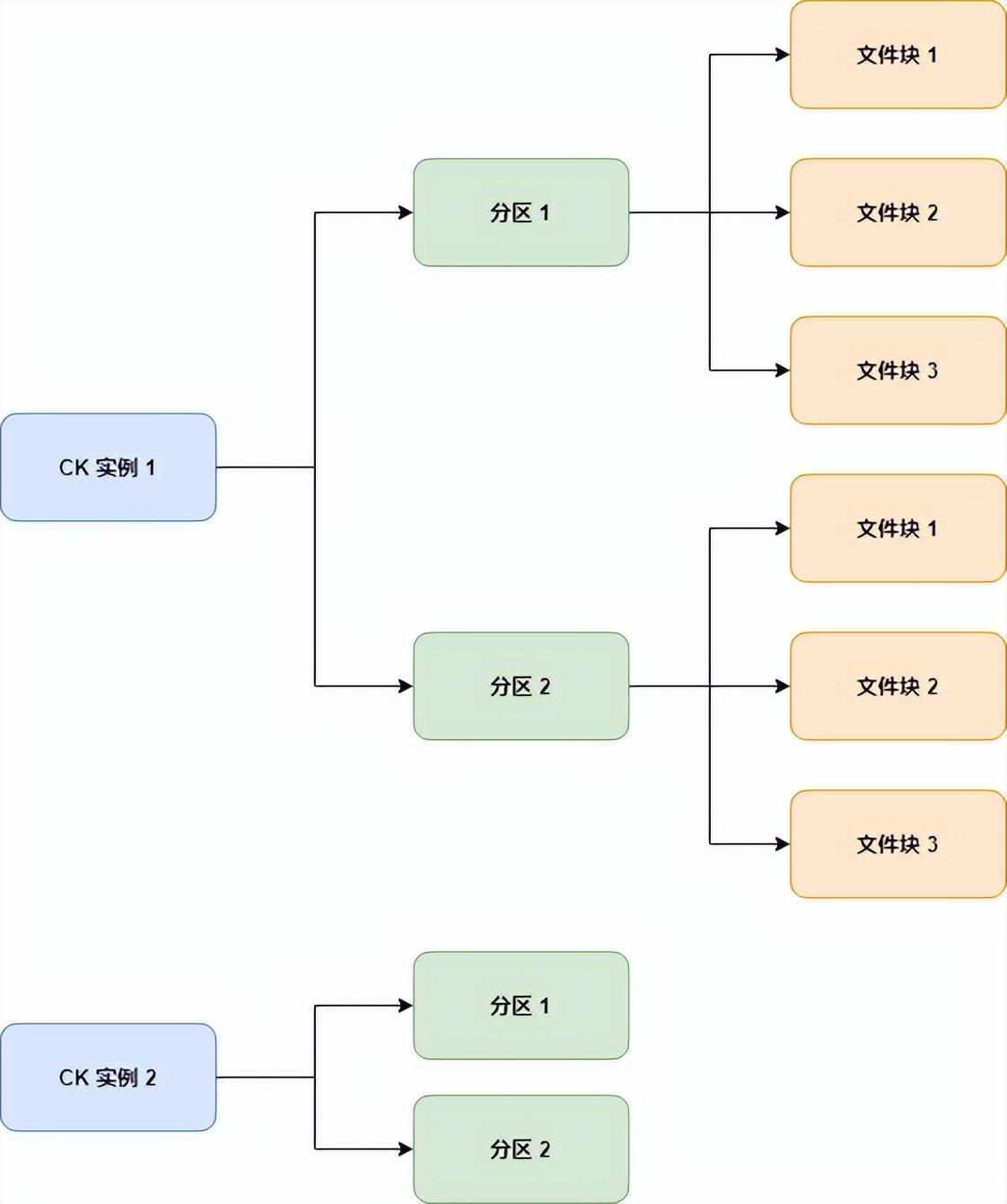 )
)在图上,分区1的文件块,会进行数据合并去重,但是分区1与分区2之间的数据是不会进行去重的。因此,如果要保证数据最终能够去重,要保证相同排序键的数据,会写入相同分区。
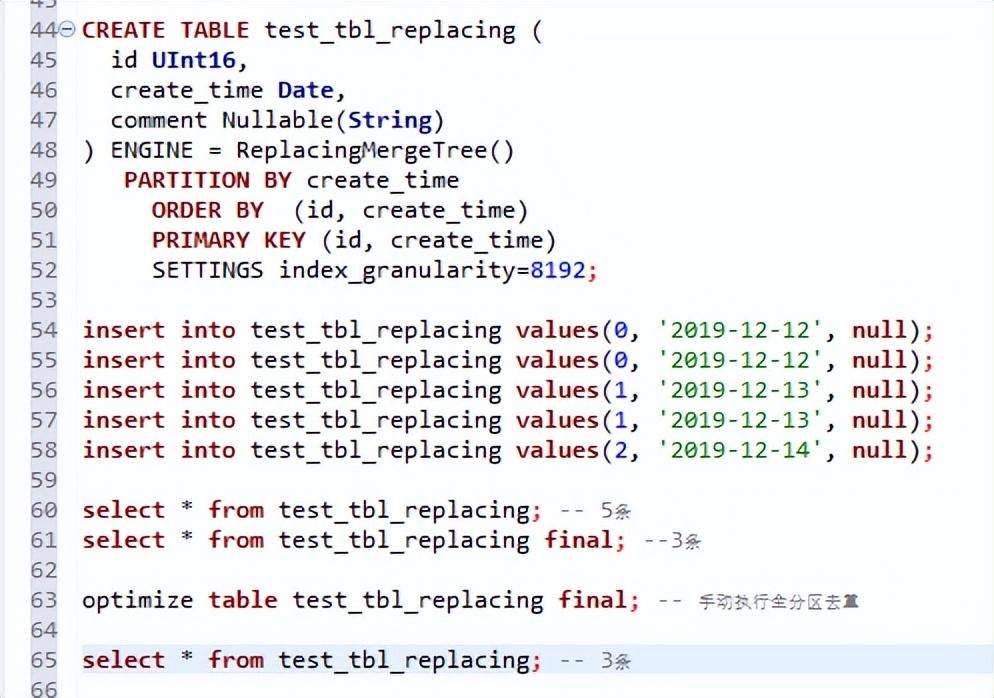
数据验证
下图为ReplacingMergeTree引擎,以日期作为分区键,对于重复主键数据的去重测试:
 )
)4.1.2 CollapsingMergeTree引擎
该引擎要求在建表语句中指定一个标记列Sign,按照Sign的值将行分为两类:Sign=1的行称之为状态行,Sign=-1的行称之为取消行。每次需要新增状态时,写入一行状态行;需要删除状态时,则写入一行取消行。
使用场景:
- 按clickhouse的架构,期合并、折叠操作,都是后台独立现场执行的,因此时间上并不能控制,何时折叠完成也无法预知。
- 如果插入的状态行与取消行是乱序的,会导致无法正常折叠
4.1.3 VersionedCollapsingMergeTree表引擎
为了解决CollapsingMergeTree乱序写入情况下无法正常折叠问题,VersionedCollapsingMergeTree表引擎在建表语句中新增了一列Version,用于在乱序情况下记录状态行与取消行的对应关系。
主键相同,且Version相同、Sign相反的行,在Compaction时会被删除。
4.2 数据副本
数据副本放在表引擎这里单独讲一下,是由于只有 MergeTree 系列里的表可支持副本:
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergetree
- ReplicatedGraphiteMergeTree
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表。
副本不依赖分片。每个分片有它自己的独立副本。
要使用副本,必须配置文件中设置 ZooKeeper 集群的地址。 (京东云提供的clickhouse已经完成了配置,我们直接使用即可)
<zookeeper>
<node index="1">
<host>example1</host>
<port>2181</port>
</node>
<node index="2">
<host>example2</host>
<port>2181</port>
</node>
<node index="3">
<host>example3</host>
<port>2181</port>
</node>
</zookeeper>创建数据副本,是通过设置表引擎位置的参数来控制的,语法示例:
CREATE TABLE table_name
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
)ENGINE=ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}') -- 这里
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)定义数据副本,只需要在以上表引擎名字的前面,带上Replicated即可。
上方例子中,使用的表引擎为MergeTree,开启数据副本,关键字Replicated,参数有2个且必填:
- zoo_path — ZooKeeper 中该表的路径。
- replica_name — ZooKeeper 中的该表的副本名称
示例中的取值,采用了变量{layer}、{shard}、{replica},他们的值取得是配置文件中的值,影响的是生成的副本粒度。
<macros>
<layer>05</layer>
<shard>02</shard>
<replica>example05-02-1.yandex.ru</replica>
</macros>4.3 Special系列
Special系列的表引擎,大多是为了特定场景而定制的。
- Memory:将数据存储在内存中,重启后会导致数据丢失。查询性能极好,适合于对于数据持久性没有要求的1亿一下的小表。在ClickHouse中,通常用来做临时表;
- Buffer:为目标表设置一个内存buffer,当buffer达到了一定条件之后会flush到磁盘;
- File:直接将本地文件作为数据存储;
- Null:写入数据被丢弃、读取数据为空。
- Distributed:分布式引擎,可以在多个服务器上进行分布式查询
4.3.1 Distributed引擎
分布式表引擎,本身不存储数据,也不占用存储空间,在定义时需要指定字段,但必须与要映射的表的结构相同。可用于统一查询*MergeTree的每个分片,类比sharding中的逻辑表。
比如搬仓系统,使用ReplicatedReplacingMergeTree与Distributed结合,实现通过分布式表实现对本地表的读写(写入操作本地表,读取操作分布式表)。
CREATE TABLE IF NOT EXISTS {distributed_table} as {local_table}
ENGINE = Distributed({cluster}, '{local_database}', '{local_table}', rand())说明:
- distributed_table:分布式表的表名
- local_table:本地表名
- as local_table:保持分布式表与本地表的表结构一致。此处也可以用 (column dataType)这种定义表结构方式代替
- cluster:集群名
注意事项:
- 分布式表本身并不存储数据,只是提供了一个可以分布式访问数据的框架,查询分布式表的时候clickhouse会自动去查询对应的每个本地表中的数据,聚合后再返回
- 注意AS {local_table},它表明了分布式表所对应的本地表(本地表是存储数据的)
- 可以配置Distributed表引擎中的最后一个参数 rand()来设置数据条目的分配方式
- 可以直接往分布式表中写数据,clickhouse会自动按照上一点所说的方式来分配数据和自平衡,数据实际会写到本地表
- 也可以自己写分片算法,然后往本地表中写数据【网上资料的场景是每天上千亿写入,性能考虑要直接写本地表】
4.4 Log系列
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。
几种Log表引擎的共性是:
- 数据被顺序append写到磁盘上;
- 不支持delete、update;
- 不支持index;
- 不支持原子性写;
- insert会阻塞select操作。
它们彼此之间的区别是:
- TinyLog:不支持并发读取数据文件,查询性能较差;格式简单,适合用来暂存中间数据;
- StripLog:支持并发读取数据文件,查询性能比TinyLog好;将所有列存储在同一个大文件中,减少了文件个数;
- Log:支持并发读取数据文件,查询性能比TinyLog好;每个列会单独存储在一个独立文件中。
4.5 Integration系列
该系统表引擎主要用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
- Kafka:将Kafka Topic中的数据直接导入到ClickHouse;
- MySQL:将Mysql作为存储引擎,直接在ClickHouse中对MySQL表进行select等操作;猜测:如果有join需求,又不想将mysql数据导入ck中
- JDBC/ODBC:通过指定jdbc、odbc连接串读取数据源;
- HDFS:直接读取HDFS上的特定格式的数据文件。
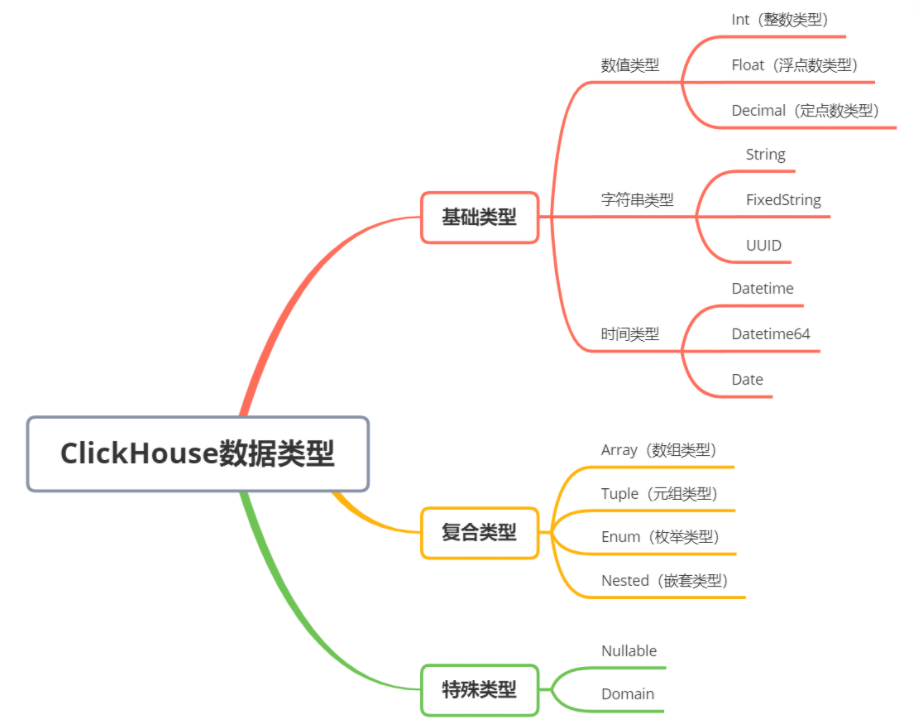
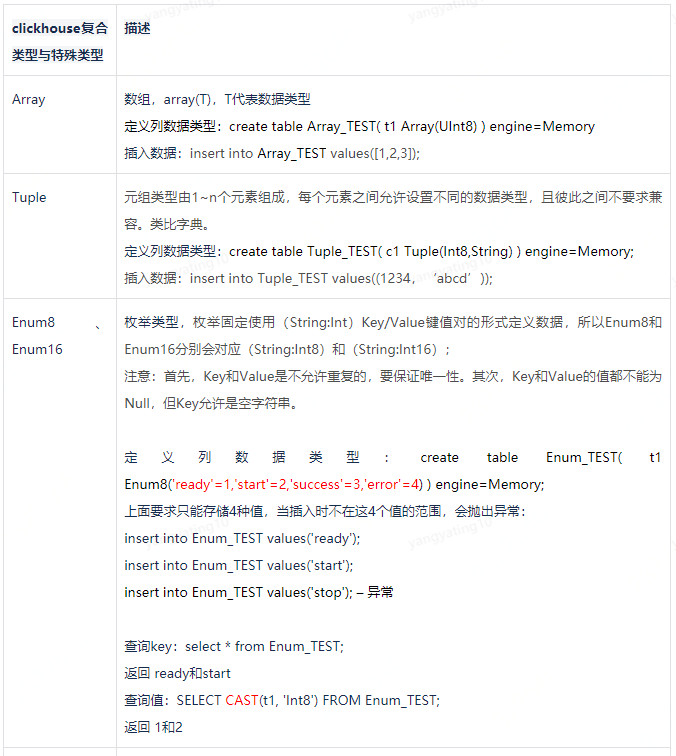
5 数据类型
clickhouse支持的数据类型如下图,分为基础类型、复合类型、特殊类型。
 )
)5.1 CK与Mysql数据类型对照
 )
) )
) )
) )
)6 SQL语法-常用介绍
6.1 DDL
6.1.1 创建数据库:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster];如果CREATE 语句中存在IF NOT EXISTS 关键字,则当数据库已经存在时,该语句不会创建数据库,且不会返回任何错误。
ON CLUSTER 关键字用于指定集群名称,在集群环境下必须指定该参数,否则只会在链接的节点上创建。
6.1.2 创建本地表:
CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = engine_name()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...];选项描述:
- db:指定数据库名称,如果当前语句没有包含‘db’,则默认使用当前选择的数据库为‘db’。
- cluster:指定集群名称,目前固定为default。ON CLUSTER 将在每一个节点上都创建一个本地表。
- type:该列数据类型,例如 UInt32。
- DEFAULT:该列缺省值。如果INSERT中不包含指定的列,那么将通过表达式计算它的默认值并填充它(与mysql一致)。
- MATERIALIZED:物化列表达式,表示该列不能被INSERT,是被计算出来的; 在INSERT语句中,不需要写入该列;在SELECT * 查询语句结果集不包含该列;需要指定列表来查询(虚拟列)
- ALIAS :别名列。这样的列不会存储在表中。 它的值不能够通过INSERT写入,同时SELECT查询使用星号时,这些列也不会被用来替换星号。 但是它们可以用于SELECT中,在这种情况下,在查询分析中别名将被替换。
- 物化列与别名列的区别: 物化列是会保存数据,查询的时候不需要计算,而别名列不会保存数据,查询的时候需要计算,查询时候返回表达式的计算结果
以下选项与表引擎相关,只有MergeTree系列表引擎支持:
- PARTITION BY:指定分区键。通常按照日期分区,也可以用其他字段或字段表达式。(定义分区键一定要考虑清楚,它影响数据分布及查询性能)
- ORDER BY:指定 排序键。可以是一组列的元组或任意的表达式。
- PRIMARY KEY: 指定主键,默认情况下主键跟排序键相同。因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
- SAMPLE BY :抽样表达式,如果要用抽样表达式,主键中必须包含这个表达式。
- SETTINGS:影响 性能的额外参数。
- GRANULARITY :索引粒度参数。
示例,创建一个本地表:
CREATE TABLE ontime_local ON CLUSTER default -- 表名为 ontime_local
(
Year UInt16,
Quarter UInt8,
Month UInt8,
DayofMonth UInt8,
DayOfWeek UInt8,
FlightDate Date,
FlightNum String,
Div5WheelsOff String,
Div5TailNum String
)ENGINE = ReplicatedMergeTree(--表引擎用ReplicatedMergeTree,开启数据副本的合并树表引擎)
'/clickhouse/tables/ontime_local/{shard}', -- 指定存储路径
'{replica}')
PARTITION BY toYYYYMM(FlightDate) -- 指定分区键,按FlightDate日期转年+月维度,每月做一个分区
PRIMARY KEY (intHash32(FlightDate)) -- 指定主键,FlightDate日期转hash值
ORDER BY (intHash32(FlightDate),FlightNum) -- 指定排序键,包含两列:FlightDate日期转hash值、FlightNunm字符串。
SAMPLE BY intHash32(FlightDate) -- 抽样表达式,采用FlightDate日期转hash值
SETTINGS index_granularity= 8192 ; -- 指定index_granularity指数,每个分区再次划分的数量6.1.3 创建分布式表
基于本地表创建一个分布式表。基本语法:
CREATE TABLE [db.]table_name ON CLUSTER default
AS db.local_table_name
ENGINE = Distributed(<cluster>, <database>, <shard table> [, sharding_key])参数说明:
- db:数据库名。
- local_table_name:对应的已经创建的本地表表名。
- shard table:同上,对应的已经创建的本地表表名。
- sharding_key:分片表达式。可以是一个字段,例如user_id(integer类型),通过对余数值进行取余分片;也可以是一个表达式,例如rand(),通过rand()函数返回值/shards总权重分片;为了分片更均匀,可以加上hash函数,如intHash64(user_id)。
示例,创建一个分布式表:
CREATE TABLE ontime_distributed ON CLUSTER default -- 指定分布式表的表名,所在集群
AS db_name.ontime_local -- 指定对应的 本地表的表名
ENGINE = Distributed(default, db_name, ontime_local, rand()); -- 指定表引擎为Distributed(固定)6.1.4 其他建表
clickhouse还支持创建其他类型的表:
 )
)6.1.5 修改表
语法与mysql基本一致:
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN …
支持下列动作:
- ADD COLUMN — 添加列
- DROP COLUMN — 删除列
- CLEAR COLUMN — 重置列的值
- COMMENT COLUMN — 给列增加注释说明
- MODIFY COLUMN — 改变列的值类型,默认表达式以及TTL
举例:ALTER TABLE bd01.table_1 ADD COLUMN browser String AFTER name; – 在name列后面追加一列
6.2 DML
 )
)注意:
- 索引列不支持更新、删除
- 分布式表不支持更新、删除
7 复杂查询JOIN
所有标准 SQL JOIN 支持类型(INNER和OUTER可以省略):
- INNER JOIN,只返回匹配的行。
- LEFT OUTER JOIN,除了匹配的行之外,还返回左表中的非匹配行。
- RIGHT OUTER JOIN,除了匹配的行之外,还返回右表中的非匹配行。
- FULL OUTER JOIN,除了匹配的行之外,还会返回两个表中的非匹配行。
- CROSS JOIN,产生整个表的笛卡尔积, “join keys” 是 不 指定。
查询优化:
- A join B 的查询,比from A,B,C 多表的性能高很多
- global join 会把书记发送给所有节点参与计算,针对较小的维度表性能较好
- JOIN会在背地节点操作,适合于相同分片字段的两张表关联(A表与B表的分片字段都包含字段M)
- IN的性能比JOIN好,优先使用JOIN
- 先过滤再join效率更好(减低每个分片关联数据量级)
- 在做多表join时,A表的查询过滤条件中如果能包含与B表的ON expr中字段过滤条件,性能更好
- join的顺序,大表在左,小表在右;ck查询时会从右向左执行
对比JOIN与IN的查询复杂度:
CK常用的表引擎会是分布式存储,因此查询过程一定是每个分片进行一次查询,这就导致了sql的复杂度越高,查询锁扫描的分片数量越多,耗时也就越久。
假设AB两个表,分别存储在10个分片中,join则是查询10次A表的同时,join10次B表,合计要10*10次。采用Global join则会先查询10次并生成临时表,再用临时表取和B表join,合计要10+10次。
这算是分布式架构的查询特点,如果能干预数据分片规则,如果查询条件中带有分片列,则可以直接定位到包含数据的分片上,从而减小查询次数。
CK对于join语法上虽然支持,但是性能并不高。当join的左边是子查询结果时,ck是无法进行分布式join的。
8 MySQL迁移到CK
- 数据同步成本:clickhouse可以做到与mysql的表结构一致,进而数据同步成本较低,不需要调整数据结构、不需要额外做宽表处理(当然转为宽表效率更高)。
- SQL迁移成本:支持jdbc、mybatis接入;支持标准SQL的语法;支持join、in、函数,SQL迁移成本较低。
当然如果花功夫对表结构、SQL、索引等进行优化,能得到更好的查询效率。
官方支持
在2020年下半年,Yandex 公司在 ClickHouse 社区发布了MaterializeMySQL引擎,支持从MySQL全量及增量实时数据同步。MaterializeMySQL引擎目前支持 MySQL 5.6/5.7/8.0 版本,兼容 Delete/Update 语句,及大部分常用的 DDL 操作。
也就是说,CK支持作为MySQL的从节点存在,依赖订阅binlog方式实现。
https://bbs.huaweicloud.com/blogs/238417
9 总结
ClickHouse更加适合OLAP场景,在报表库中有极大性能优势。如果想作为应用数据库,可以灵活采用其表引擎特点,尽量避免数据修改。其实,没有最好的,只有最合适的。
作者:京东物流 耿宏宇
来源:京东云开发者社区








