1 背景
http请求是常见的一种网页协议,我们看到的各种网页,其实都是发送了http请求得到了服务器的响应,从而将数据库中复杂的数据以简单、直观的方式呈现出来,方便大众阅读、使用。而如何发送http请求呢?今天来探讨一下使用requests模块,达到高效、简单的http请求操作。
2 什么是requests
requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,虽然标准库中的urllib2模块已经包含了平时我们使用的大多数功能,但是urllib2的API使用起来并不太友好,而requests自称“HTTP for Humans”,经过高度封装以后,可以直接调用此库的相关函数,非常方便帮助我们实现爬取HTML网页页面、模拟自动提交网络请求等操作。
 )
)requests模块一直在迭代更新,以完全适应当前的所有网络请求。
 )
)支持的 HTTP 特性:
- 保持活动和连接池
- 国际域名和 URL
- Cookie 持久性会话
- 浏览器式 SSL 验证
- 自动内容解码
- 基本 / 摘要身份验证
- 优雅的键 / 值 Cookie
- 自动减压
- Unicode 响应机构
- HTTP(S)代理支持
- 分段文件上传
- 流下载
- 连接超时
- 分块请求
- .netrc 支持
- 线程安全
3 如何安装
安装requests模块与安装其他python模块一样,使用pip命令安装即可。
pip install requests
# 如需指定版本
pip install requests==2.27.14 如何使用
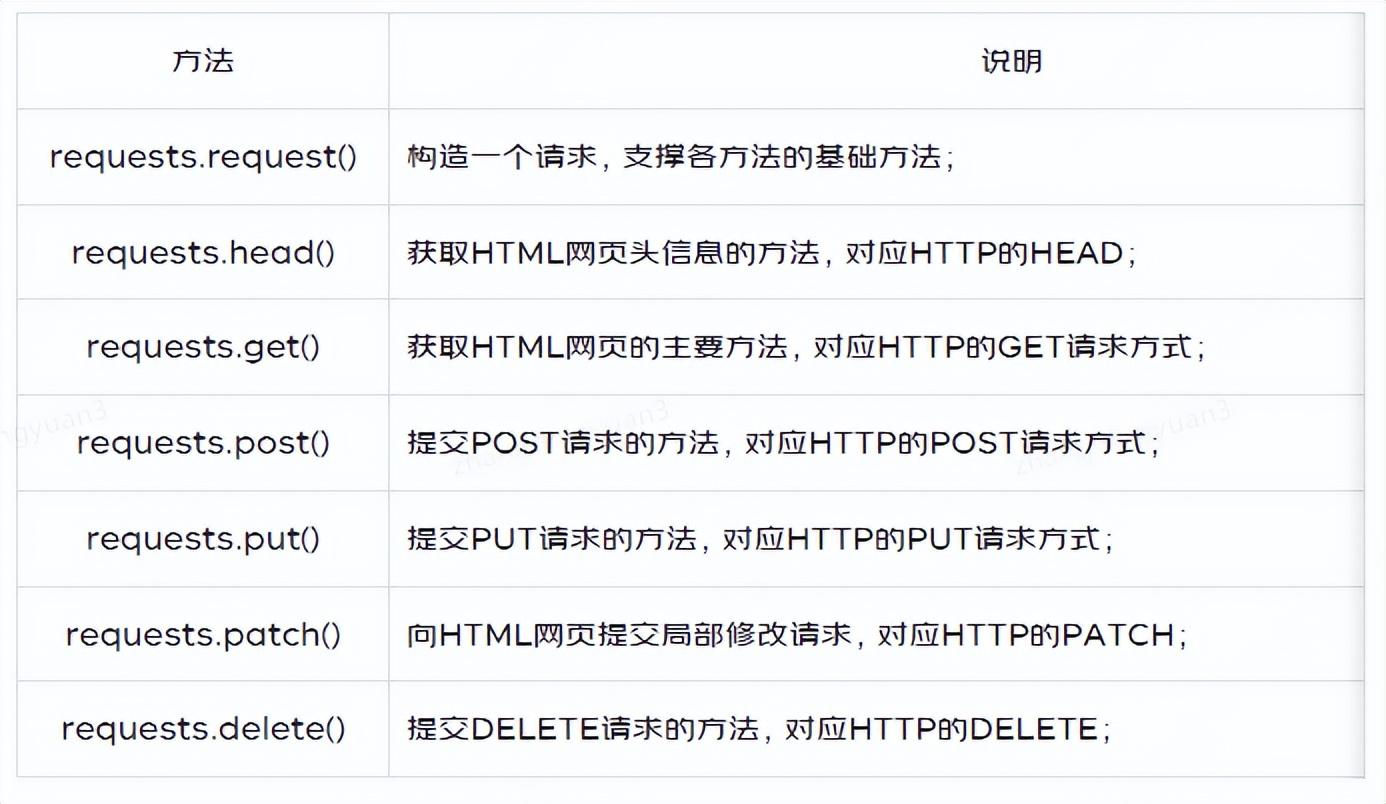
4.1 七个主要方法
 )
)4.2 HTTP协议对资源的操作
 )
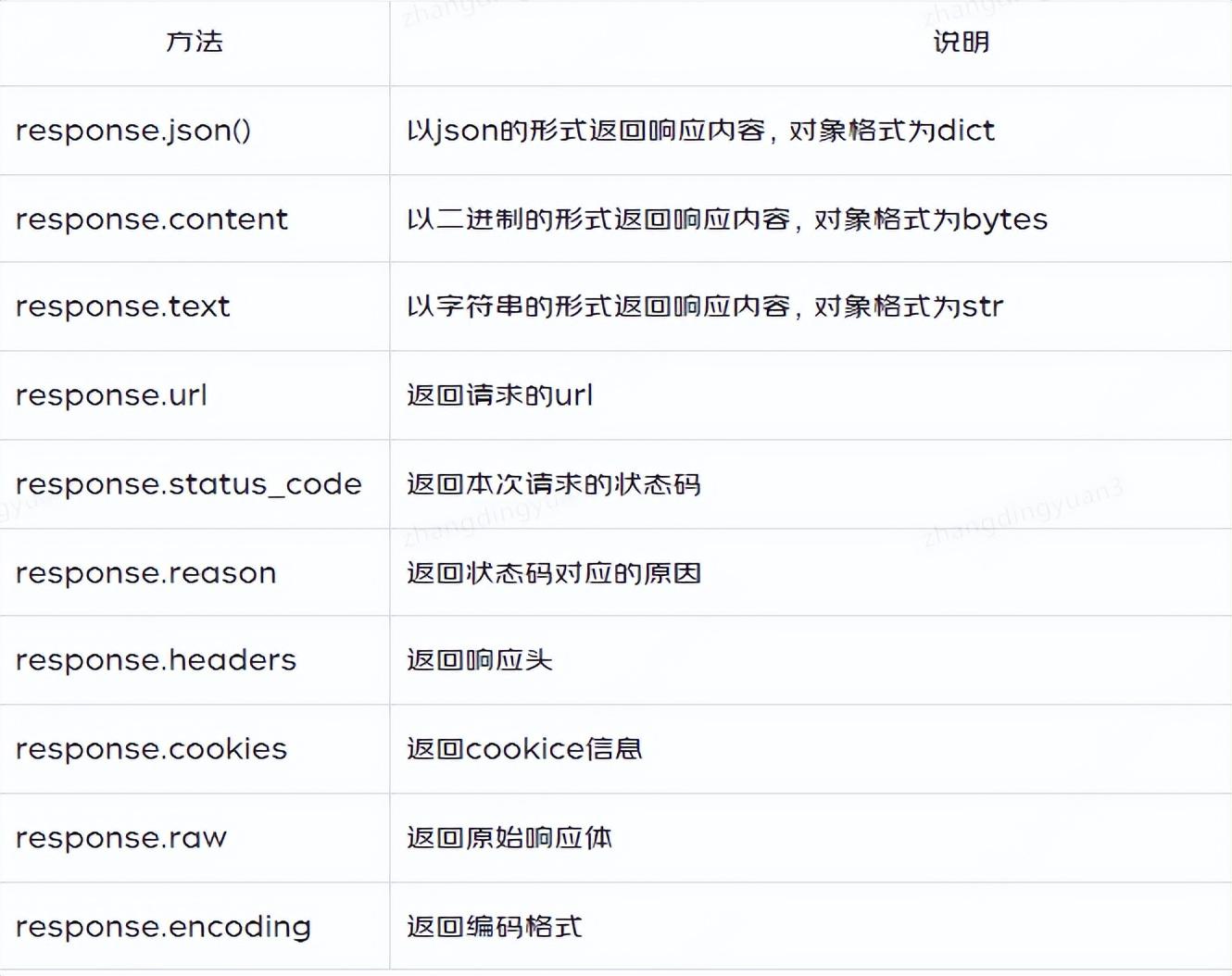
)4.3 响应公共方法
 )
)4.4 常用方式举例
4.4.1 requests.request()
method:提交方式(get|post);
url:提交地址;
kwargs:14个控制访问的参数;
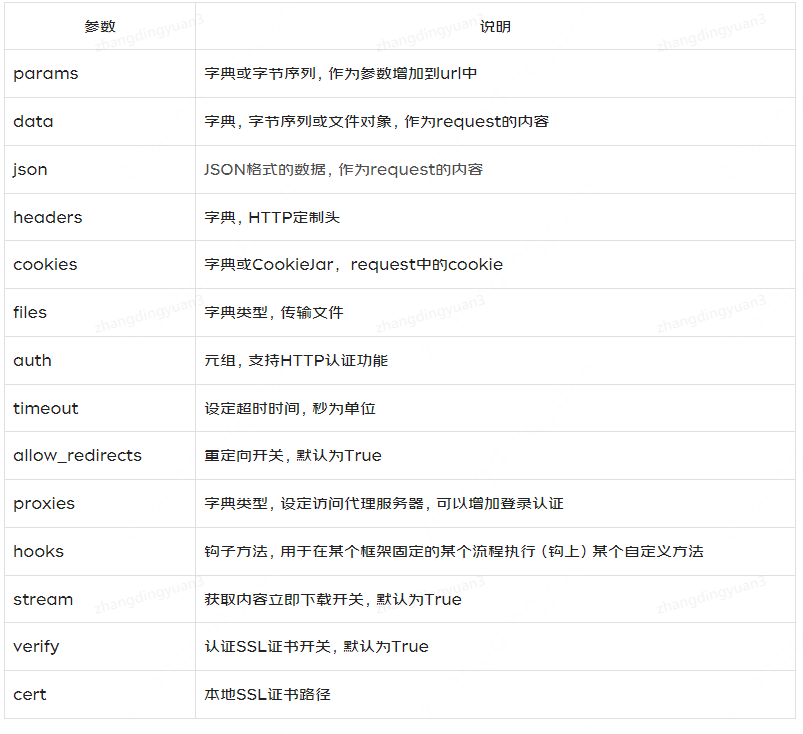 )
)常用的参数有:params、data、json、headers、cookies,其他参数讲解与示例将在(二)中进行介绍。
示例:
- params:在url上传递的参数,GET形式传递到后台。
import requests
requests.request(
method = 'GET',
url = 'http://127.0.0.1:8080/example/request',
# 字典
data= { 'k1' : 'v1' , 'k2' : 'v2' , 'x':[1,2,3]}
# 字符串
data="k1=v1&k2=v2&x=[1,2,3]"
# 字节
data = bytes("k1=v1&k2=k2&x=[1,2,3]", encoding='utf8')
)
# http://www.oldboyyede.com?k1=v1&k2=v2- data:在请求体里面传递的数据,后面可以是字典,字节等数据类型。
import requests
requests.request(
method = 'POST',
url = 'http://127.0.0.1:8080/example/request',
# 字典
data= { 'k1' : 'v1' , 'k2' : 'v2' , 'x':[1,2,3]}
# 字符串
data="k1=v1&k2=v2&x=[1,2,3]"
# 字节
data = bytes("k1=v1&k2=k2&x=[1,2,3]", encoding='utf8')
# 文件对象
data = open('data_file.py', mode='r', encoding='utf-8')
)- json:在请求体里面传递数据,把整体序列化成一个大字符串,字典中嵌套字典的话用JSON序列化。
import requests
requests.request(
method = 'POST',
url = 'http://127.0.0.1:8080/example/request',
json = {'k1' : 'v1', 'k2' : 'v2'}
# "{ 'k1' : 'v1' , 'k2' : 'v2' }"
# 字典嵌套字典
json = json.dumps({'k1' : 'v1' , 'k2' : { 'kk1' : vv1 }})
)- headers:在请求体中添加请求头
import requests
requests.request(method='POST',
url='http://127.0.0.1:8080/example/request',
json={'k1': 'v1', 'k2': 'v2'},
headers={'Content-Type': 'application/x-www-form-urlencoded'}
)- cookies:在请求体中添加cookie
import requests
requests.request(method='POST',
url='http://127.0.0.1:8080/example/request',
data={'k1': 'v1', 'k2': 'v2'},
cookies={'cookie_example': 'cookie_value1'},
)
# 也可以使用CookieJar(字典形式就是在此基础上封装)
from http.cookiejar import CookieJar
from http.cookiejar import Cookie
obj = CookieJar()
# 构建cookie
obj.set_cookie(
Cookie(
version=0,
name='c1',
value='v1',
port=None,
domain='',
path='/',
secure=False,
expires=None,
discard=True,
comment=None,
comment_url=None,
rest={'HttpOnly': None},
rfc2109=False,
port_specified=False,
domain_specified=False,
domain_initial_dot=False,
path_specified=False)
)
# 发送请求
requests.request(method='POST',
url='http://127.0.0.1:8080/example/request',
data={'k1': 'v1', 'k2': 'v2'},
cookies=obj
)4.4.2 requests.get()
构造一个向服务器请求资源的request对象,然后返回一个包含服务器资源的response对象。
url:网址链接地址;
params:在url上传递的参数,以GET形式传递到后台,可为字典或字节流格式;
kwargs:14个控制访问的参数;
示例:
import requests
# 1、基本GET实例
# 设置url
url="http://127.0.0.1:8080/example/get"
# 调用get方法发送请求
response = requests.get(url)
# 打印请求状态码
print(response.status_code)
# 打印响应内容
print(response.text)
# 打印编码方式
print(response.encoding)
# 打印二进制形式内容
print(response.content)
# 2、带参数与请求头
url = "http://127.0.0.1:8080/example/get"
params = { "username": "admin" }
header = {'User-Agent': 'chrome'}
# 将请求伪装成谷歌浏览器chrome进行访问后的User-Agent,发送GET请求接口信息
response = requests.get(url=url,params=params,headers=header)
# 如接口返回数据格式为json格式
print(response.json())
# 结果为:{ "code": 200, "msg": "请求成功", "data": [{...}] }4.4.3 requests.head()
构造一个向服务器请求资源的request对象,获取HTML网页头信息。
url:网址链接地址;
kwargs:14个控制访问的参数;
示例:
import requests
url = "http://127.0.0.1:8080/example/get"
response = requests.head(url)
# 打印请求头信息
print(response.headers)注:部分网址请求时,可能会遇到网络防火墙,此时添加浏览器请求头信息,可避免此类问题发生。
另外,在发送一些请求时,如:网络爬虫时,如不加headers,将会被网站识别出是python程序请求,可以使用真实的浏览器信息头,模拟发生请求(警语:请遵守爬虫Robots协议)。
 )
)import requests
url = "127.0.0.1:8080/example/get"
header = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
response = requests.get(url=url, headers=header)
# 打印请求状态码
print(response.status_code)
# 2004.4.4 requests.post()
构造一个向服务器请求资源的request对象,然后返回一个包含服务器资源的response对象。
url:网址链接地址;
kwargs:14个控制访问的参数;
示例:
# 1、基本POST实例
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
ret = requests.post("http://127.0.0.1:8080/example/post", data=payload)
print(ret.text)
# 2、发送请求头和数据实例
import requests
import json
url = 'http://127.0.1:8080/example/post'
payload = {'some': 'data'}
headers = {'content-type': 'application/json'}
response = requests.post(url, data=json.dumps(payload), headers=headers)
# 打印响应内容
print(response.text)
# 打印cookie
print(response.cookies)4.4.5 其他请求
import requests
requests.put(url, data=None, **kwargs)
requests.head(url, **kwargs)
requests.delete(url, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.options(url, **kwargs)
# 以上方法均是在此方法的基础上构建
requests.request(method, url, **kwargs)5 本期常见问题
1.打印text时,出现乱码
答:1、查看是否正确配置encoding;2、查看是否为图片,图片数据为二进制数据,将图片转化为str的字符串类型,就会出现乱码。
2.打印content时,出现“\x00\x00”等内容:
答:在python中,b开头的内容,表示为bytes类型的数据。
作者:京东物流 骆铜磊
来源:京东云开发者社区