
一、Paxos是什么
在分布式系统中保证多副本数据强一致性算法。
没有paxos的一堆机器, 叫做分布式
有paxos协同的一堆机器, 叫分布式系统
这个世界上只有一种一致性算法,那就是Paxos … - Google Chubby的作者Mike Burrows
其他一致性算法都可以看做Paxos在实现中的变体和扩展,比如raft。
二、先从复制算法说起
防止数据丢失,所以需要数据进行复制备份
2.1 主从异步复制
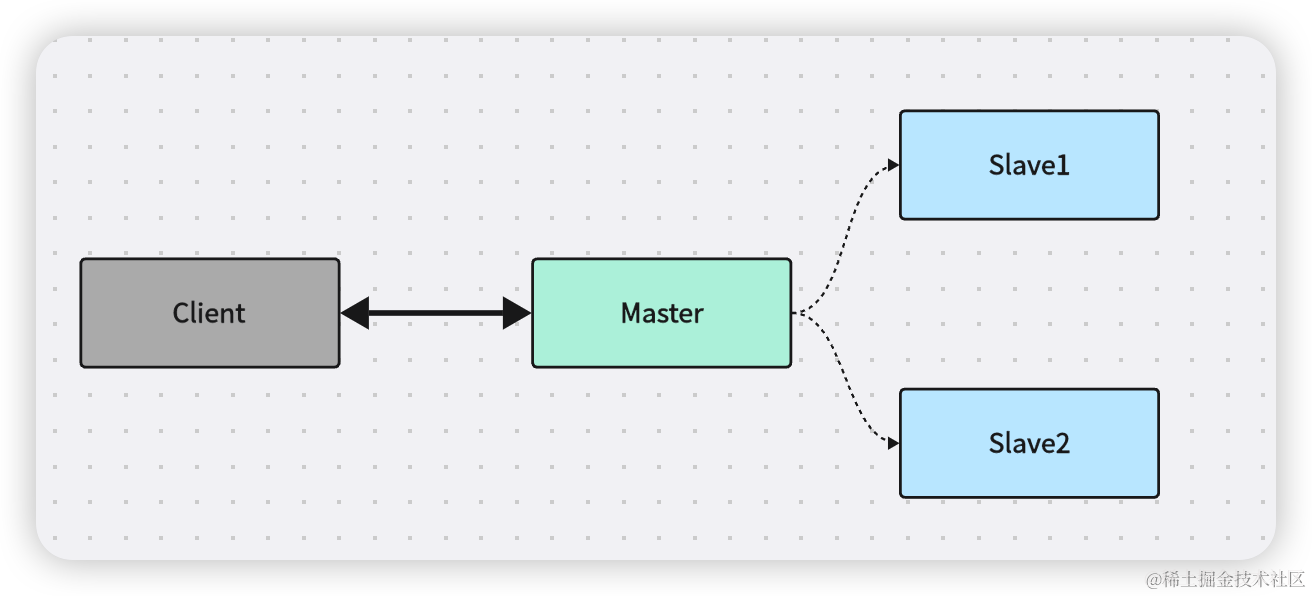
主节点接到写请求,主节点写本磁盘,主节点应答OK,主节点复制数据到从节点
如果数据在数据复制到从节点之前损坏,数据丢失。
2.2 主从同步复制
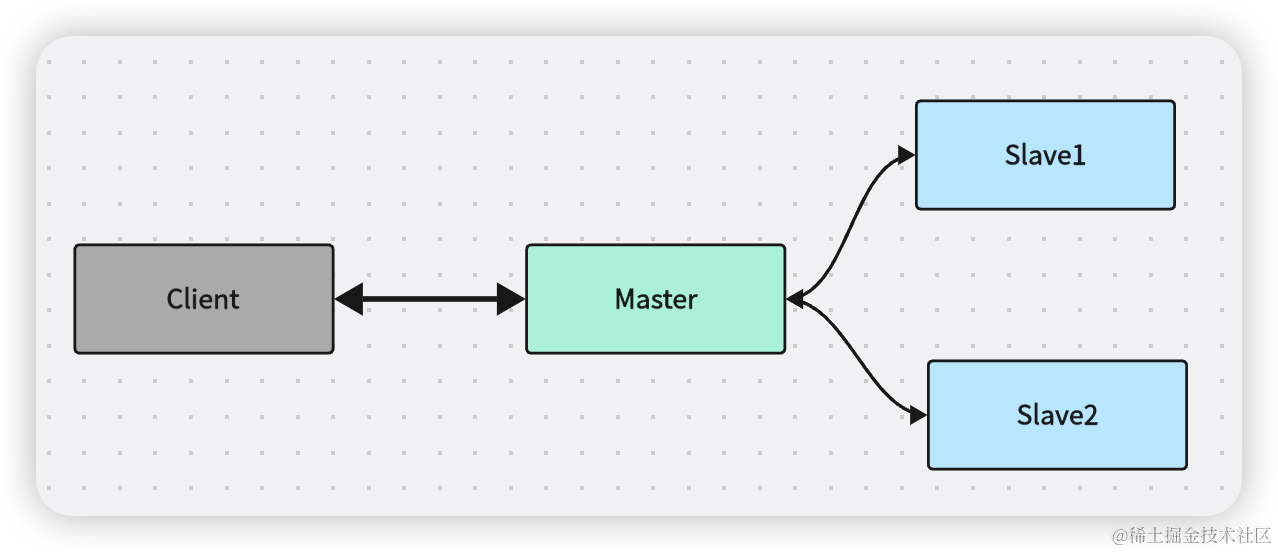
主节点接到写请求,主节点复制日志到所有从节点,从节点可能会阻塞,客户端一直等待应答,直到所有从节点返回
一个节点失联导致整个系统不可用,整个可用性的可用性比较低
2.3 主从半同步复制
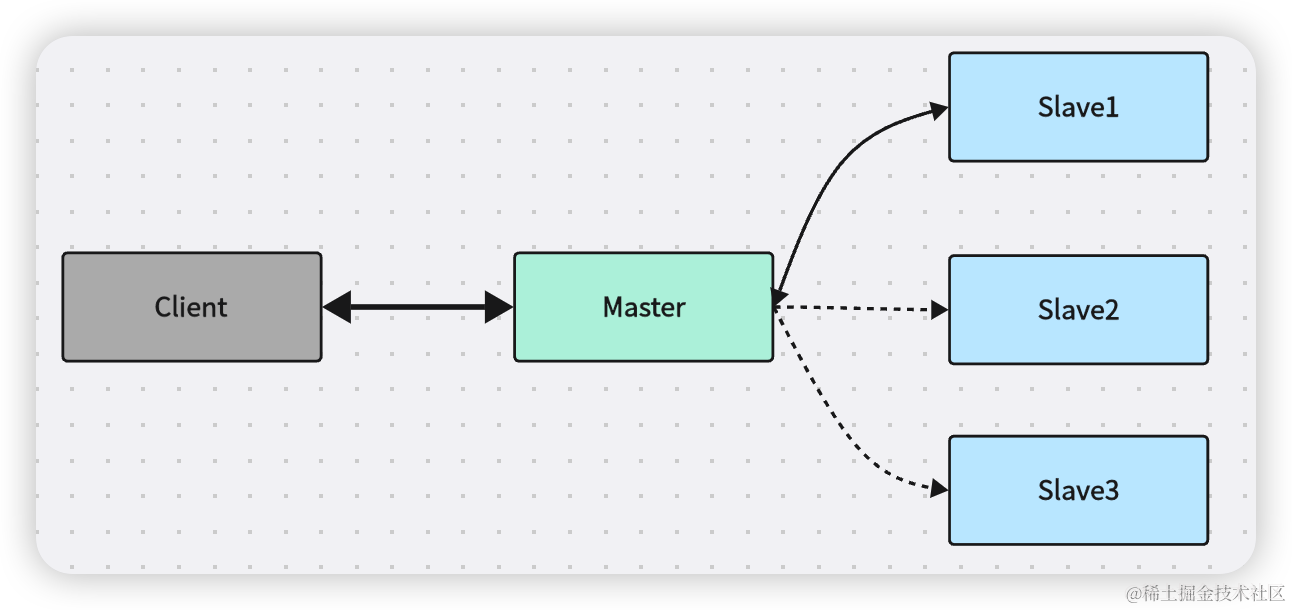
主接到写请求,主复制日志到从库,从库可能阻塞,如果1~N个从库返回OK,客户端返回OK
可靠性和可用性得到了保障,但是可能任何从库都没有完整数据
2.4 多数派写读
往一个主接节点写入貌似都会出现问题,那我们尝试一下往多个节点写入,舍弃主节点。
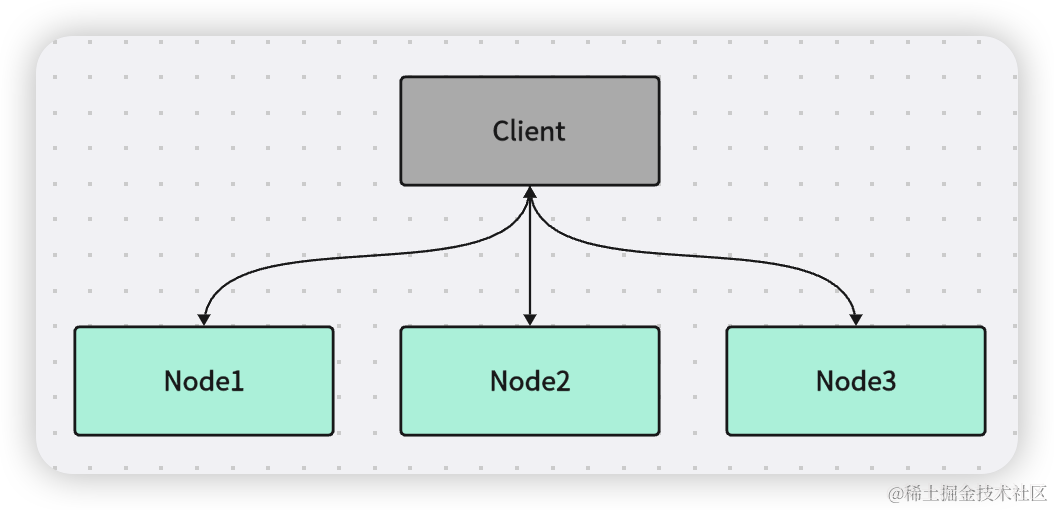
客户端写入 W >= N / 2 + 1个节点, 读需要 W + R > N, R >= N / 2 + 1,可以容忍 (N - 1)/ 2 个节点损坏
最后一次写入覆盖先前写入,需要一个全局有序时间戳。
多数派写可能会出现什么问题?怎么解决这些问题呢?
三、从多数派到Paxos的推导
假想一个存储系统,满足以下条件:
- 有三个存储节点 2. 使用多数派写策略 3. 假定只存储一个变量i 4. 变量i的每次更新对应多个版本,i1,i2, i3..... 5. 该存储系统支持三个命令: 1. get 命令,读取最新的变量i,对应多数派读 2. set
命令,设置下版本的变量i的值 ,直接对应的多数派写 3. inc 命令, 对变量i增加 ,也生成一个新版本,简单的事务型操作
3.1 inc的实现描述
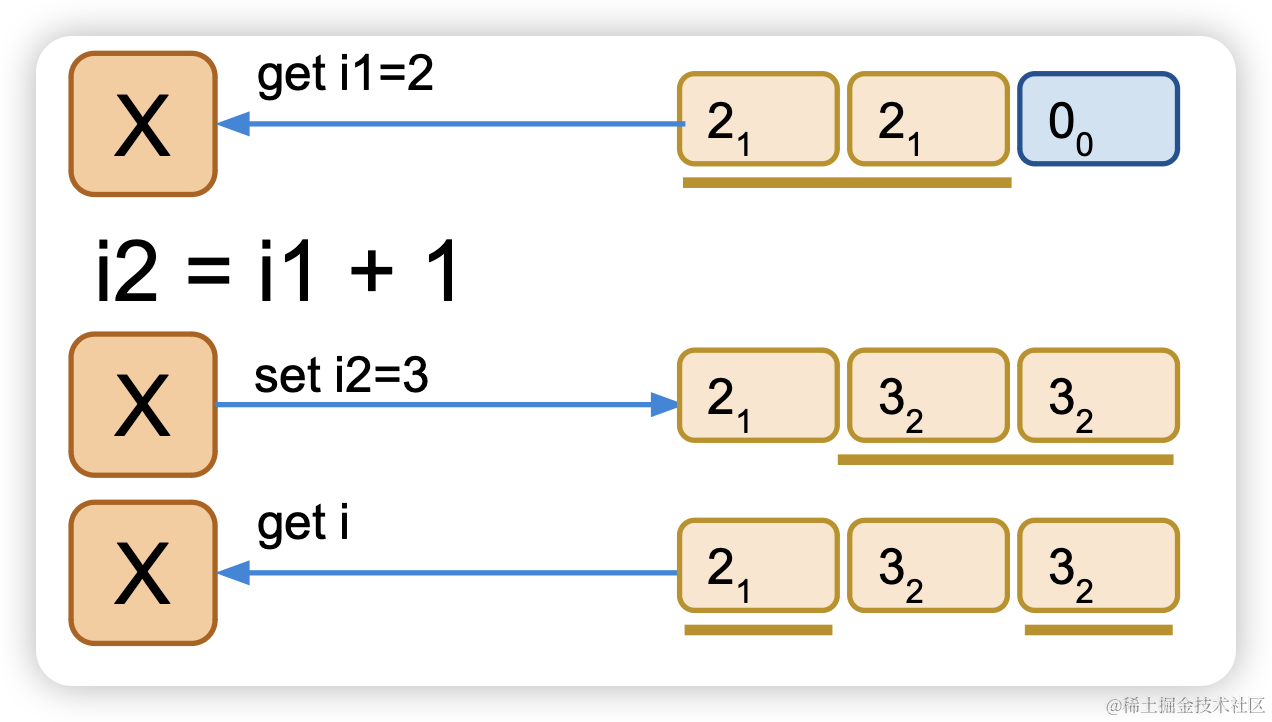
从多数中读取变量i,i当前版本1
进行计算,i2 = i1 + n,i变更,版本+1
多数派写i2,写入i,当前版本2
获取i,最新版本是2
这种实现方式存在一下问题:
如果2个并发的客户端同时进行inc操作,必然会产生Y客户端覆盖X客户端的问题,从而产生数据更新丢失
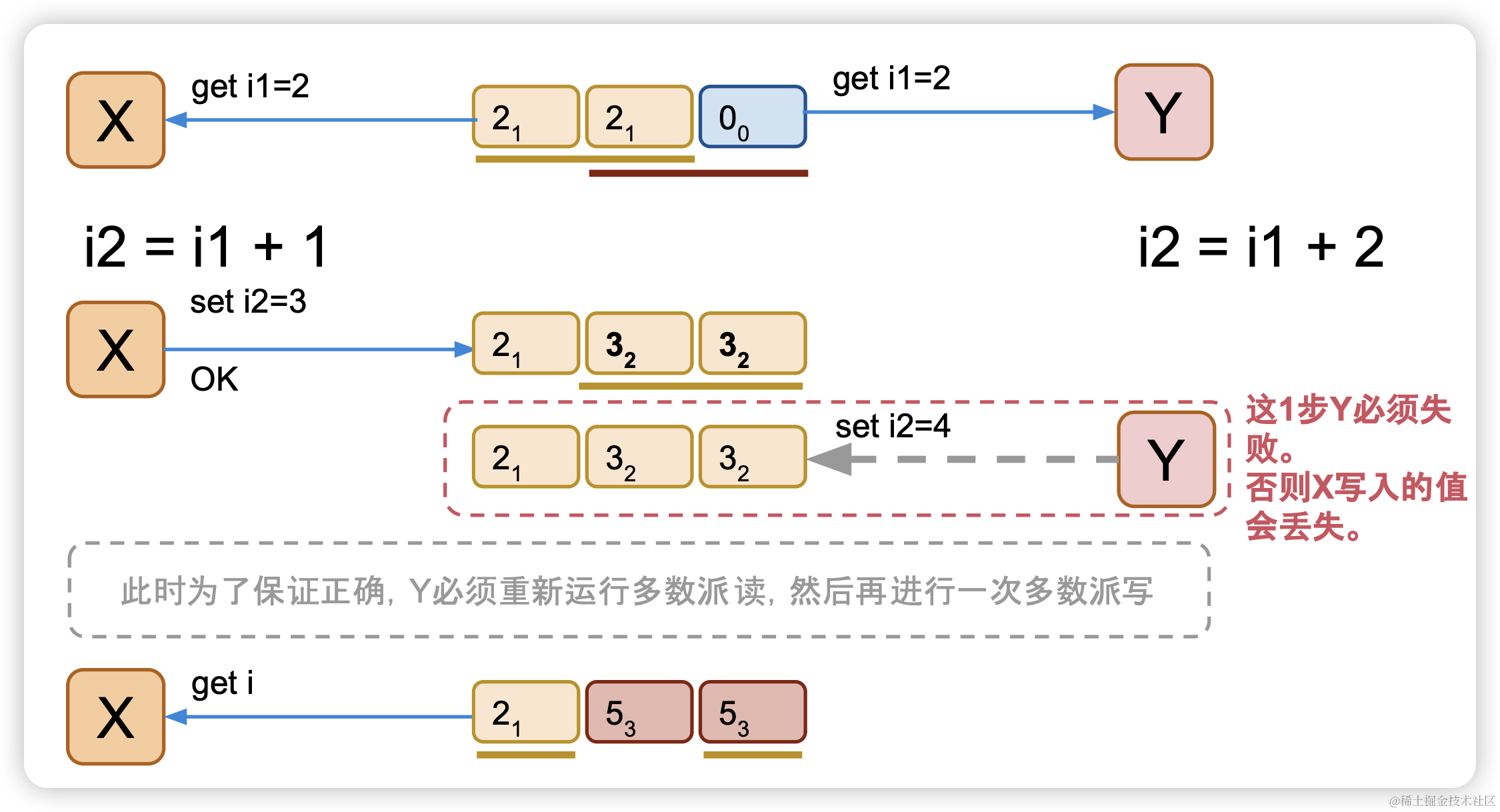
假设X,Y两个客户端,X客户端执行命令inc 1,Y客户端执行inc 2,我们期望最终变量i会加3
但是实际上会出现并发冲突
X客户端读取到变量i版本1的值是2
同时客户端Y读取到变量i版本1的值也是2
X客户端执行i1 + 1 = 3,Y客户端执行i1 + 2 = 4
X执行多数派写,变量i版本2的值是2,进行写入(假定X客户端先执行)
Y执行多数派写,变量i版本2的值是4,进行写入(如果Y成功,会把X写入的值覆盖掉)
所以Y写入操作必须失败,不能让X写入的值丢失 。 但是该怎么去做呢?
3.2 解决多数派写入冲突
我们发现,客户端X,Y写入的都是变量i的版本2,那我们是不是可以增加一个约束:
整个系统对变量i的某个版本,只能有一次写入成功。
也就是说,一个值(一个变量的一个版本)被确定(客户端接到OK后)就不允许被修改了。
怎么确定一个值被写入了呢?在X或者Y写之前先做一次多数派读,以便确认是否有其他客户端进程在写了,如果有,则放弃。
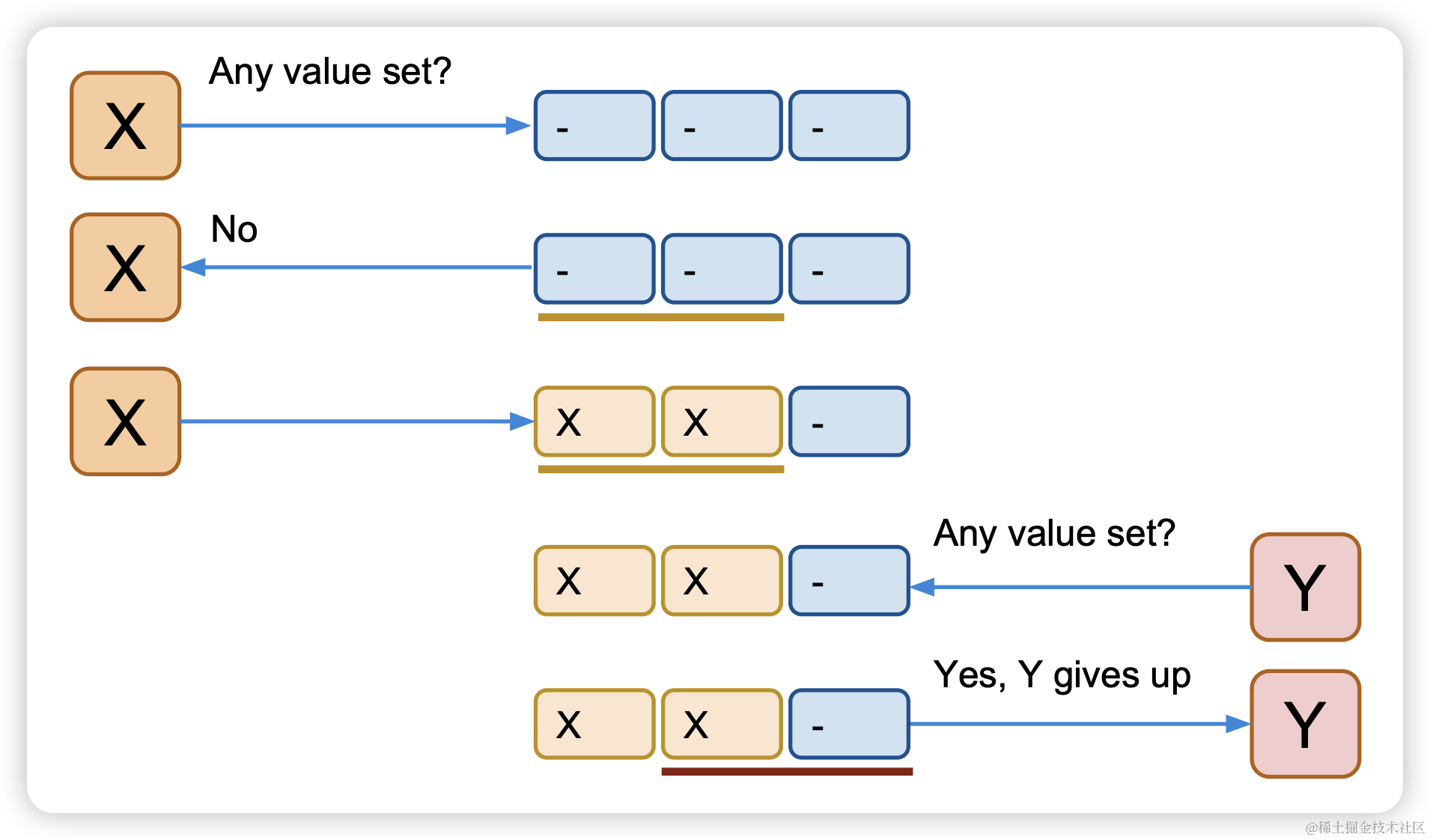
客户端X在执行多数派写之前,先执行一个多数派读,在要写入的节点上标识一下客户端X准备进行写入,这样其他客户端执行的时候看到有X进行写入就要放弃。
但是忽略了一个问题,就是客户端Y写之前也会执行多数派读,那么就会演变成X,Y都执行多数派读的时候当时没有客户端在写,然后在相应节点打上自己要写的标识,这样也会出现数据覆盖。
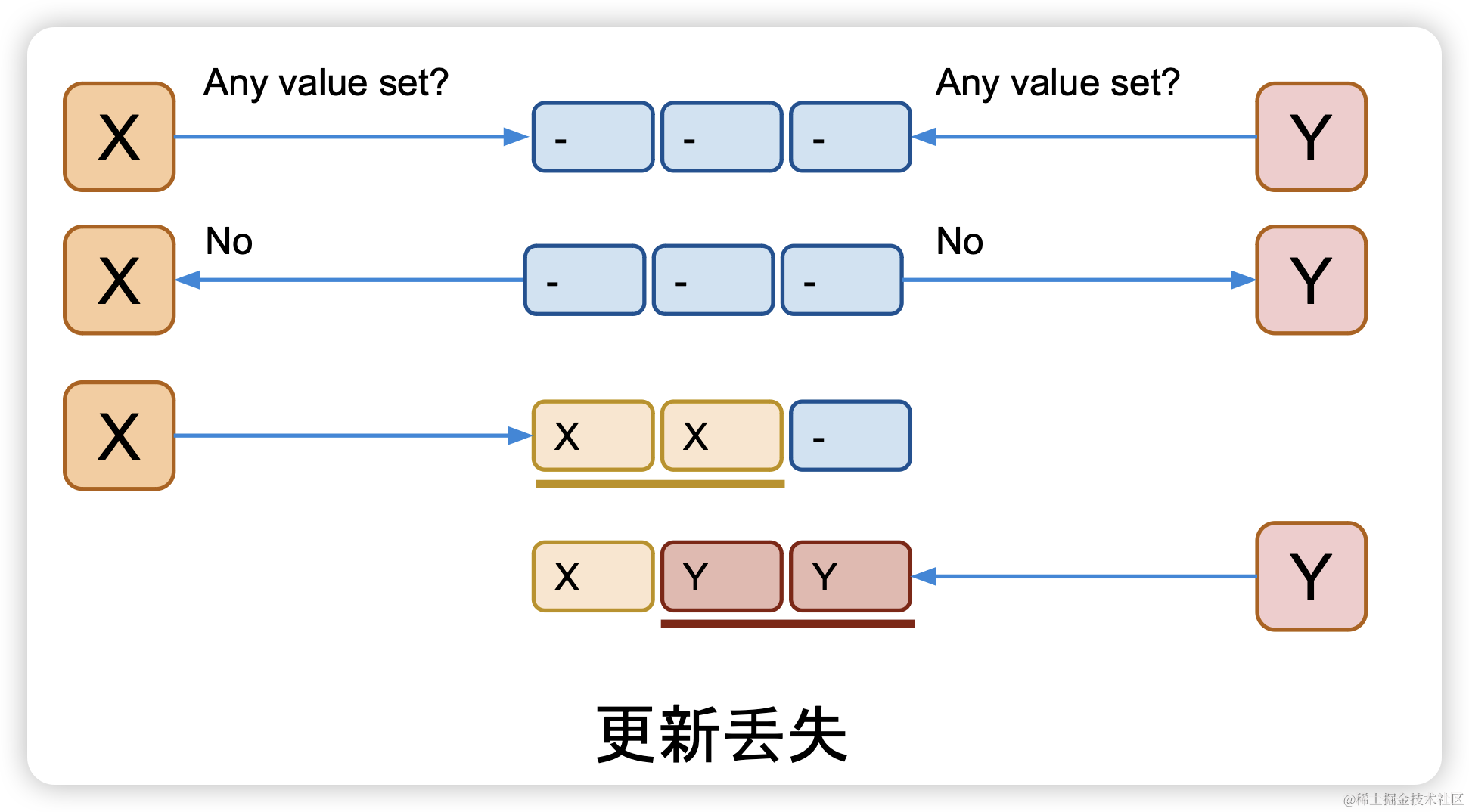
3.3 逐步发现的真相
既然让客户端自己标识会出现数据丢失问题,那我们可以让节点来记住最后一个做过写前读取的进程,并且只允许最后一个完成写前读取的进程进行后续写入,拒绝之前做过写前读取进行的写入权限。
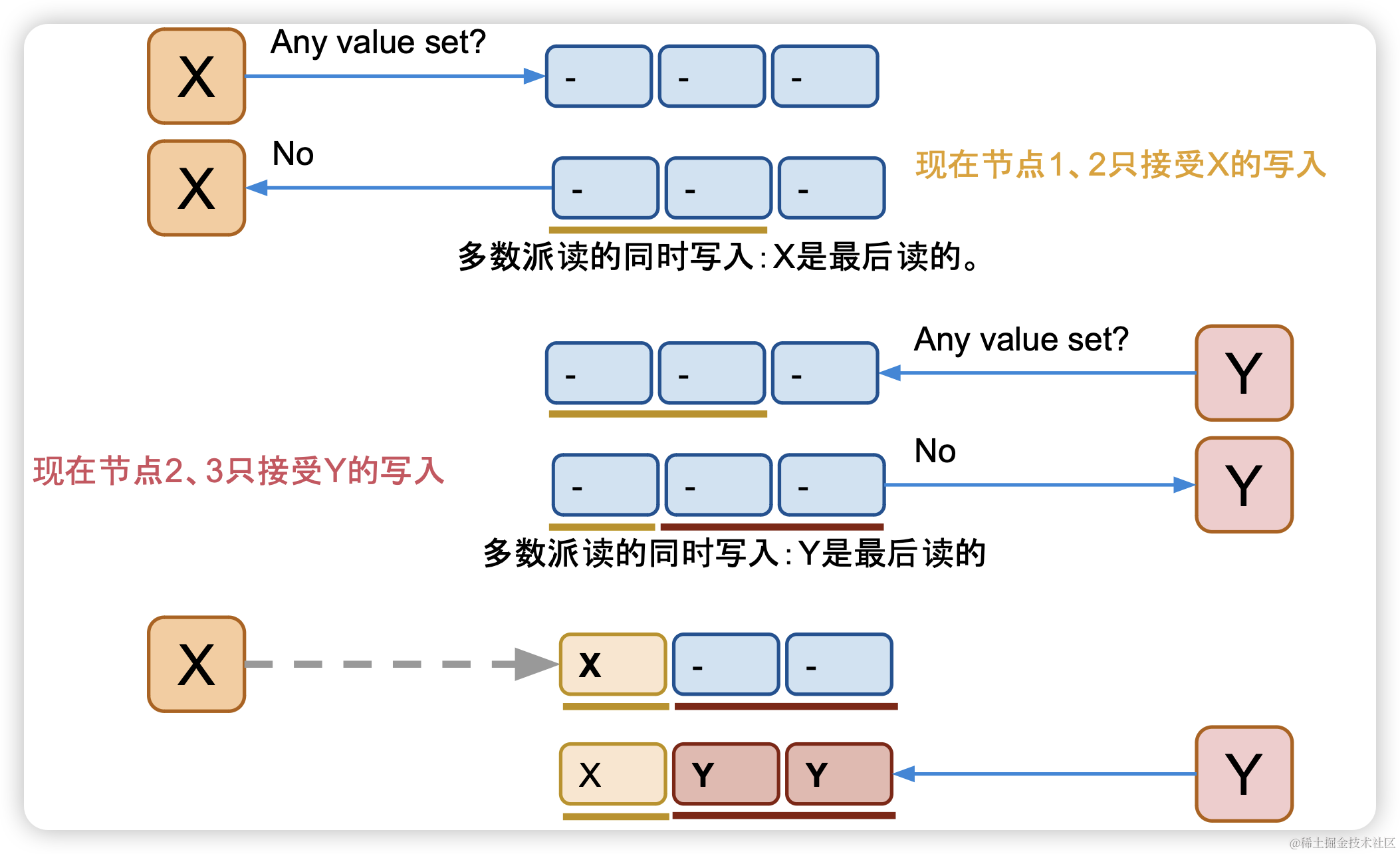
X,Y同时进行写前读取的时候,节点记录最后执行一个执行的客户端,然后只允许最后一个客户端进行写入操作。
使用这个策略变量i的每个版本可以被安全的存储。
然后Leslie Lamport写了一篇论文,并且获得了图灵奖。
四、重新描述一下Paxos的过程(Classic Paxos)
使用2轮RPC来确定一个值,一个值确定之后不能被修改,算法中角色描述:
•Proposer 客户端
•Acceptor 可以理解为存储节点
•Quorum 在99%的场景里都是指多数派, 也就是半数以上的Acceptor
•Round 用来标识一次paxos算法实例, 每个round是2次多数派读写: 算法描述里分别用phase-1和phase-2标识. 同时为了简单和明确, 算法中也规定了每个Proposer都必须生成全局单调递增的round, 这样round既能用来区分先后也能用来区分不同的Proposer(客户端).
4.1 Proposer请求使用的请求
// 阶段一 请求
class RequestPhase1 {
int rnd; // 递增的全局唯一的编号,可以区分Proposer
}// 阶段二 请求
class RequestPhase2 {
int rnd; // 递增的全局唯一的编号,可以区分Proposer
Object v; // 要写入的值
}4.2 Acceptor 存储使用的应答
// 阶段一 应答
class ResponsePhase1 {
int last_rnd; // Acceptor 记住的最后一次写前读取的Proposer,以此来决定那个Proposer可以写入
Object v; // 最后被写入的值
int vrnd; // 跟v是一对,记录了在哪个rnd中v被写入了
}// 阶段二 应答
class ResponsePhase2 {
boolean ok;
}4.3 步骤描述
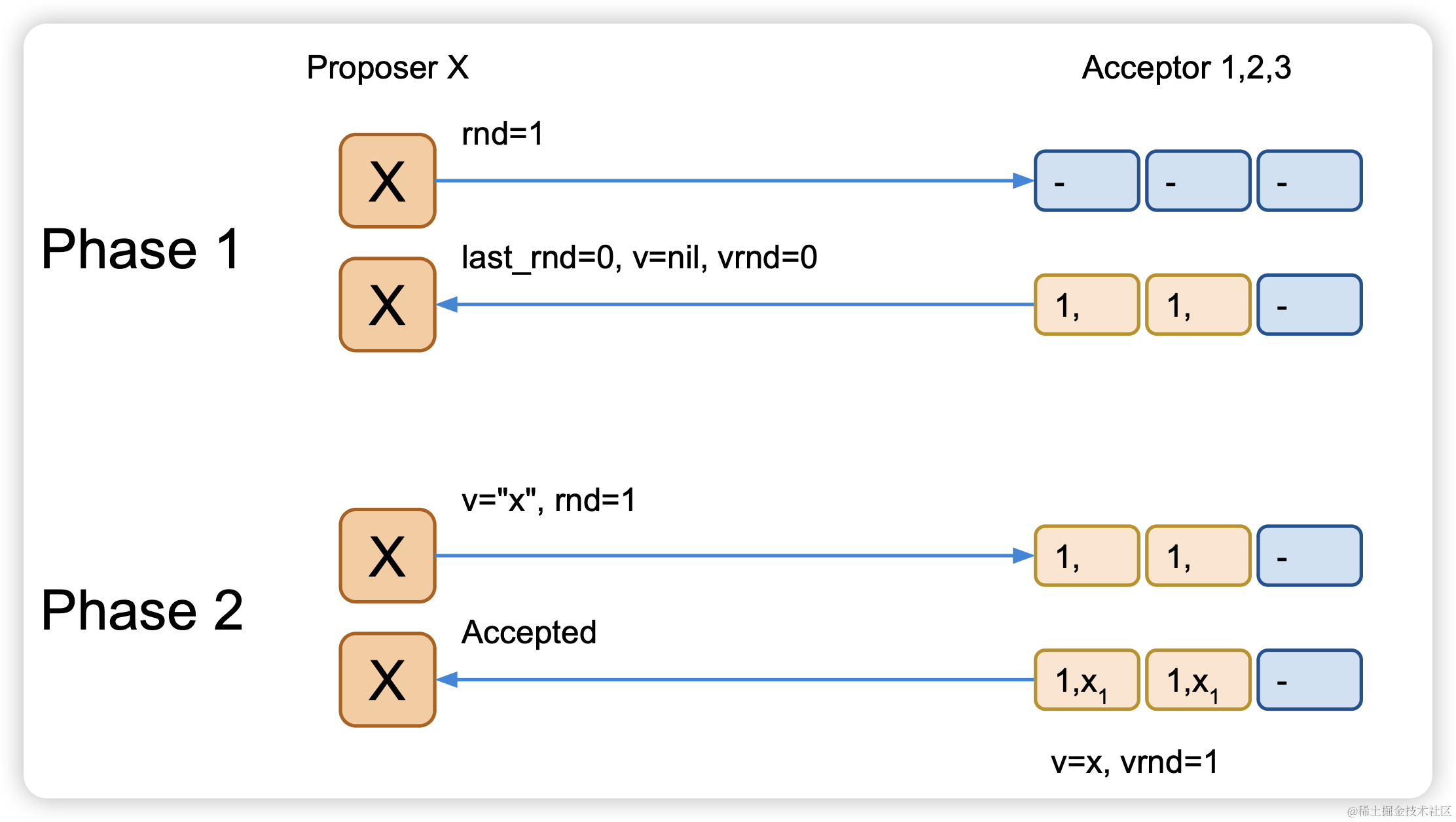
阶段一

当Acceptor收到phase-1的请求时:
● 如果请求中rnd比Acceptor的last_rnd小,则拒绝请求
● 将请求中的rnd保存到本地的last_rnd. 从此这个Acceptor只接受带有这个last_rnd的phase-2请求。
● 返回应答,带上自己之前的last_rnd和之前已接受的v.
当Proposer收到Acceptor发回的应答:
● 如果应答中的last_rnd大于发出的rnd: 退出.
● 从所有应答中选择vrnd最大的v: 不能改变(可能)已经确定的值,需要把其他节点进行一次补偿
● 如果所有应答的v都是空或者所有节点返回v和vrnd是一致的,可以选择自己要写入v.
● 如果应答不够多数派,退出
阶段二:

Proposer:
发送phase-2,带上rnd和上一步决定的v
Acceptor:
● 拒绝rnd不等于Acceptor的last_rnd的请求
● 将phase-2请求中的v写入本地,记此v为‘已接受的值’
● last_rnd==rnd 保证没有其他Proposer在此过程中写入 过其他值
4.4 例子
无冲突:
有冲突的情况,不会改变写入的值
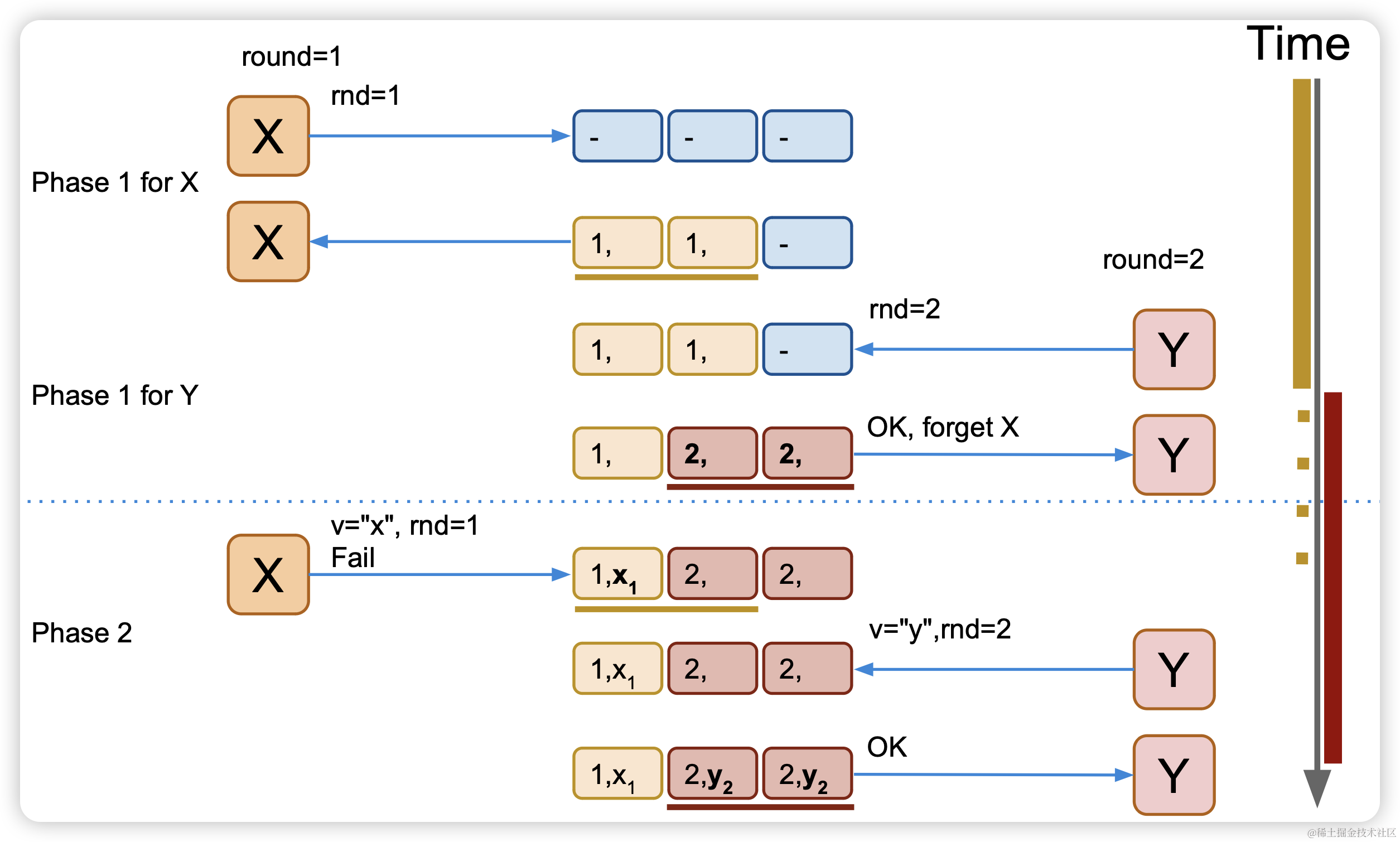
客户端X写入失败,因此重新进行2轮PRC进行重新写入,相当于做了一次补偿,从而使系统最终一致
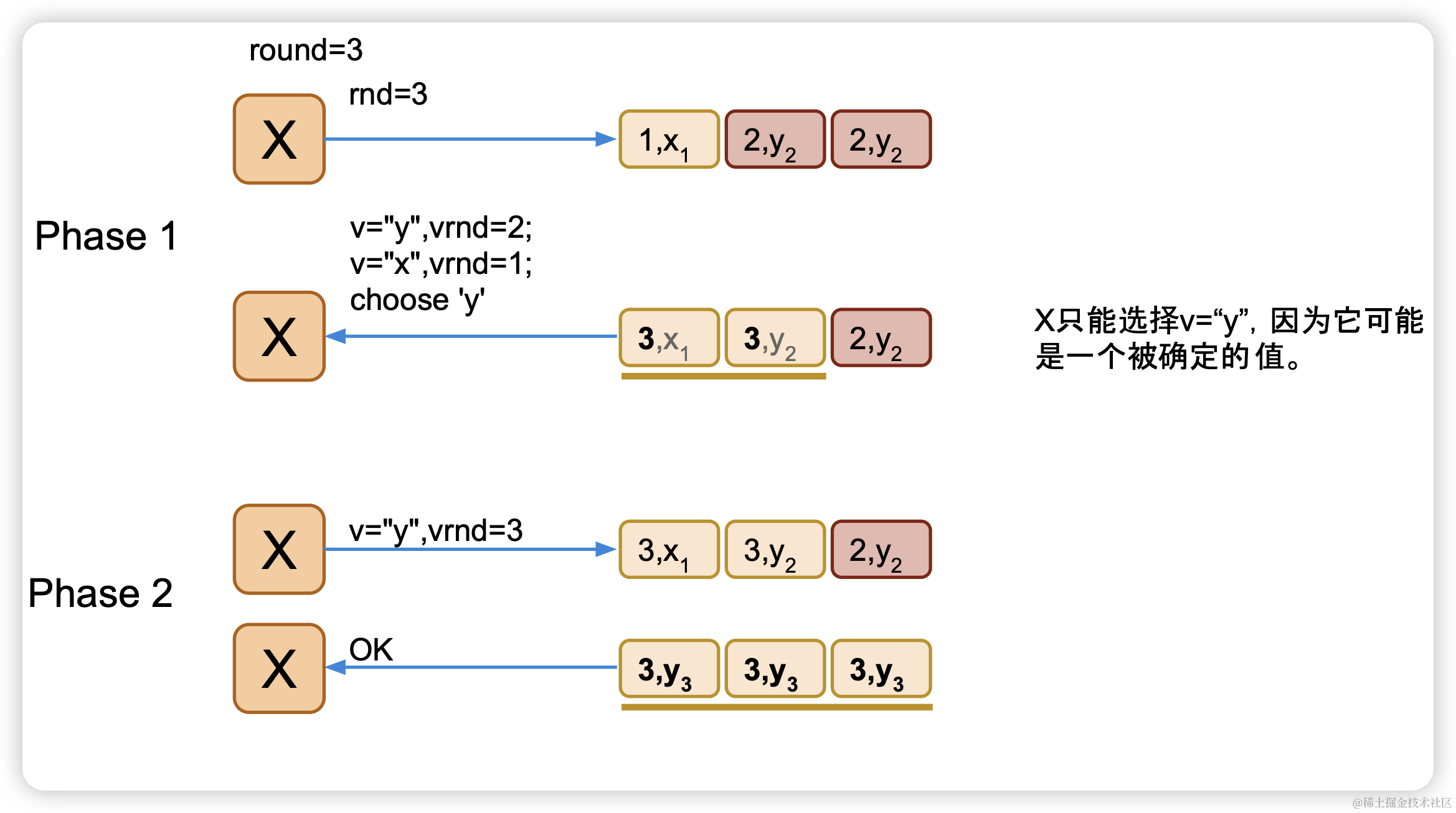
五、问题及改进
活锁(Livelock): 多个Proposer并发对1个值运行paxos的时候,可能会互 相覆盖对方的rnd,然后提升自己的rnd再次尝试,然后再次产生冲突,一直无法完成
然后后续演化各种优化:
multi-paxos:用一次rpc为多个paxos实例运行phase-1
fast-paxos : 增加quorum的数量来达到一次rpc就能达成一致的目的. 如果fast-paxos没能在一次rpc达成一致, 则要退化到classic paxos.
raft: leader, term,index等等..
六、参考
一个基于Paxos的KV存储的实现:https://github.com/openacid/paxoskv
Paxos论文:https://lamport.azurewebsites.net/pubs/paxos-simple.pdf








