推荐
专栏
教程
课程
飞鹅
本次共找到45条
scrapy
相关的信息
Irene181
•
4年前
手把手教你用Scrapy爬虫框架爬取食品论坛数据并存入数据库
大家好,我是杯酒先生,这是我第一次写这种分享项目的文章,可能很水,很不全面,而且肯定存在说错的地方,希望大家可以评论里加以指点,不胜感激!一、前言网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。百度百科 说人话就是,爬虫是用来海量规则化获取数据
Irene181
•
4年前
手把手教你用Scrapy爬虫框架爬取食品论坛数据并存入数据库
大家好,我是杯酒先生,这是我第一次写这种分享项目的文章,可能很水,很不全面,而且肯定存在说错的地方,希望大家可以评论里加以指点,不胜感激!一、前言网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。百度百科 说人话就是,爬虫是用来海量规则化获取数据
Stella981
•
4年前
Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
原文地址https://www.cnblogs.com/zhaof/p/7196197.html当Item在Spider中被收集之后,就会被传递到ItemPipeline中进行处理每个itempipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢
Stella981
•
4年前
Python之scrapy实现的爬虫,百度贴吧的自动签到和自动发帖、自动回帖
百度贴吧Crawler!Travisbranch(https://img.shields.io/travis/rustlang/rust/master.svg)(https://gitee.com/changleibox/TiebaCrawler)实现百度贴吧的自动签到和自动发帖、自动回帖实现Cookies
Python进阶者
•
3年前
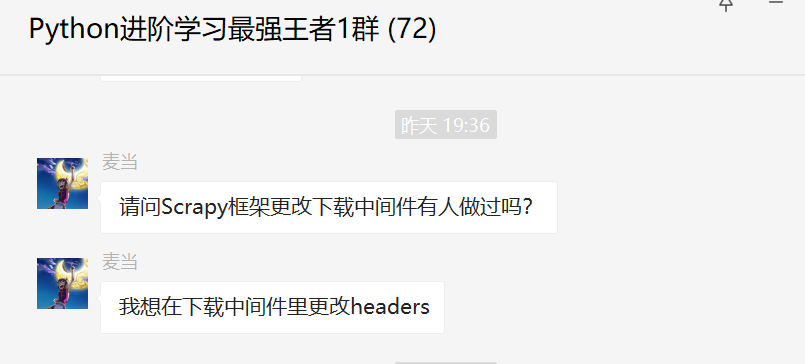
Scrapy框架中如何更改下载中间件里的headers?
大家好,我是我是皮皮。一、前言前几天在Python最强王者交流群有个叫【麦当】的粉丝问了一个关于Scrapy框架中如何更改下载中间件里的headers问题,这里拿出来给大家分享下,一起学习。二、解决过程如果只是单纯的一次性添加,那么可以使用下面这个方式,直接在settings.py文件中设置:但是他想动态的修改,这样的话,单纯的修改就有点力不从心了。不过
1
2
3
4
5