推荐
专栏
教程
课程
飞鹅
本次共找到4935条
redis持久化
相关的信息
捉虫大师
•
4年前
给dubbo贡献源码,做梦都在修bug
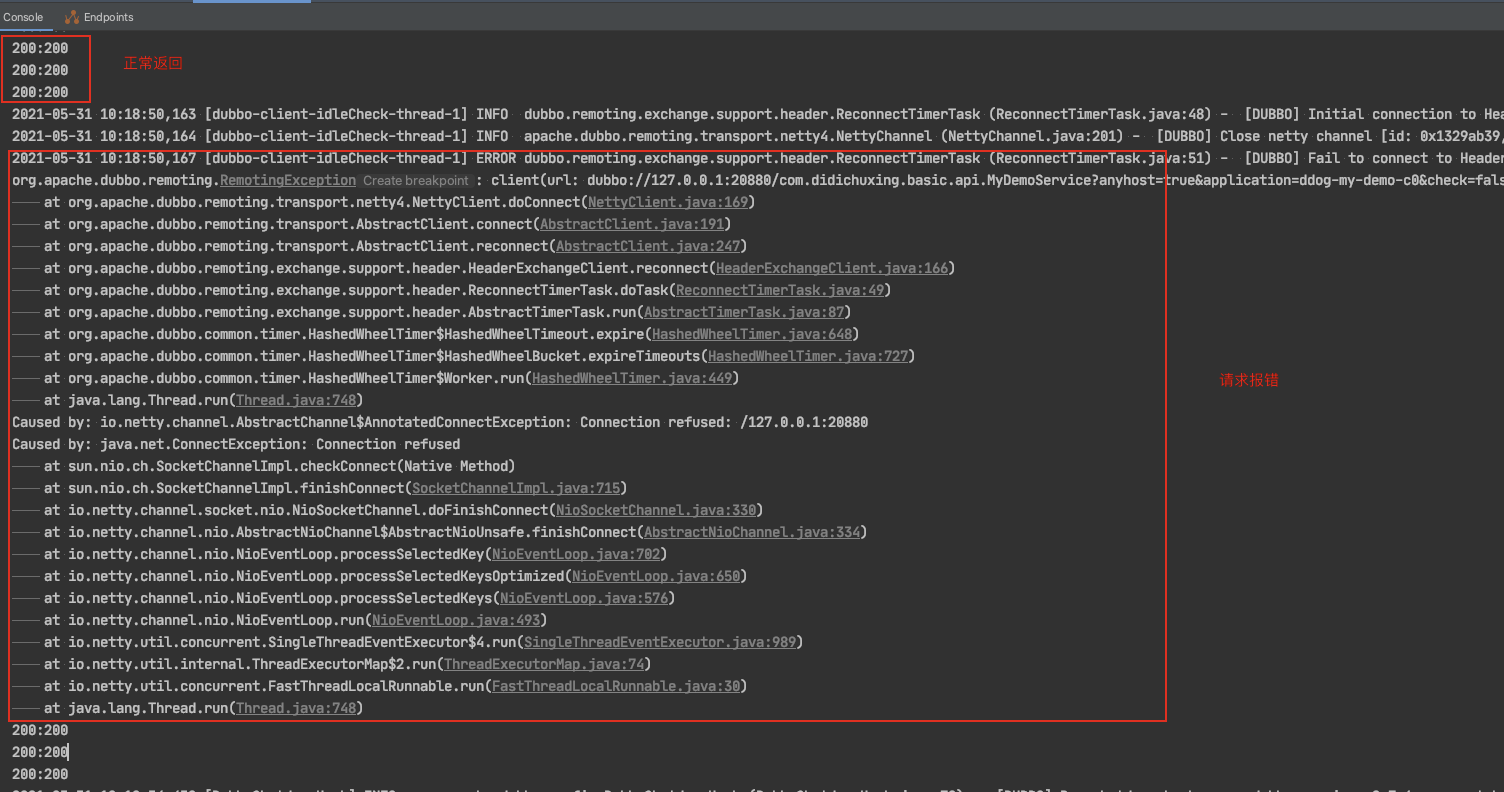
本文已收录https://github.com/lkxiaolou/lkxiaolou欢迎star。一在之前的文章《redis在微服务领域的贡献》中,从一次面试经历中了解了redis可以在微服务中玩的这么溜,同时也从源码角度分析了dubbo的redis注册中心。最后得出了dubbo的redis注册中心不能用于生产的结论,其中原因有如下两点:使用了ke
3A网络
•
3年前
原生 Redis 跨数据中心双向同步优化实践
原生Redis跨数据中心双向同步优化实践一、背景公司基于业务发展以及战略部署,需要实现在多个数据中心单元化部署,一方面可以实现多数据中心容灾,另外可以提升用户请求访问速度。需要保证多数据中心容灾或者实现用户就近访问的话,需要各个数据
Karen110
•
4年前
使用Scrapy网络爬虫框架小试牛刀
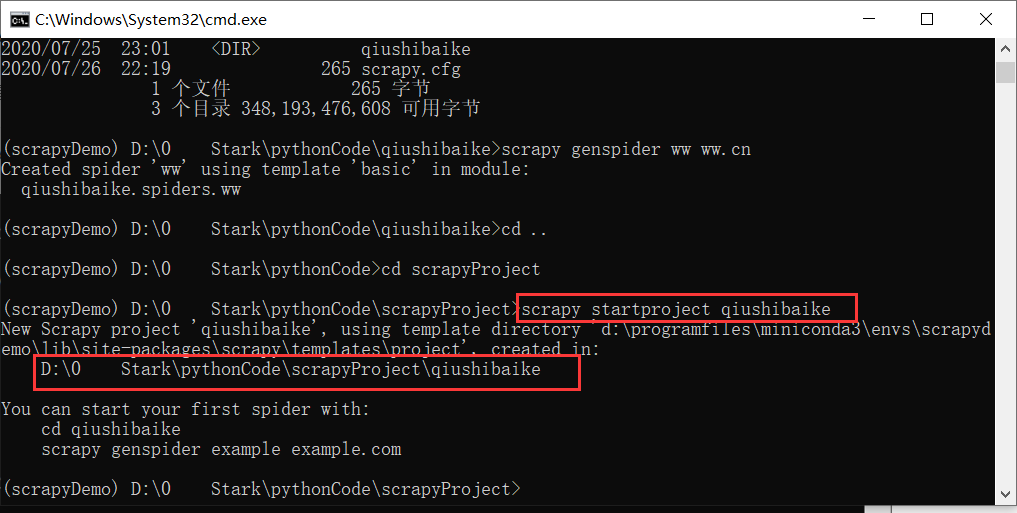
前言这次咱们来玩一个在Python中很牛叉的爬虫框架——Scrapy。scrapy介绍标准介绍Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的
Stella981
•
4年前
Kubernetes Pod的数据卷Volume
概述由于容器本身是非持久化的,因此需要解决在容器中运行应用程序遇到的一些问题。首先,当容器崩溃时,kubelet将重新启动容器,但是写入容器的文件将会丢失,容器将会以镜像的初始状态重新开始;第二,在通过一个Pod中一起运行的容器,通常需要共享容器之间一些文件。Kubernetes通过存储卷解决上述的两个问题。在Docker有存储卷的概念卷,但D
Stella981
•
4年前
Linux下安装配置Redis
1\.下载安装$wgethttp://redis.googlecode.com/files/redis2.2.12.tar.gz$tarxzfredis2.2.12.tar.gz$cdredis2.2.12$make2\.运行$src/redisserver
Stella981
•
4年前
Dubbo协议及序列化
Dubbo是Alibaba开源的分布式服务框架远程调用框架,在网络间传输数据,就需要通信协议和序列化。一通信协议Dubbo支持dubbo、rmi、hessian、http、webservice、thrift、redis等多种协议,但是Dubbo官网是推荐我们使用Dubbo协议的,默认也是用的dubbo协议。先介绍几种常见的协议:1\.
Wesley13
•
4年前
5.13redis的相关基础
二、Redis(NoSql) Redis是用C语言开发的一个开源的高性能键值对(keyvalue)数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s, 且Redis通过提供多种键值数据类型来适应不同场景下的储存需求,目前为止Redis对数据类型如下:字符串类型 Strin
Stella981
•
4年前
Redis最常被问到知识点汇总
1.什么是redis?Redis是一个基于内存的高性能keyvalue数据库。2.Reids的特点Redis本质上是一个KeyValue类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,
Stella981
•
4年前
Kafka相关内容总结(存储和性能)
Kafka消息的存储Kafka的设计基于一种非常简单的指导思想:不是要在内存中保存尽可能多的数据,在需要时将这些数据刷新(flush)到文件系统,而是要做完全相反的事情。所有数据都要立即写入文件系统中持久化的日志中,但不进行刷新数据的任何调用。实际中这样做意味着,数据被传输到OS内核的页面缓存中了,OS随后会将这些数据刷新到
Easter79
•
4年前
Springboot集成Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。支持通过Kafka服务器和消费机集群来分区消息。支持Hadoop并行数据加载。Springboot的基本搭建和配置我
1
•••
36
37
38
•••
494