推荐
专栏
教程
课程
飞鹅
本次共找到10000条
python数据挖掘
相关的信息
Python进阶者
•
4年前
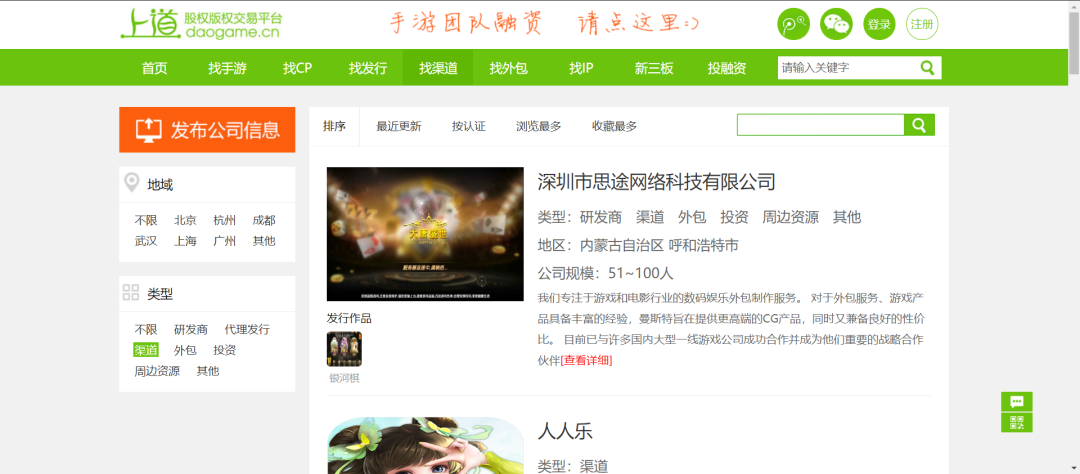
手把手教你用用Python爬取上道网的赞助公司名称
一、前言上道网是一个手游发行推荐与投融资交易平台。平台聚集手游CP、手游发行、手游渠道、手游外包,投资商以及IP授权商,IP合作、一站式服务。并为之提供合作交易机会。今天教如何去爬取上道网的赞助公司名称,方便有关人士投资。(https://imghelloworld.osscnbeijing.aliyuncs.com/dc08ff2
3A网络
•
3年前
手写 ArrayList 核心源码
手写ArrayList核心源码手写ArrayList核心源码ArrayList是Java中常用的数据结构,不光有ArrayList,还有LinkedList,HashMap,LinkedHashMap,HashSet
Karen110
•
4年前
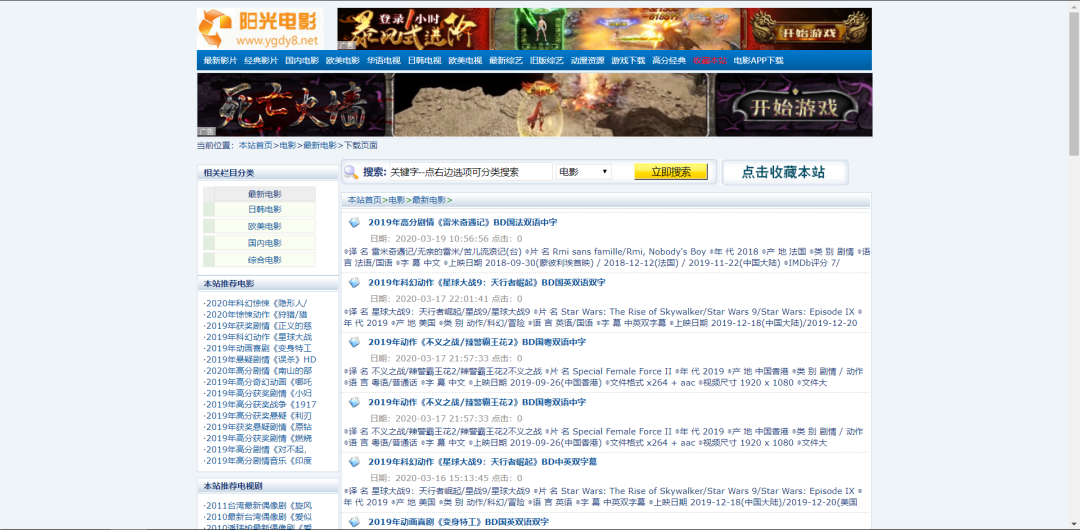
一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
【一、项目背景】相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态。今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来。【二、项目准备】首先我们第一步我们要安装一个Pycharm的软件。Pycharm软件安装可以看这篇教程:。电影天堂网的网址:https://ww
Stella981
•
4年前
LeetCode 0116. 填充每个节点的下一个右侧节点指针【Python】【Go】
ProblemLeetCode(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fleetcode.com%2Fproblems%2Fpopulatingnextrightpointersineachnode%2F)Youaregivenap
Wesley13
•
4年前
Java读取文件
1、一次性读取整个文件内容 /一次性读取全部文件数据@paramstrFile/publicstaticvoidreadFile(StringstrFile){try{InputStr
Stella981
•
4年前
Spark Connector Reader 原理与实践
!nebulasparkconnectorreader(https://wwwcdn.nebulagraph.com.cn/nebulablog/Draft/nebulasparkconnectorreader.png)本文主要讲述如何利用SparkConnector进行NebulaGraph数据的读取。Spark
Stella981
•
4年前
ShardingSphere 4.x Sharding
配置示例数据分片dataSources:ds0:!!org.apache.commons.dbcp.BasicDataSourcedriverClassName:com.mysql.jdbc.Driverurl:jdbc:mysql://localhost:3306/d
Wesley13
•
4年前
mysql 判断索引是否存在,存在则删除再创建索引(分表) 存储过程
1.分表5数据量大,执行所有分表修改,不包括5CREATEPROCEDUREdeleteIndex()BEGINDECLAREcorpIdCHAR(16);DECLAREflagINTDEFAULTFALSE;DECLAREcurCURSORFORSELECTidFROMgpsbuzdb.gps\_c
Stella981
•
4年前
Python之路(第二十八篇) 面向对象进阶:类的装饰器、元类
一、类的装饰器类作为一个对象,也可以被装饰。例子defwrap(obj):print("装饰器")obj.x1obj.y3obj.z5returnobj
Stella981
•
4年前
Excel公式太复杂?我花一晚上用Python做了个格式化工具
1
•••
645
646
647
•••
1000